
Last year, Meta announced that PyTorch joined the Linux Foundation as a neutral home for growing the machine learning project and community with AMD representation as a part of the founding membership and governing board.
PyTorch Foundation’s mission is to drive AI adoption by democratizing its software ecosystem through open source principles aligning with the AMD core principle of an Open software ecosystem. AMD strives to foster innovation through the support for latest generations of hardware, tools, libraries, and other components to simplify and accelerate adoption of AI across a broad range of scientific discoveries.
AMD, along with key PyTorch codebase developers (including those at Meta AI), delivered a set of updates to the ROCm™ open software ecosystem that brings stable support for AMD Instinct™ accelerators as well as many Radeon™ GPUs. This now gives PyTorch developers the ability to build their next great AI solutions leveraging AMD GPU accelerators & ROCm. The support from PyTorch community in identifying gaps, prioritizing key updates, providing feedback for performance optimizing and supporting our journey from “Beta” to “Stable” was immensely helpful and we deeply appreciate the strong collaboration between the two teams at AMD and PyTorch. The move for ROCm support from “Beta” to “Stable” came in the PyTorch 1.12 release (June 2022) brings the added support to easily run PyTorch on native environment without having to configure custom dockers. This is a sign of confidence about the quality of support and performance of PyTorch using AMD Instinct and ROCm. The results of these collaborative efforts are evident in the performance measured on key industry benchmarks like Microsoft’s SuperBench shown below in Graph 1.
“We are excited to see the significant impact of developers at AMD to contribute to and extend features within PyTorch to make AI models run in a more performant, efficient, and scalable way. A great example of this is the thought-leadership around unified memory approaches between the framework and future hardware systems, and we look forward to seeing that feature progress.”
– Soumith Chintala, PyTorch lead-maintainer and Director of Engineering, Meta AI
The progressive improvements on both the AMD CDNA™ architecture as well as ROCm and PyTorch shows single GPU model throughput increase from AMD Instinct MI100 to the latest generation AMD Instinct MI200 family GPUs going from ROCm 4.2 to ROCm 5.3 and from PyTorch 1.7 to PyTorch 1.12.
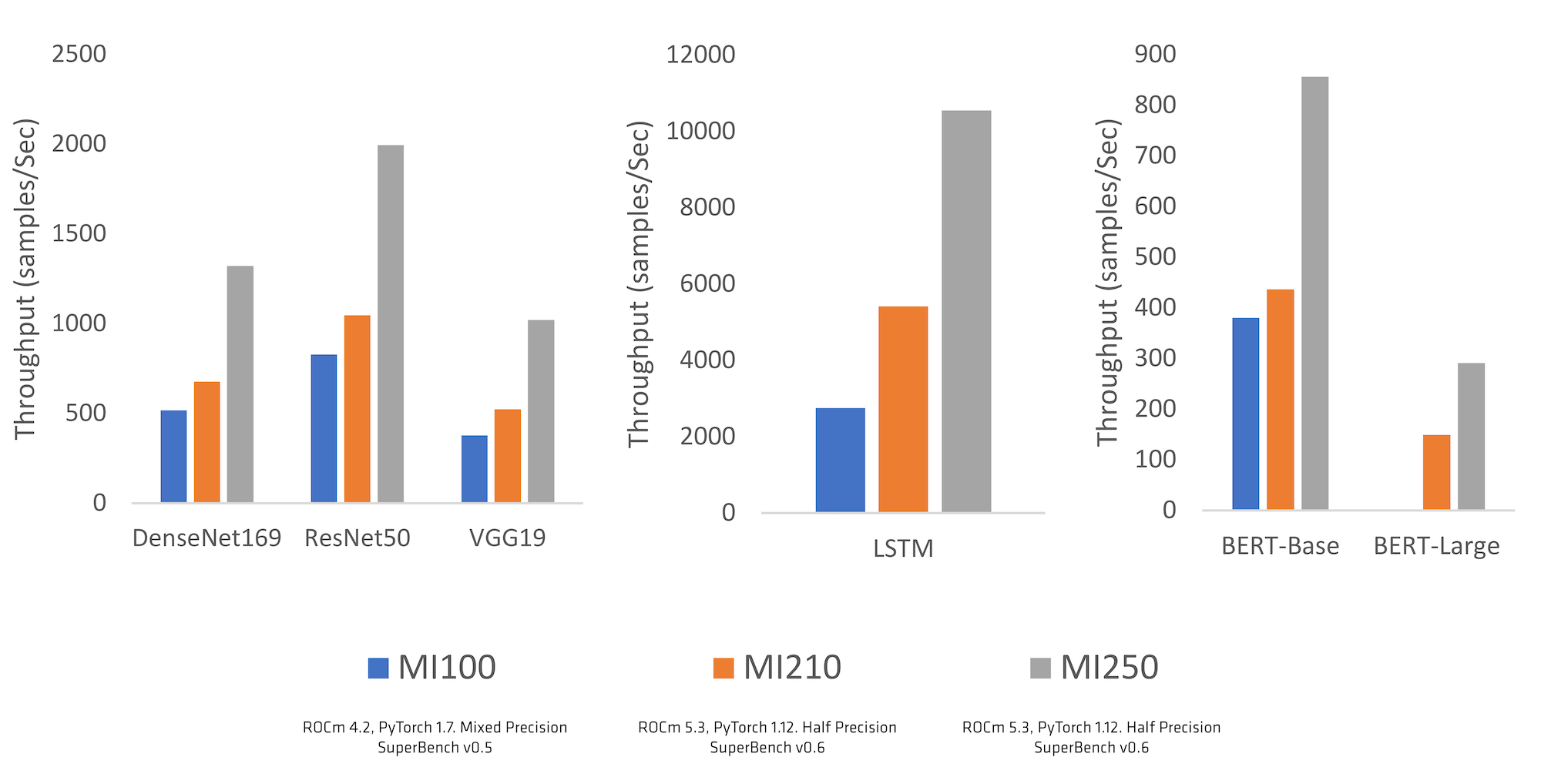
Graph 1: ML model performance over generation using Microsoft Superbench Suite 1, 2, 3
Below are a few of the key updates for ROCm support since the PyTorch 1.12 release
Full Continuous Integration (CI) for ROCm on PyTorch
With the ROCm support for PyTorch move from “Beta” to “Stable,” all the functions and features commits are now verified through a full Continuous Integration (CI) process. The CI process helps ensure the proper build and test process ahead of an expected Docker and PIP wheel release with stable commits forthcoming.
Support for Kineto Profiler
The addition of Kineto profiler support to ROCm now helps developers and users understand performance bottlenecks through effective diagnosis and profiling tools. The tool also provides recommendations to improve known issues and visualization through TensorBoard UI.
Key PyTorch Libraries support added
PyTorch ecosystem libraries like TorchText (Text classification), TorchRec (libraries for recommender systems – RecSys), TorchVision (Computer Vision), TorchAudio (audio and signal processing) are fully supported since ROCm 5.1 and upstreamed with PyTorch 1.12.
Key libraries provided with the ROCm software stack including MIOpen (Convolution models), RCCL (ROCm Collective Communications) and rocBLAS (BLAS for transformers) were further optimized to offer new potential efficiencies and higher performance.
MIOpen innovates on several fronts, such as implementing fusion to optimize for memory bandwidth and GPU launch overheads, providing an auto-tuning infrastructure to overcome the large design space of problem configurations, and implementing different algorithms to optimize convolutions for different filter and input sizes. MIOpen is one of the first libraries to publicly support the bfloat16 data-type for convolutions, allowing efficient training at lower precision maintaining expected accuracy.
RCCL (pronounced “Rickle”) is a stand-alone library of standard collective communication routines for GPUs, implementing all-reduce, all-gather, reduce, broadcast, reduce-scatter, gather, scatter, and all-to-all. There is support for direct GPU-to-GPU send and receive operations. It has been optimized to achieve high bandwidth on platforms using PCIe®, Infinity Fabric™ (GPU to GPU) as well as networking using InfiniBand Verbs or TCP/IP sockets. RCCL supports an arbitrary number of GPUs installed in single or multiple nodes and can be used in either single- or multi-process (e.g., MPI) applications.
Along with the above key highlights, over 50 features and functionality improvements were completed jointly between AMD and PyTorch to add stable support for ROCm. These include improvements to tools, compilers, runtime, graph optimizations through TorchScript, INT8 quant path usage, and ONNX runtime integration including support for Navi 21 based Radeon™ PRO datacenter graphics card to name a few.
AITemplate Inference Engine
MetaAI recently published a blog announcing the release of its open source AITemplate (link) for a unified inference system supporting AMD Instinct GPU accelerators using the AMD ROCm stack. This Python based framework can help significantly improve performance through increased utilization of AMD matrix cores for transformer blocks. This is achieved through the AMD Composable Kernel (CK) library which provides performance critical Kernels for ML AI workloads across multiple architectures including GPUs and CPUs through HIP & C++.
Moreover, the AITemplate also provides out-of-the-box support for widely used AI models like BERT, ResNET, Vision Transformer, Stable Diffusion etc. simplifying deployment process through these pretrained models.
What’s coming with future ROCm releases?
Unified memory models for CPU + GPU
As system architecture evolves to address the complexity of large problem sizes and data sets, memory management becomes a key performance bottle neck that needs a cohesive strategy to be addressed through innovations at both hardware and software levels. AMD is uniquely positioned to address this problem with its effective data center solutions integrating AMD EPYC™ CPU cores with its AMD Instinct GPU compute units in a truly unified datacenter APU (Accelerated Processing Unit) form factor set to be launched in 2H 2023.
The software work to leverage the unified CPU + GPU memory has already started in collaboration with the PyTorch team, to enable the usage of a fast, low latency, synchronized memory model that enables not only AMD but also other AI accelerators to address the complex memory management problem of today. We are looking forward to this joint effort and announcement soon.
Acknowledgement
The content in this blog highlights the joint work between AMD and key PyTorch contributors including Meta, working on many of the core features, as well as Microsoft enabling ONNX Runtime support. We are looking forward to working with the other founding members at the PyTorch Foundation on the next steps and improvements to democratize and grow adoption of PyTorch across the industry.
CAUTIONARY STATEMENT
This blog contains forward-looking statements concerning Advanced Micro Devices, Inc. (AMD) such as the availability, timing and expected benefits of an AMD datacenter APU form factor, which are made pursuant to the Safe Harbor provisions of the Private Securities Litigation Reform Act of 1995. Forward-looking statements are commonly identified by words such as “would,” “may,” “expects,” “believes,” “plans,” “intends,” “projects” and other terms with similar meaning. Investors are cautioned that the forward-looking statements in this blog are based on current beliefs, assumptions and expectations, speak only as of the date of this blog and involve risks and uncertainties that could cause actual results to differ materially from current expectations. Such statements are subject to certain known and unknown risks and uncertainties, many of which are difficult to predict and generally beyond AMD’s control, that could cause actual results and other future events to differ materially from those expressed in, or implied or projected by, the forward-looking information and statements. Investors are urged to review in detail the risks and uncertainties in AMD’s Securities and Exchange Commission filings, including but not limited to AMD’s most recent reports on Forms 10-K and 10-Q. AMD does not assume, and hereby disclaims, any obligation to update forward-looking statements made in this blog, except as may be required by law.
Endnotes
- MI100D-01 SuperBench v0.5 model training results based on AMD internal testing as of 11/09/2022 measuring the total training throughput, at half precision, using a 2P AMD EPYC™ 7763 CPU server tested with 1x AMD Instinct™ MI100 (32GB HBM2e) 300W GPU, SBIOS 2.2, Ubuntu® 20.04.5 LTS, host ROCm™ 5.2.0, guest ROCm 4.2, PyTorch 1.7.0. Server manufacturers may vary configurations, yielding different results. Performance may vary based factors including use of latest drivers and optimizations.
- MI200D-01 SuperBench v0.6 model training results based on AMD internal testing as of 11/09/2022 measuring the total training throughput, at half precision, using a 2P AMD EPYC™ 7763 CPU server tested with 1x AMD Instinct™ MI210 (64GB HBM2e) 300W GPU, SBIOS 2.2, Ubuntu 20.04.5 LTS, host ROCm 5.3.0, guest ROCm 5.3, PyTorch 1.12. Server manufacturers may vary configurations, yielding different results. Performance may vary based factors including use of latest drivers and optimizations.
- MI200D-02: SuperBench v0.6 model training results based on AMD internal testing as of 11/09/2022 measuring the total training throughput, at half precision, using a 2P AMD EPYC™️ 7763 CPU server tested with 1x AMD Instinct™️ MI250 (128GB HBM2e) 560W GPU, SBIOS M12, Ubuntu 20.04 LTS, host ROCm 5.3.0, guest ROCm 5.3, PyTorch 1.12. Server manufacturers may vary configurations, yielding different results. Performance may vary based factors including use of latest drivers and optimizations.