TL;DR
NJTs (Nested Jagged Tensors) boost DRAMA model inference efficiency by 1.7x-2.3x, making it more production-ready in the category of LLM-based encoders, especially with variable-length sequences.
Introduction and Context
Recent advancements in Large Language Model (LLM) based encoders have shown promising results, with many models topping the evaluations leaderboard. However, the challenge lies in productionizing these complex models, which often require significant computational resources and infrastructure.
To tackle the challenge of optimizing LLaMA-based encoders, we have chosen to explore DRAMA, a dense retrieval model that leverages a pruned LLaMA backbone. The DRAMA model overall shows good performance across various versions, including base (0.1B), large (0.3B), and 1B. Specifically, DRAMA-base stands out due to its strong performance in both English and multilingual retrieval tasks, despite its compact size of 0.1B non-embedding parameters. Its quality makes it an attractive option for clients. However, the high cost associated with its implementation posed a barrier to widespread adoption. To address this challenge, we explore the use of Nested Tensors to optimize the model further to make it a viable solution for production environments.
By leveraging Nested tensors, we have observed a substantial improvement in inference efficiency for the DRAMA model, with gains ranging from 1.7 to 2.3 times greater efficiency. This breakthrough has significant implications for the deployment of LLM-based encoders in real-world applications.
What are NJTs
Sample packing in torchtune, Ragged tensors in TensorFlow, Unpadding in ModernBert and Nested Tensors in Pytorch each tackle the challenge of variable-length sequence data, but with differing approaches. While all aim to streamline sequence modeling, their abstractions and performance impact vary by framework and use case.
PyTorch’s Nested tensors are a subclass of Python tensors that offer a unified interface for handling ragged-shaped data through an efficient packed internal representation.
There are two types of nested tensors in PyTorch, distinguished by their construction layout: `torch.strided` or `torch.jagged`. It is recommended to use the Jagged layout nested tensors (NJTs), and that is what this blog focuses on as well. It’s worth noting that due to being implemented fully in Python, NJTs have some amount of eager overhead, more visible on smaller input sizes. It is recommended to compile NJTs when possible to eliminate this overhead and also gain performance through operator fusion.
A NJT tensor can be created by passing a list of tensors to `torch.nested.nested_tensor` with the `layout=torch.jagged` argument. This copies inputs into a packed, contiguous memory block. NJTs currently support a single ragged dimension.
Model deployments benefit from Nested Tensors when they typically perform inference on large batches of sequences with varying lengths. Given such a query pattern, inference with regular tensors requires that all sequences in the batch be padded to the same length, which is particularly wasteful when the batch consists of many short sequences and a single long sequence. In contrast, Nested Tensors avoid wasting compute on these extra pad tokens by natively supporting operations on batches of varying sequence length.
Dense vs Jagged
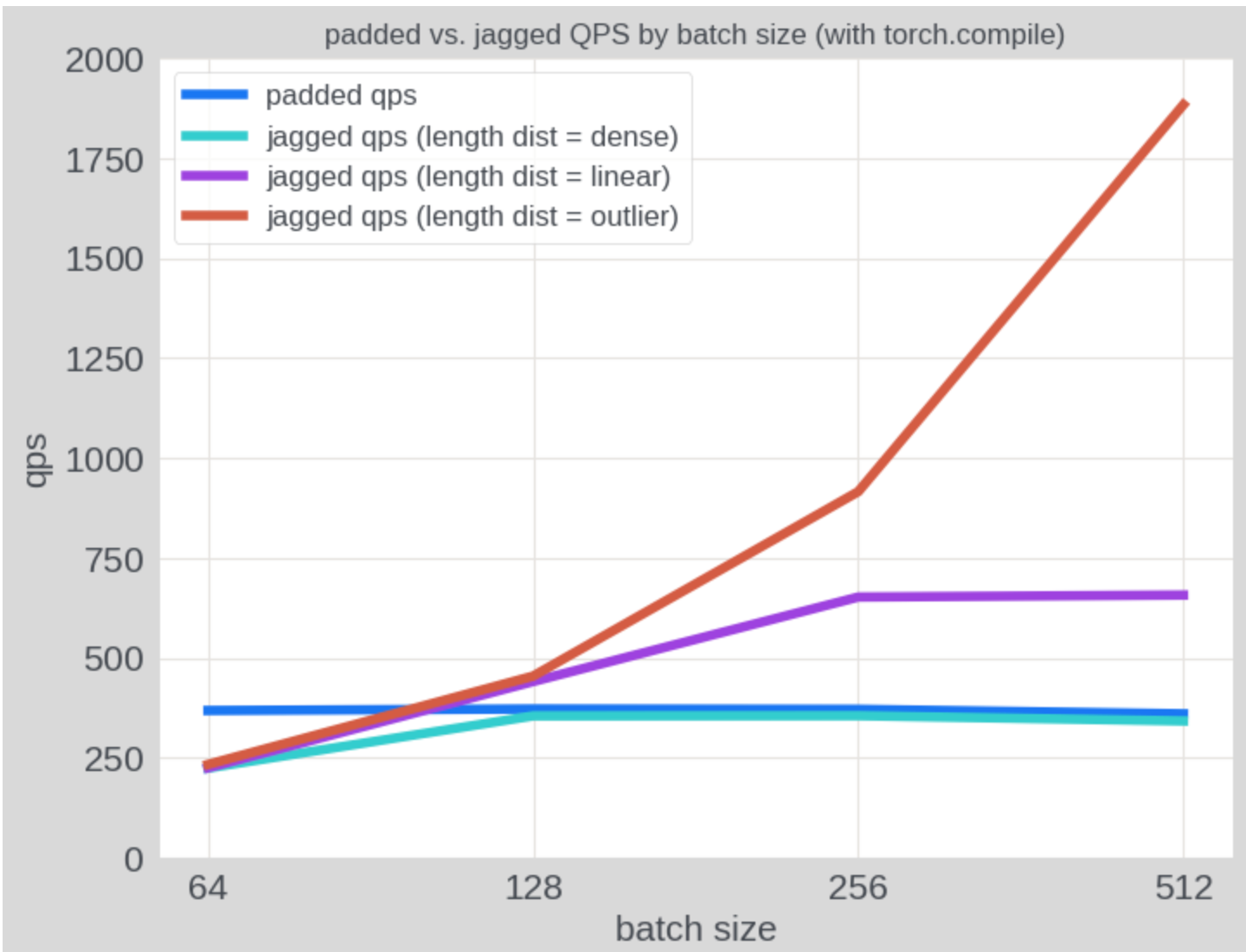
As anticipated, NJT demonstrated substantially higher throughput on inputs with uneven sequence lengths compared to padded tensors. In the plot below, we evaluated QPS on synthetic data with various sequence length patterns: (1) “dense” batches where every sequence is of length 256, (2) “linear” batches where the sequence lengths in the batch increase linearly from 1 to 256, and (3) “outlier” batches where one sequence is of length 256, and the remaining sequences are of length 1. The inference cost remains constant in all three cases when using padded tensors, whereas the inference cost with NJT decreases as batch sparsity increases. On the “linear” distribution, NJT outperforms padded tensors by approximately 1.85x.
Implementation
Following code modifications needed to apply NJTs for LLaMa model. Mainly in two key components: transform and Attention.
Transform
Convert token ids into jagged token ids and make attention mask = none as mask is not needed as there is no padding.
jagged_input_ids = torch.nested.nested_tensor( tokenizer_output.input_ids, layout=torch.jagged ) attention_mask = None
LlamaSdpaAttention
- Llama 3 introduces Grouped Query Attention (GQA), which is characterized by having more attention heads than key-value heads (
num_attention_heads > num_key_value_heads) To ensure compatibility during the attention process, the repeat_kv function plays a key role—its main job is to efficiently replicate key-value heads across query heads. This operation reshapes tensors from (batch, num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim).
To better handle jagged and dense tensor formats, the original repeat_kv function has been split into two specialized functions:
-
-
-
- repeat_dense_kv: Used for dense tensors, this function is the same as the original repeat_kv.
- repeat_jagged_kv: Tailored for jagged tensors, which come with
ragged_idxindices adding complexity. This method utilizes a sequence of transpose and flatten operations. By temporarily altering the dimension order before flattening and then transposing back, it effectively navigates the unique challenges presented by jagged tensors.
-
-
def repeat_jagged_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor: """ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim) """
batch, num_key_value_heads, slen, head_dim = hidden_states.shape expand_shape = (batch, num_key_value_heads, -1, n_rep, head_dim) if n_rep == 1: return hidden_states hidden_states = ( hidden_states.unsqueeze(3) .expand(expand_shape) .transpose(1, 2) .flatten(2, 3) .transpose(1, 2) ) return hidden_states
def repeat_dense_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor: """ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim) """ batch, num_key_value_heads, slen, head_dim = hidden_states.shape if n_rep == 1: return hidden_states hidden_states = hidden_states[:, :, None, :, :].expand( batch, num_key_value_heads, n_rep, slen, head_dim ) return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
2. When applying Rotary Position Embedding (RoPE) to query and key tensors, we need to handle two different tensor formats: jagged and dense. To accommodate this, we implemented two separate functions, each tailored to the specific tensor type. The main function, apply_rotary_pos_emb(), acts as a router that directs the input to either _jagged_tensor_forwardor
_dense_tensor_forward
For jagged tensors, the process involves three key steps: first, converting the jagged tensor into a dense tensor using q.to_padded_tensor(0.0); second, applying the rotary position embedding on this dense representation; and finally, converting the dense tensor back into its original jagged format with convert
_dense_to_jagged.
def apply_rotary_pos_emb( q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor, unsqueeze_dim: int = 1, ) -> Tuple[torch.Tensor, torch.Tensor]: cos = cos.unsqueeze(unsqueeze_dim) sin = sin.unsqueeze(unsqueeze_dim) if q.is_nested and k.is_nested: if q.layout != torch.jagged: raise NotImplementedError(f"Unsupported layout: {q.layout}") if k.layout != torch.jagged: raise NotImplementedError(f"Unsupported layout: {k.layout}") return _jagged_tensor_forward(q, k, cos, sin) else: return _dense_tensor_forward(q, k, cos, sin)
def _jagged_tensor_forward( q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor, ) -> Tuple[torch.Tensor, torch.Tensor]: q_dense = q.to_padded_tensor(0.0) k_dense = k.to_padded_tensor(0.0) q_dense_embed = (q_dense * cos) + (rotate_half(q_dense) * sin) k_dense_embed = (k_dense * cos) + (rotate_half(k_dense) * sin) q_jagged_embed = convert_dense_to_jagged(q, q_dense_embed) k_jagged_embed = convert_dense_to_jagged(k, k_dense_embed) return q_jagged_embed, k_jagged_embed def _dense_tensor_forward( q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor, ) -> Tuple[torch.Tensor, torch.Tensor]: q_embed = (q * cos) + (rotate_half(q) * sin) k_embed = (k * cos) + (rotate_half(k) * sin) return q_embed, k_embed def convert_dense_to_jagged(nested_q: torch.Tensor, q: torch.Tensor) -> torch.Tensor: padded_max_S = nested_q._get_max_seqlen()
total_L = nested_q._values.shape[nested_q._ragged_idx - 1] if padded_max_S is None: # use upper bound on max seqlen if it's not present padded_max_S = total_L # convert dense tensor -> jagged q = q.expand( [ x if i != nested_q._ragged_idx else padded_max_S for i, x in enumerate(q.shape) ] ) nested_result = nested_from_padded( q, offsets=nested_q._offsets, ragged_idx=nested_q._ragged_idx, sum_S=total_L, min_seqlen=nested_q._get_min_seqlen(), max_seqlen=padded_max_S, ) return nested_result
Added implementation for Drama model with NJTs : modeling_drama_nested.py
Acknowledgement
We would like to thank Xilun Chen for helpful feedback in code review. And Don Husa, Jeffrey Wan, Joel Schlosser and Fernando Hernandez for helpful feedback on the blog.
Conclusion
This optimization using NJTs significantly enhances the efficiency of DRAMA (LlaMa based encoders), making them more practical for real-world deployment. By reducing computational overhead, particularly for variable-length sequences, this approach paves the way for broader adoption of high-performing LLM-based encoders in production environments. However, NJT is a feature complete in PyTorch and not actively adding new features to it, but does welcome community contributions.