Information overload is a significant challenge for many organizations and individuals today. It can be overwhelming to keep up with incoming chat messages and documents that arrive at our inbox everyday. This has been exacerbated by the increase in virtual work and remains a challenge as many teams transition to a hybrid work environment with a mix of those working both virtually and in an office. One solution that can address information overload is summarization — for example, to help users improve their productivity and better manage so much information, we recently introduced auto-generated summaries in Google Docs.
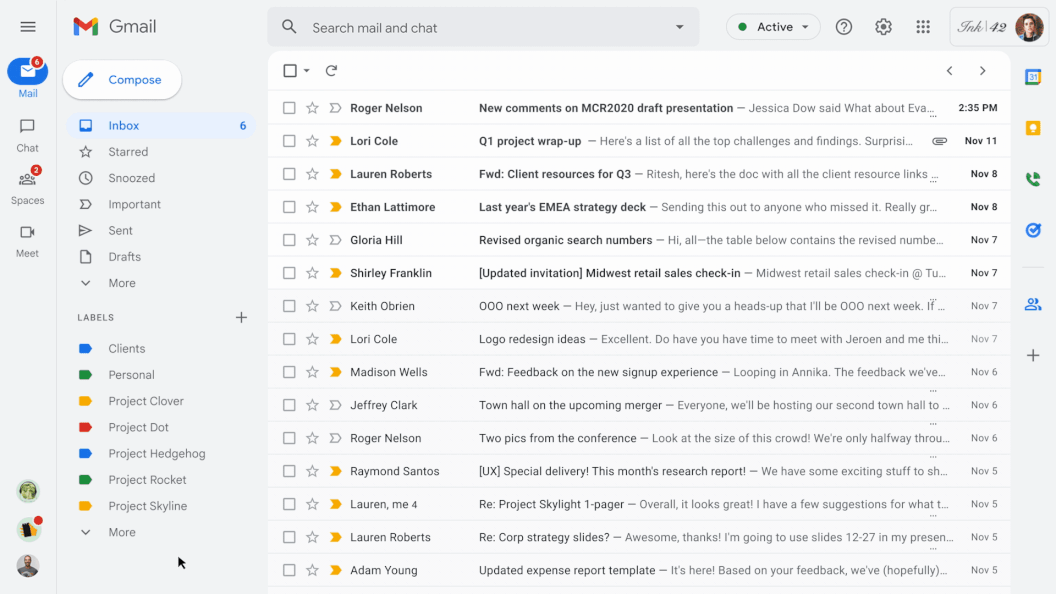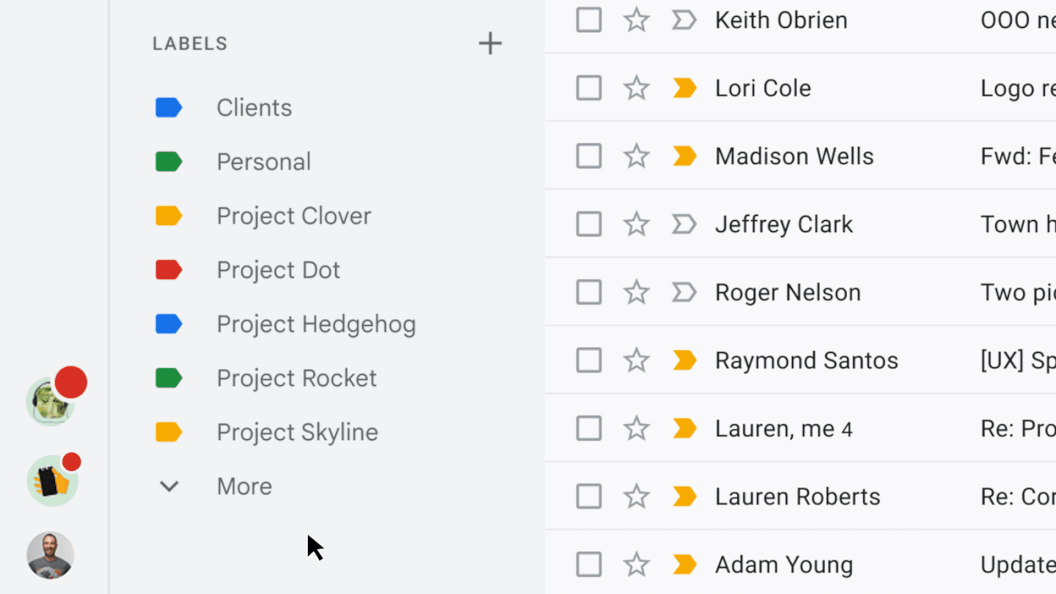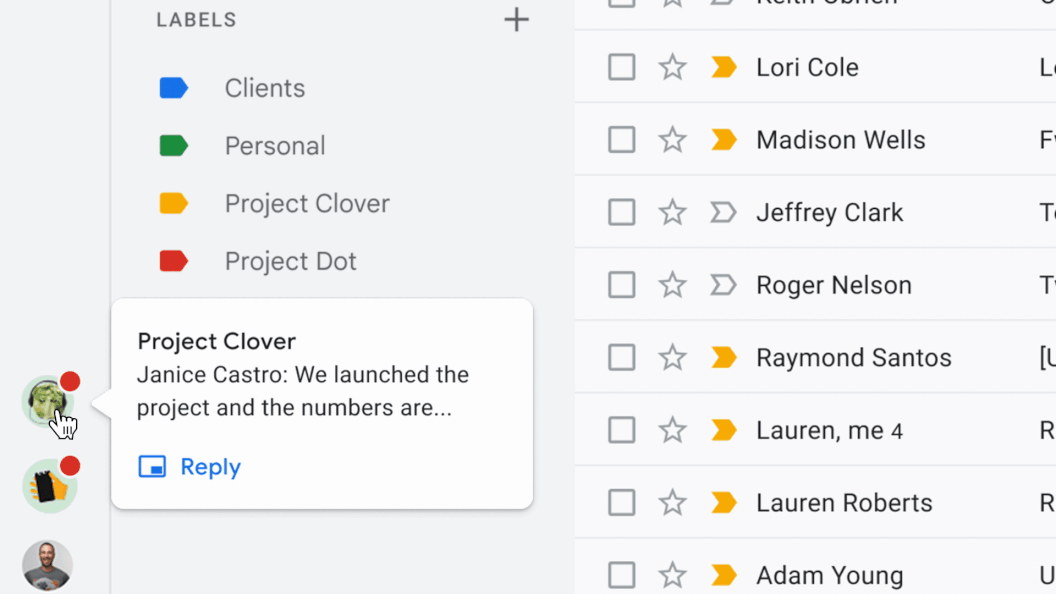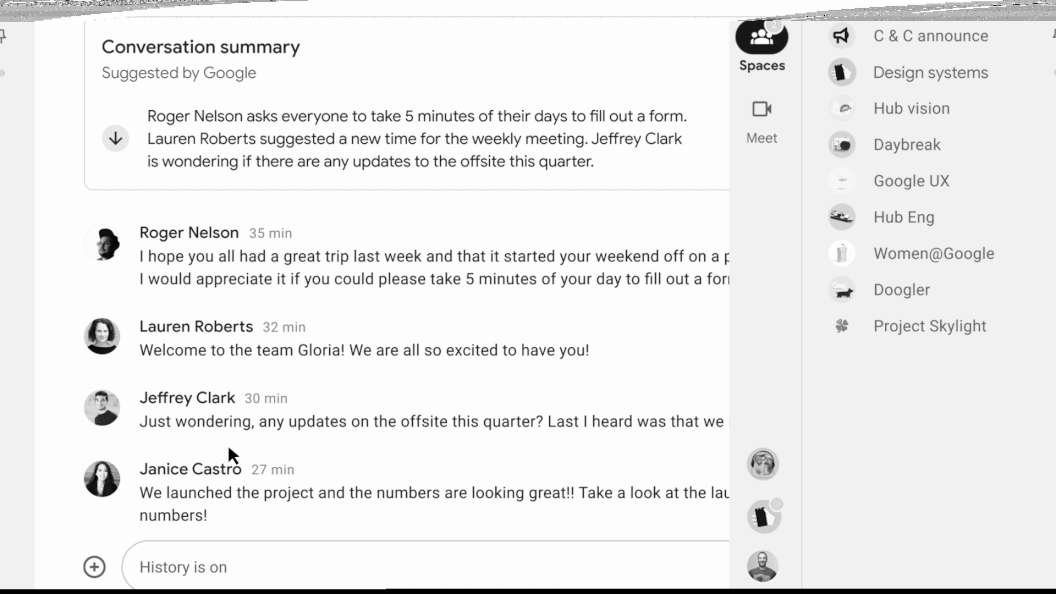
Today, we are excited to introduce conversation summaries in Google Chat for messages in Spaces. When these summaries are available, a card with automatically generated summaries is shown as users enter Spaces with unread messages. The card includes a list of summaries for the different topics discussed in Spaces. This feature is enabled by our state-of-the-art abstractive summarization model, Pegasus, which generates useful and concise summaries for chat conversations, and is currently available to selected premium Google Workspace business customers.
 |
| Conversation summaries provide a helpful digest of conversations in Spaces, allowing users to quickly catch-up on unread messages and navigate to the most relevant threads. |
Conversation Summarization Modeling
The goal of text summarization is to provide helpful and concise summaries for different types of text, such as documents, articles, or spoken conversations. A good summary covers the key points succinctly, and is fluent and grammatically correct. One approach to summarization is to extract key parts from the text and concatenate them together into a summary (i.e., extractive summarization). Another approach is to use natural language generation (NLG) techniques to summarize using novel words and phrases not necessarily present in the original text. This is referred to as abstractive summarization and is considered closer to how a person would generally summarize text. A main challenge with abstractive summarization, however, is that it sometimes struggles to generate accurate and grammatically correct summaries, especially in real world applications.
ForumSum Dataset
The majority of abstractive summarization datasets and research focuses on single-speaker text documents, like news and scientific articles, mainly due to the abundance of human-written summaries for such documents. On the other hand, datasets of human-written summaries for other types of text, like chat or multi-speaker conversations, are very limited.
To address this we created ForumSum, a diverse and high-quality conversation summarization dataset with human-written summaries. The conversations in the dataset are collected from a wide variety of public internet forums, and are cleaned up and filtered to ensure high quality and safe content (more details in the paper).
 |
| An example from the ForumSum dataset. |
Each utterance in the conversation starts on a new line, contains an author name and a message text that is separated with a colon. Human annotators are then given detailed instructions to write a 1-3 sentence summary of the conversation. These instructions went through multiple iterations to ensure annotators wrote high quality summaries. We have collected summaries for over six thousand conversations, with an average of more than 6 speakers and 10 utterances per conversation. ForumSum provides quality training data for the conversation summarization problem: it has a variety of topics, number of speakers, and number of utterances commonly encountered in a chat application.
Conversation Summarization Model Design
As we have written previously, the Transformer is a popular model architecture for sequence-to-sequence tasks, like abstractive summarization, where the inputs are the document words and the outputs are the summary words. Pegasus combined transformers with self-supervised pre-training customized for abstractive summarization, making it a great model choice for conversation summarization. First, we fine-tune Pegasus on the ForumSum dataset where the input is the conversation words and the output is the summary words. Second, we use knowledge distillation to distill the Pegasus model into a hybrid architecture of a transformer encoder and a recurrent neural network (RNN) decoder. The resulting model has lower latency and memory footprint while maintaining similar quality as the Pegasus model.
Quality and User Experience
A good summary captures the essence of the conversation while being fluent and grammatically correct. Based on human evaluation and user feedback, we learned that the summarization model generates useful and accurate summaries most of the time. But occasionally the model generates low quality summaries. After looking into issues reported by users, we found that there are two main types of low quality summaries. The first one is misattribution, when the model confuses which person or entity said or performed a certain action. The second one is misrepresentation, when the model’s generated summary misrepresents or contradicts the chat conversation.
To address low quality summaries and improve the user experience, we have made progress in several areas:
- Improving ForumSum: While ForumSum provides a good representation of chat conversations, we noticed certain patterns and language styles in Google Chat conversations that differ from ForumSum, e.g., how users mention other users and the use of abbreviations and special symbols. After exploring examples reported by users, we concluded that these out-of-distribution language patterns contributed to low quality summaries. To address this, we first performed data formatting and clean-ups to reduce mismatches between chat and ForumSum conversations whenever possible. Second, we added more training data to ForumSum to better represent these style mismatches. Collectively, these changes resulted in reduction of low quality summaries.
- Controlled triggering: To make sure summaries bring the most value to our users, we first need to make sure that the chat conversation is worthy of summarization. For example, we found that there is less value in generating a summary when the user is actively engaged in a conversation and does not have many unread messages, or when the conversation is too short.
- Detecting low quality summaries: While the two methods above limited low quality and low value summaries, we still developed methods to detect and abstain from showing such summaries to the user when they are generated. These are a set of heuristics and models to measure the overall quality of summaries and whether they suffer from misattribution or misrepresentation issues.
Finally, while the hybrid model provided significant performance improvements, the latency to generate summaries was still noticeable to users when they opened Spaces with unread messages. To address this issue, we instead generate and update summaries whenever there is a new message sent, edited or deleted. Then summaries are cached ephemerally to ensure they surface smoothly when users open Spaces with unread messages.
Conclusion and Future Work
We are excited to apply state-of-the-art abstractive summarization models to help our Workspace users improve their productivity in Spaces. While this is great progress, we believe there are many opportunities to further improve the experience and the overall quality of summaries. Future directions we are exploring include better modeling and summarizing entangled conversations that include multiple topics, and developing metrics that better measure the factual consistency between chat conversations and summaries.
Acknowledgements
The authors would like to thank the many people across Google that contributed to this work: Ahmed Chowdhury, Alejandro Elizondo, Anmol Tukrel, Benjamin Lee, Chao Wang, Chris Carroll, Don Kim, Jackie Tsay, Jennifer Chou, Jesse Sliter, John Sipple, Kate Montgomery, Maalika Manoharan, Mahdis Mahdieh, Mia Chen, Misha Khalman, Peter Liu, Robert Diersing, Sarah Read, Winnie Yeung, Yao Zhao, and Yonghui Wu.