Posted by Anusha Ramesh, Product Manager TFX, David Zats, Software Engineer TFX, Ping Yu, Software Engineer TensorFlow.js, Lamtharn (Hanoi) Hantrakul, AI Resident Magenta
Introduction
Sounds of India is a unique and fun interactive musical experience launching for India’s 74th Independence Day, inspired by Indian tradition and powered by machine learning. When users throughout India (and around the world) sing the Indian National Anthem into the microphone of their mobile devices, machine learning models transform their voices into a range of classical Indian musical instruments live in the browser. The entire process of creating this experience took only 12 weeks, showing how rapidly developers can take models from research to production at scale using the TensorFlow Ecosystem. 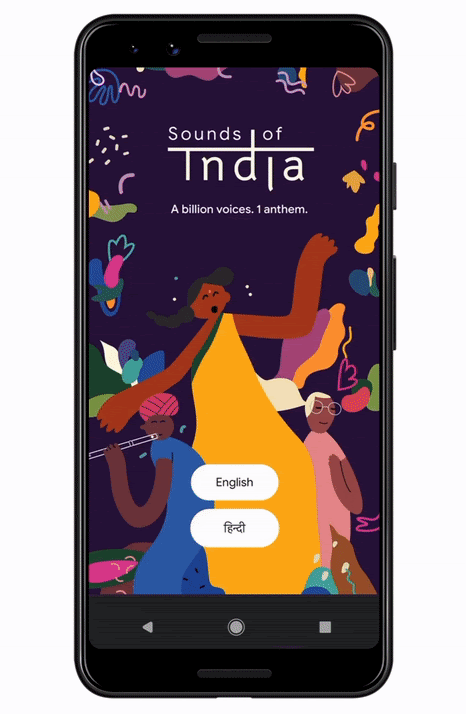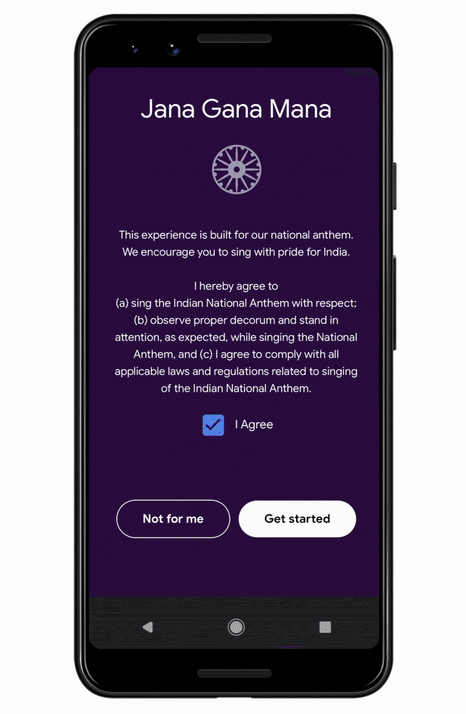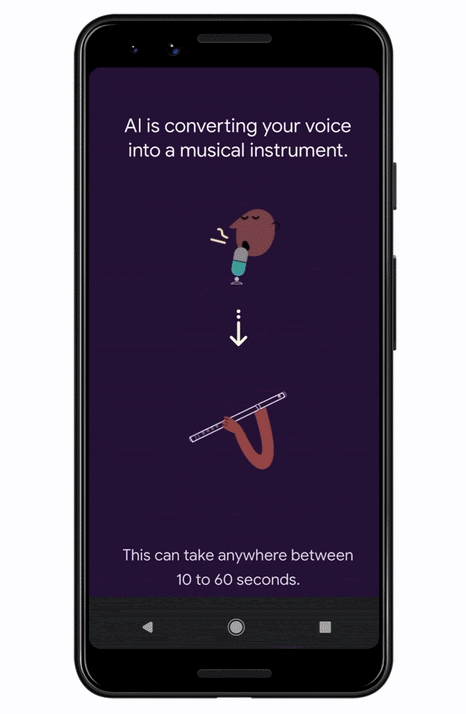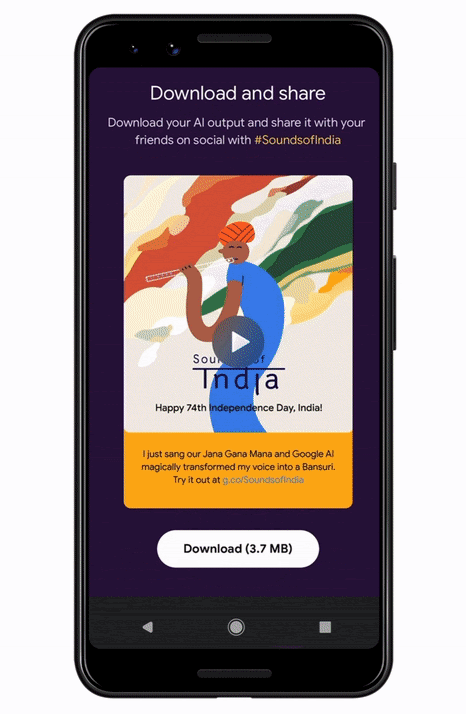
The Research: Magenta’s Differentiable Digital Signal Processing (DDSP)
Magenta is an open source research project within Google AI exploring the role of machine learning in the creative process. Differentiable Digital Signal Processing or DDSP is a new open source library fusing modern machine learning with interpretable signal processing. Instead of training a pure deep learning model like WaveNet to render waveforms sample-by-sample, we can train lightweight models that output time varying control signals into these differentiable DSP modules (hence the extra “D” in DDSP) which synthesize the final sound. Both recurrent and convolutional models incorporating DDSP in TensorFlow Keras layers can efficiently generate audio 1000 times faster than their larger autoregressive counterparts, with 100x reduction in model parameters and training data requirements. One particularly fun application of DDSP is Tone Transfer, which transforms sounds into musical instruments. Try it by first training a DDSP model on 15 minutes of a target saxophone. You can then sing a melody and the trained DDSP model will re-render it as a saxophone. For Sounds of India, we applied this technology to three classical Indian instruments: the Bansuri, the Shehnai, and the Sarangi. 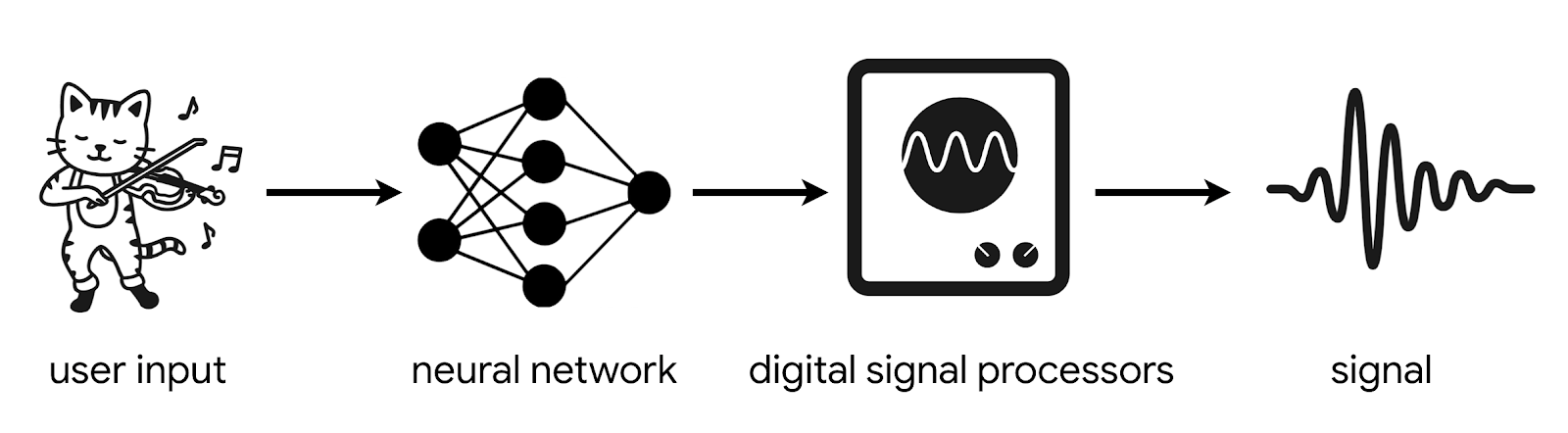
Train with TFX, deploy to the browser with TensorFlow.js
TFX
TensorFlow Extended (TFX) is an end-to-end platform for production ML, which includes preparing data, training, validating, and deploying models in production environments. TFX was used to train the models responsible for transforming the user’s voice to one of the instruments, and these models were then converted to TensorFlow.js for deployment on a standard Web browser.
Deploying to the browser provides a seamless experience for users to interact with the machine learning model: simply click a hyperlink and load the page just like any other website. No complicated installs necessary. By executing client side in the browser, we are able to perform inference right at the source of the sensor data, minimising latency and reducing server costs associated with large graphics cards, CPU, and memory. Moreover, given the application uses your voice as input, user privacy is quite important. Since the entire end-to-end experience happens client-side and in the browser, absolutely no sensor or microphone data is sent to the server side.
Browser-based machine learning models are often optimized to be as small as possible to minimize bandwidth used. In this case, the ideal hyperparameters for each musical instrument can also vary drastically. We leveraged TFX to perform large-scale training and tuning over hundreds of models to determine the smallest size for each instrument. As a result, we were able to dramatically reduce their memory footprints. For example, the Bansuri instrument model had a reduction in its on-disk size of ~20x without a noticeable impact on sound quality.
TFX also empowered us to perform rapid iteration over different model architectures (GRU, CNN), different types of inputs (loudness, RMS energy), and varying musical instrument data sources. Each time, we were able to quickly and effectively run the TFX pipeline to produce a new model with the desired characteristics.
TensorFlow.js
Creating a TensorFlow.js DDSP model was uniquely challenging because of the need to hit tight performance and model quality targets. We needed the model to be highly efficient at performing tone transfer so that it could effectively run on mobile devices. At the same time, any degradation in model quality would quickly lead to audio distortions and a poor user experience.
We started by exploring a wide range of TensorFlow.js backends and model architectures. The WebGL backend is the most optimized, while the WebAssembly backend works well on low end phones. Given the computational requirements of DDSP, we settled on a Convnet-based DDSP model and leveraged the WebGL backend.
To minimize the model download time, we studied the topology of the model, and compressed a large set of constant tensors with Fill/ZeroLike ops, which reduced the size from 10MB to 300KB.
We also focused on three key areas to make the TensorFlow.js model ready for production scale deployment on devices: inference performance, memory footprint, and numerical stability.
Inference Performance Optimization
DDSP models contain both a neural network and a signal synthesizer. The synthesizer part has many signal processing ops that require large amounts of computation. To improve performance on mobile devices, we re-wrote several kernels with special WebGL shaders to fully utilize the GPU. For example, a parallel version of the cumulative summation op reduced inference time by 90%.
Reduce memory footprint
Our goal is to be able to run the model on as many types of mobile devices as possible. Since many phones have very limited GPU memory, we need to make sure that model has a minimal memory footprint. We achieve this by disposing of intermediate tensors and adding a new flag to allow early disposal of GPU textures. Through these approaches we were able to reduce memory size by 60%.
Numerical stability
The DDSP model requires very high numerical precision in order to generate beautiful music. This is quite different from typical classification models, where a certain level of precision loss does not affect the final classifications. DDSP models used in this experience are generative models. Any loss in precision and discontinuities in the audio output are easily picked up by our sensitive ears. We encountered numerical stability problems with float16 WebGL texture. We therefore rewrote some of the key ops to reduce the overflow and underflow of the outputs. For example, in the Cumulative Summation op, we make sure cumulation is done within the shader with full float precision, and apply modulo calculation to avoid overflow before we write the output to a float16 texture.
Try it yourself!
You can try out the experience on your mobile phone at g.co/SoundsofIndia – and please share your results with us if you wish. We would love to see what you create with your voice.
If you are excited about how machine learning can augment creativity and innovation, you can learn more about Magenta through the team’s blog and contribute to their open source github, or check out #MadeWithTFJS for even more examples of browser-based machine learning from the TensorFlow.js community. If you are interested in training and deploying models at production scale using ML best practices, check out the Tensorflow Extended blog.
Acknowledgements
This project wouldn’t have been possible without the incredible effort of Miguel de Andrés-Clavera, Yiling Liu, Aditya Mirchandani, KC Chung, Alap Bharadwaj, Kiattiyot (Boon) Panichprecha, Pittayathorn (Kim) Nomrak, Phatchara (Lek) Pongsakorntorn, Nattadet Chinthanathatset, Hieu Dang, Ann Yuan, Sandeep Gupta, Chong Li, Edwin Toh, Jesse Engel and additional help from Michelle Carney, Nida Zada, Doug Eck, Hannes Widsomer and Greg Mikels. Huge thanks to Tris Warkentin and Mitch Trott for their tremendous support.
Read More