Today, many AWS customers are building enterprise-ready machine learning (ML) platforms on Amazon Elastic Kubernetes Service (Amazon EKS) using Kubeflow on AWS (an AWS-specific distribution of Kubeflow) across many use cases, including computer vision, natural language understanding, speech translation, and financial modeling.
With the latest release of open-source Kubeflow v1.6.1, the Kubeflow community continues to support this large-scale adoption of Kubeflow for enterprise use cases. The latest release includes many new exciting features like support for Kubernetes v1.22, combined Python SDK for PyTorch, MXNet, MPI, XGBoost in Kubeflow’s distributed Training Operator, new ClusterServingRuntime and ServingRuntime CRDs for model service, and many more.
AWS contributions to Kubeflow with the recent launch of Kubeflow on AWS 1.6.1 support all upstream open-source Kubeflow features and include many new integrations with the highly optimized, cloud-native, enterprise-ready AWS services that will help you build highly reliable, secure, portable, and scalable ML systems.
In this post, we discuss new Kubeflow on AWS v1.6.1 features and highlight three important integrations that have been bundled on one platform to offer you::
- Infrastructure as Code (IaaC) one-click solution that automates the end-to-end installation of Kubeflow, including EKS cluster creation
- Support for distributed training on Amazon SageMaker using Amazon SageMaker Operators for Kubernetes (ACK) and SageMaker components for Kubeflow pipelines and locally on Kubernetes using Kubeflow Training Operators. Many customers are using this capability to build hybrid machine learning architectures where they are leveraging both Kubernetes compute for experimentation phase and SageMaker to run production scale workloads.
- Enhanced monitoring and observability for ML workloads including Amazon EKS, Kubeflow metrics, and application logs using Prometheus, Grafana, and Amazon CloudWatch integrations
The use case in this blog will specifically focus on SageMaker integration with Kubeflow on AWS that could be added to your existing Kubernetes workflows enabling you to build hybrid machine learning architectures.
Kubeflow on AWS
Kubeflow on AWS 1.6.1 provides a clear path to use Kubeflow, with the addition of the following AWS services on top of existing capabilities:
- SageMaker Integration with Kubeflow to run hybrid ML workflows using SageMaker Operators for Kubernetes (ACK) and SageMaker Components for Kubeflow Pipelines.
- Automated deployment options have been improved and simplified using Kustomize scripts and Helm charts.
- Added support for Infrastructure as Code (IaC) one-click deployment for Kubeflow on AWS using Terraform for all the available deployment options. This script automates creation of the following AWS resources:
- VPCs and EKS clusters
- Amazon Simple Storage Service (Amazon S3) buckets
- Amazon Relational Database Service (Amazon RDS) instances
- Amazon Cognito resources
- Configures and deploys Kubeflow
- Configured using EKS Blueprints for improved customizability and extensibility
- Support for AWS PrivateLink for Amazon S3 enabling non-commercial Region users to connect to their respective S3 endpoints.
- Added integration with Amazon Managed Service for Prometheus (AMP) and Amazon Managed Grafana to monitor metrics with Kubeflow on AWS.
- Updated Kubeflow notebook server containers with the latest deep learning container images based on TensorFlow 2.10.0 and PyTorch 1.12.1.
- Integration with AWS DLCs to run distributed training and inference workloads.
The following architecture diagram is a quick snapshot of all the service integrations (including the ones already mentioned) that are available for Kubeflow control and data plane components in Kubeflow on AWS. The Kubeflow control plane is installed on top of Amazon EKS, which is a managed container service used to run and scale Kubernetes applications in the cloud. These AWS service integrations allow you to decouple critical parts of the Kubeflow control plane from Kubernetes, providing a secure, scalable, resilient, and cost-optimized design. For more details on the value that these service integrations add over open-source Kubeflow, refer to Build and deploy a scalable machine learning system on Kubernetes with Kubeflow on AWS.

Let’s discuss in more detail on how the Kubeflow on AWS 1.6.1 key features could be helpful to your organization.
Kubeflow on AWS feature details
With the Kubeflow 1.6.1 release, we tried to provide better tools for different kinds of customers that make it easy to get started with Kubeflow no matter which options you choose. These tools provide a good starting point and can be modified to fit your exact needs.
Deployment options
We provide different deployment options for different customer use cases. Here you get to choose which AWS services you want to integrate your Kubeflow deployment with. If you decide to change deployment options later, we recommend that you do a fresh installation for the new deployment. The following deployment options are available:
- Vanilla installation
- Amazon RDS and Amazon S3
- Amazon Cognito
- Amazon Cognito, Amazon RDS, and Amazon S3
If you want to deploy Kubeflow with minimal changes, consider the vanilla deployment option. All available deployment options can be installed using Kustomize, Helm, or Terraform.
We also have different add-on deployments that can be installed on top of any of these deployment options:
Installation options
After you have decided which deployment option best suits your needs, you can choose how you want to install these deployments. In an effort to serve experts and newcomers alike, we have different levels of automation and configuration.
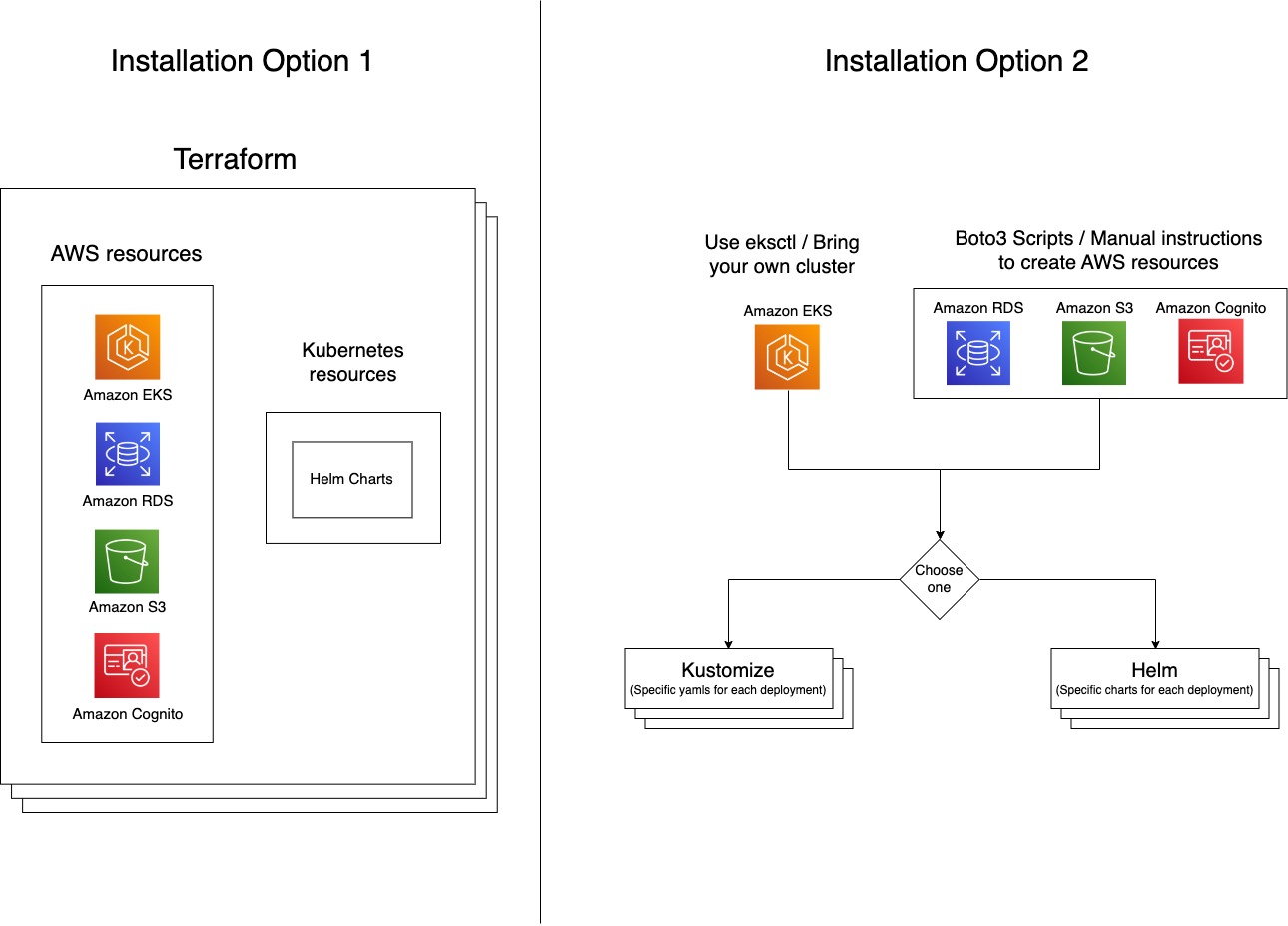
Option 1: Terraform (IaC)
This creates an EKS cluster and all the related AWS infrastructure resources, and then deploys Kubeflow all in one command using Terraform. Internally, this uses EKS blueprints and Helm charts.
This option has the following advantages:
- It provides flexibility to enterprises to deploy Amazon EKS and Kubeflow with one command without having to worry about specific Kubeflow component configurations. This will immensely help speed up technology evaluation, prototyping, and the product development lifecycle providing flexibility to use terraform modules and modify it to meet any project-specific needs.
- Many organizations today who have Terraform as the centre of their cloud strategy can now use Kubeflow on AWS Terraform solution to meet their cloud goals.
Option 2: Kustomize or Helm Charts:
This option allows you to deploy Kubeflow in a two-step process:
- Create AWS resources like Amazon EKS, Amazon RDS, Amazon S3, and Amazon Cognito, either through the automated scripts included in the AWS distribution or manually following a step-by-step guide.
- Install Kubeflow deployments either using Helm charts or Kustomize.
This option has the following advantages:
- The main goal of this installation option is to provide Kubeflow-related Kubernetes configurations. Therefore, you can choose to create or bring in existing EKS clusters or any of the related AWS resources like Amazon RDS, Amazon S3, and Amazon Cognito, and configure and manage it to work with Kubeflow on AWS.
- It’s easier to move from an open-source Kustomize Kubeflow manifest to AWS Kubeflow distribution.
The following diagram illustrates the architectures of both options.
Integration with SageMaker
SageMaker is a fully managed service designed and optimized specifically for managing ML workflows. It removes the undifferentiated heavy lifting of infrastructure management and eliminates the need to invest in IT and DevOps to manage clusters for ML model building, training, and inference.
Many AWS customers who have portability requirements or on-premises standard restrictions use Amazon EKS to set up repeatable ML pipelines running training and inference workloads. However, this requires developers to write custom code to optimize the underlying ML infrastructure, provide high availability and reliability, and comply with appropriate security and regulatory requirements. These customers therefore want to use SageMaker for cost-optimized and managed infrastructure for model training and deployments and continue using Kubernetes for orchestration and ML pipelines to retain standardization and portability.
To address this need, AWS allows you to train, tune, and deploy models in SageMaker from Amazon EKS by using the following two options:
- Amazon SageMaker ACK Operators for Kubernetes, which are based on the AWS Controllers for Kubernetes (ACK) framework. ACK is the AWS strategy that brings in standardization for building Kubernetes custom controllers that allow Kubernetes users to provision AWS resources like databases or message queues simply by using the Kubernetes API. SageMaker ACK Operators make it easier for ML developers and data scientists who use Kubernetes as their control plane to train, tune, and deploy ML models in SageMaker without signing in to the SageMaker console.
- The SageMaker Components for Kubeflow Pipelines, which allow you to integrate SageMaker with the portability and orchestration of Kubeflow Pipelines. With the SageMaker components, each job in the pipeline workflow runs on SageMaker instead of the local Kubernetes cluster. This allows you to create and monitor native SageMaker training, tuning, endpoint deployment, and batch transform jobs from your Kubeflow Pipelines hence allowing you to move complete compute including data processing and training jobs from the Kubernetes cluster to SageMaker’s machine learning-optimized managed service.
Starting with Kubeflow on AWS v1.6.1, all of the available Kubeflow deployment options bring together both Amazon SageMaker integration options by default on one platform. That means, you can now submit SageMaker jobs using SageMaker ACK operators from a Kubeflow Notebook server itself by submitting the custom SageMaker resource or from the Kubeflow pipeline step using SageMaker components.
There are two versions of SageMaker Components – Boto3 (AWS SDK for AWS SDK for Python) based version 1 components and SageMaker Operator for K8s (ACK) based version 2 components. The new SageMaker components version 2 support latest SageMaker training apis and we will continue to add more SageMaker features to this version of the component. You however have the flexibility to combine Sagemaker components version 2 for training and version 1 for other SageMaker features like hyperparameter tuning, processing jobs, hosting and many more.
Integration with Prometheus and Grafana
Prometheus is an open-source metrics aggregation tool that you can configure to run on Kubernetes clusters. When running on Kubernetes clusters, a main Prometheus server periodically scrapes pod endpoints.
Kubeflow components, such as Kubeflow Pipelines (KFP) and Notebook, emit Prometheus metrics to allow monitoring component resources such as the number of running experiments or notebook count.
These metrics can be aggregated by a Prometheus server running in the Kubernetes cluster and queried using Prometheus Query Language (PromQL). For more details on the features that Prometheus supports, check out the Prometheus documentation.
The Kubeflow on AWS distribution provides support for the integration with following AWS managed services:
- Amazon Managed Prometheus (AMP) that is a Prometheus-compatible monitoring service for container infrastructure and application metrics for containers that makes it easy for customers to securely monitor container environments at scale. Using AMP, you can visualize, analyze, and alarm on your metrics, logs, and traces collected from multiple data sources in your observability system, including AWS, third-party ISVs, and other resources across your IT portfolio.
- Amazon Managed Grafana, a fully managed and secure data visualization service based on the open source Grafana project, that enables customers to instantly query, correlate, and visualize operational metrics, logs, and traces for their applications from multiple data sources. Amazon Managed Grafana offloads the operational management of Grafana by automatically scaling compute and database infrastructure as usage demands increase, with automated version updates and security patching.
The Kubeflow on AWS distribution provides support for the integration of Amazon Managed Service for Prometheus and Amazon Managed Grafana to facilitate the ingestion and visualization of Prometheus metrics securely at scale.
The following metrics are ingested and can be visualized:
- Metrics emitted from Kubeflow components such as Kubeflow Pipelines and the Notebook server
- Kubeflow control plane metrics
To configure Amazon Managed Service for Prometheus and Amazon Managed Grafana for your Kubeflow cluster, refer to Use Prometheus, Amazon Managed Service for Prometheus, and Amazon Managed Grafana to monitor metrics with Kubeflow on AWS.
Solution overview
In this use case, we use the Kubeflow vanilla deployment using Terraform installation option. When installation is complete, we log in to the Kubeflow dashboard. From the dashboard, we spin up a Kubeflow Jupyter notebook server to build a Kubeflow pipeline that uses SageMaker to run distributed training for an image classification model and a SageMaker endpoint for model deployment.
Prerequisites
Make sure you meet the following prerequisites:
- You have an AWS account.
- Make sure you’re in the
us-west-2Region to run this example. - Use Google Chrome for interacting with the AWS Management Console and Kubeflow.
- Make sure your account has SageMaker Training resource type limit for ml.p3.2xlarge increased to 2 using the Service Quotas console.
- Optionally, you can use AWS Cloud9, a cloud-based integrated development environment (IDE) that enables completing all the work from your web browser. For setup instructions, refer to Setup Cloud9 IDE. Select Ubuntu Server 18.04 as a platform in the AWS Cloud9 settings.
 Then from your AWS Cloud9 environment, choose the plus sign and open new terminal.
Then from your AWS Cloud9 environment, choose the plus sign and open new terminal.
You also configure an AWS Command Line Interface (AWS CLI) profile. To do so, you need an access key ID and secret access key of an AWS Identity and Access Management (IAM) user account with administrative privileges (attach the existing managed policy) and programmatic access. See the following code:
Verify the permissions that cloud9 will use to call AWS resources.
Verify from the below output that you see arn of the admin user that you have configured in AWS CLI profile. In this example it is “kubeflow-user”
Install Amazon EKS and Kubeflow on AWS
To install Amazon EKS and Kubeflow on AWS, complete the following steps:
- Set up your environment for deploying Kubeflow on AWS:
- Deploy the vanilla version of Kubeflow on AWS and related AWS resources like EKS using Terraform. Please note that EBS volumes used in EKS nodegroup are not encrypted by default:
Set up the Kubeflow Permissions
- Add permissions to Notebook pod and Pipeline component pod to make SageMaker, S3 and IAM api calls using
kubeflow_iam_permissions.shscript. - Create SageMaker execution role to enable SageMaker training job to access training dataset from S3 service using
sagemaker_role.shscript.
Access the Kubeflow dashboard
To access the Kubeflow dashboard, complete the following steps:
- You can run Kubeflow dashboard locally in Cloud9 environment without exposing your URLs to public internet by running below commands.
- Choose Preview Running Application.

- Choose the icon in the corner of the Kubeflow dashboard to open it as a separate tab in Chrome.
- Enter the default credentials (
user@example.com/12341234) to log in to the Kubeflow dashboard.
Set up the Kubeflow on AWS environment
Once you’re logged in to the Kubeflow dashboard, ensure you have the right namespace (kubeflow-user-example-com) chosen. Complete the following steps to set up your Kubeflow on AWS environment:
- On the Kubeflow dashboard, choose Notebooks in the navigation pane.
- Choose New Notebook.
- For Name, enter
aws-nb. - For Jupyter Docket Image, choose the image
jupyter-pytorch:1.12.0-cpu-py38-ubuntu20.04-ec2-2022-09-20(the latest availablejupyter-pytorchDLC image). - For CPU, enter
1. - For Memory, enter
5. - For GPUs, leave as None.
- Don’t make any changes to the Workspace and Data Volumes sections.

- Select Allow access to Kubeflow Pipelines in the Configurations section and Choose Launch.

- Verify that your notebook is created successfully (it may take a couple of minutes).

- Choose Connect to log in to JupyterLab.
- Clone the repo by entering
https://github.com/aws-samples/eks-kubeflow-cloudformation-quick-start.gitin the Clone a repo field. - Choose Clone.

Run a distributed training example
After you set up the Jupyter notebook, you can run the entire demo using the following high-level steps from the folder eks-kubeflow-cloudformation-quick-start/workshop/pytorch-distributed-training in the cloned repository:
- Run the PyTorch Distributed Data Parallel (DDP) training script – Refer to the PyTorch DDP training script
cifar10-distributed-gpu-final.py, which includes a sample convolutional neural network and logic to distribute training on a multi-node CPU and GPU cluster. - Create a Kubeflow pipeline – Run the notebook
STEP1.0_create_pipeline_k8s_sagemaker.ipynbto create a pipeline that runs and deploy models on SageMaker. Make sure you install the SageMaker library as part of the first notebook cell and restart the kernel before you run the rest of the notebook cells. - Invoke a SageMaker endpoint – Run the notebook
STEP1.1_invoke_sagemaker_endpoint.ipynbto invoke and test the SageMaker model inference endpoint created in the previous notebook.
In the subsequent sections, we discuss each of these steps in detail.
Run the PyTorch DDP training script
As part of the distributed training, we train a classification model created by a simple convolutional neural network that operates on the CIFAR10 dataset. The training script cifar10-distributed-gpu-final.py contains only the open-source libraries and is compatible to run both on Kubernetes and SageMaker training clusters on either GPU devices or CPU instances. Let’s look at a few important aspects of the training script before we run our notebook examples.
We use the torch.distributed module, which contains PyTorch support and communication primitives for multi-process parallelism across nodes in the cluster:
We create a simple image classification model using a combination of convolutional, max pooling, and linear layers to which a relu activation function is applied in the forward pass of the model training:
If the training cluster has GPUs, the script runs the training on CUDA devices and the device variable holds the default CUDA device:
Before you run distributed training using PyTorch DistributedDataParallel to run distributed processing on multiple nodes, you need to initialize the distributed environment by calling init_process_group. This is initialized on each machine of the training cluster.
We instantiate the classifier model and copy over the model to the target device. If distributed training is enabled to run on multiple nodes, the DistributedDataParallel class is used as a wrapper object around the model object, which allows synchronous distributed training across multiple machines. The input data is split on the batch dimension and a replica of the model is placed on each machine and each device. See the following code:
Create a Kubeflow pipeline
The notebook uses the Kubeflow Pipelines SDK and its provided set of Python packages to specify and run the ML workflow pipelines. As part of this SDK, we use the domain-specific language (DSL) package decorator dsl.pipeline, which decorates the Python functions to return a pipeline.
The Kubeflow pipeline uses SageMaker component V2 for submitting training to SageMaker using SageMaker ACK Operators. SageMaker model creation and model deployment uses SageMaker component V1, which are Boto3-based SageMaker components. We use a combination of both components in this example to demonstrate the flexibility you have in choice.
- Load the SageMaker components using the following code:
In the following code, we create the Kubeflow pipeline where we run SageMaker distributed training using two
ml.p3.2xlargeinstances:After the pipeline is defined, you can compile the pipeline to an Argo YAML specification using the Kubeflow Pipelines SDK’s
kfp.compilerpackage. You can run this pipeline using the Kubeflow Pipelines SDK client, which calls the Pipelines service endpoint and passes in appropriate authentication headers right from the notebook. See the following code: - Choose the Run details link under the last cell to view the Kubeflow pipeline. The following screenshot shows our pipeline details for the SageMaker training and deployment component.

- Choose the training job step and on the Logs tab, choose the CloudWatch logs link to access the SageMaker logs.
The following screenshot shows the CloudWatch logs for each of the two ml.p3.2xlarge instances.
- Choose any of the groups to see the logs.

- Capture the SageMaker endpoint by choosing the Sagemaker – Deploy Model step and copying the
endpoint_nameoutput artifact value.
Invoke a SageMaker endpoint
The notebook STEP1.1_invoke_sagemaker_endpoint.ipynb invokes the SageMaker inference endpoint created in the previous step. Ensure you update the endpoint name:
Clean up
To clean up your resources, complete the following steps:
- Run the following commands in AWS Cloud9 to delete the AWS resources:
- Delete IAM role “
sagemakerrole” using following AWS CLI command: - Delete SageMaker endpoint using the following AWS CLI command:
Summary
In this post, we highlighted the value that Kubeflow on AWS 1.6.1 provides through native AWS-managed service integrations to address the need of enterprise-level AI and ML use cases. You can choose from several deployment options to install Kubeflow on AWS with various service integrations using Terraform, Kustomize, or Helm. The use case in this post demonstrated a Kubeflow integration with SageMaker that uses a SageMaker managed training cluster to run distributed training for an image classification model and SageMaker endpoint for model deployment.
We have also made available a sample pipeline example that uses the latest SageMaker components; you can run this directly from the Kubeflow dashboard. This pipeline requires the Amazon S3 data and SageMaker execution IAM role as the required inputs.
To get started with Kubeflow on AWS, refer to the available AWS-integrated deployment options in Kubeflow on AWS. You can follow the AWS Labs repository to track all AWS contributions to Kubeflow. You can also find us on the Kubeflow #AWS Slack Channel; your feedback there will help us prioritize the next features to contribute to the Kubeflow project.
About the authors
 Kanwaljit Khurmi is a Senior Solutions Architect at Amazon Web Services. He works with the AWS customers to provide guidance and technical assistance helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
Kanwaljit Khurmi is a Senior Solutions Architect at Amazon Web Services. He works with the AWS customers to provide guidance and technical assistance helping them improve the value of their solutions when using AWS. Kanwaljit specializes in helping customers with containerized and machine learning applications.
 Kartik Kalamadi is a Software Development Engineer at Amazon AI. Currently focused on Machine Learning Kubernetes open-source projects such as Kubeflow and AWS SageMaker Controller for k8s. In my spare time I like playing PC Games and fiddling with VR using Unity engine.
Kartik Kalamadi is a Software Development Engineer at Amazon AI. Currently focused on Machine Learning Kubernetes open-source projects such as Kubeflow and AWS SageMaker Controller for k8s. In my spare time I like playing PC Games and fiddling with VR using Unity engine.
 Rahul Kharse is a Software Development Engineer at Amazon Web Services. His work focuses on integrating AWS services with open source containerized ML Ops platforms to improve their scalability, reliability, and security. In addition to focusing on customer requests for features, Rahul also enjoys experimenting with the latest technological developments in the field.
Rahul Kharse is a Software Development Engineer at Amazon Web Services. His work focuses on integrating AWS services with open source containerized ML Ops platforms to improve their scalability, reliability, and security. In addition to focusing on customer requests for features, Rahul also enjoys experimenting with the latest technological developments in the field.