In today’s digital world, most consumers would rather find answers to their customer service questions on their own rather than taking the time to reach out to businesses and/or service providers. This blog post explores an innovative solution to build a question and answer chatbot in Amazon Lex that uses existing FAQs from your website. This AI-powered tool can provide quick, accurate responses to real-world inquiries, allowing the customer to quickly and easily solve common problems independently.
Single URL ingestion
Many enterprises have a published set of answers for FAQs for their customers available on their website. In this case, we want to offer customers a chatbot that can answer their questions from our published FAQs. In the blog post titled Enhance Amazon Lex with conversational FAQ features using LLMs, we demonstrated how you can use a combination of Amazon Lex and LlamaIndex to build a chatbot powered by your existing knowledge sources, such as PDF or Word documents. To support a simple FAQ, based on a website of FAQs, we need to create an ingestion process that can crawl the website and create embeddings that can be used by LlamaIndex to answer customer questions. In this case, we will build on the bot created in the previous blog post, which queries those embeddings with a user’s utterance and returns the answer from the website FAQs.
The following diagram shows how the ingestion process and the Amazon Lex bot work together for our solution.
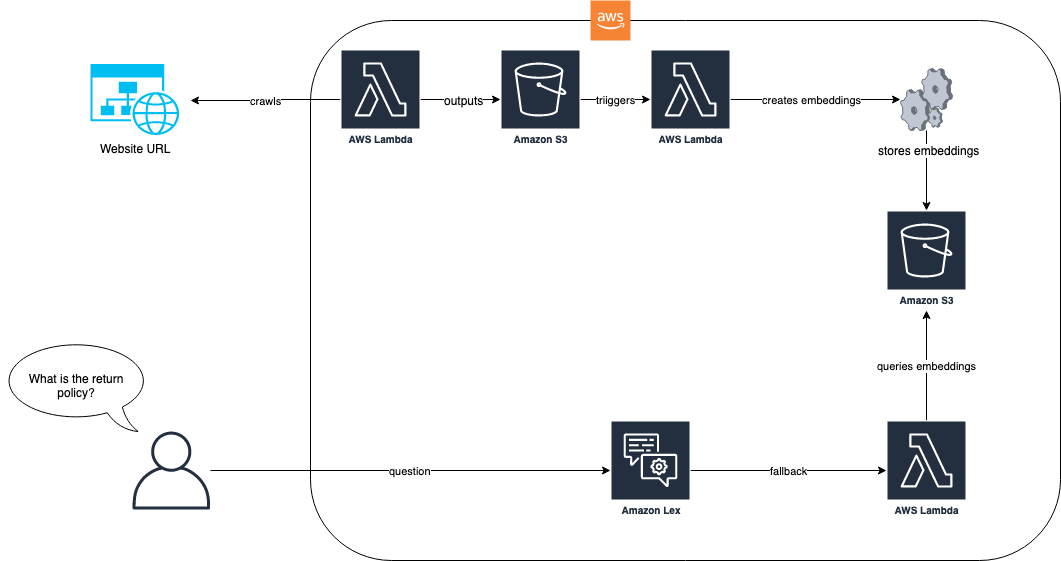
In the solution workflow, the website with FAQs is ingested via AWS Lambda. This Lambda function crawls the website and stores the resulting text in an Amazon Simple Storage Service (Amazon S3) bucket. The S3 bucket then triggers a Lambda function that uses LlamaIndex to create embeddings that are stored in Amazon S3. When a question from an end-user arrives, such as “What is your return policy?”, the Amazon Lex bot uses its Lambda function to query the embeddings using a RAG-based approach with LlamaIndex. For more information about this approach and the pre-requisites, refer to the blog post, Enhance Amazon Lex with conversational FAQ features using LLMs.
After the pre-requisites from the aforementioned blog are complete, the first step is to ingest the FAQs into a document repository that can be vectorized and indexed by LlamaIndex. The following code shows how to accomplish this:
In the preceding example, we take a predefined FAQ website URL from Zappos and ingest it using the EZWebLoader class. With this class, we have navigated to the URL and loaded all the questions that are in the page into an index. We can now ask a question like “Does Zappos have gift cards?” and get the answers directly from our FAQs on the website. The following screenshot shows the Amazon Lex bot test console answering that question from the FAQs.

We were able to achieve this because we had crawled the URL in the first step and created embedddings that LlamaIndex could use to search for the answer to our question. Our bot’s Lambda function shows how this search is run whenever the fallback intent is returned:
This solution works well when a single webpage has all the answers. However, most FAQ sites are not built on a single page. For instance, in our Zappos example, if we ask the question “Do you have a price matching policy?”, then we get a less-than-satisfactory answer, as shown in the following screenshot.
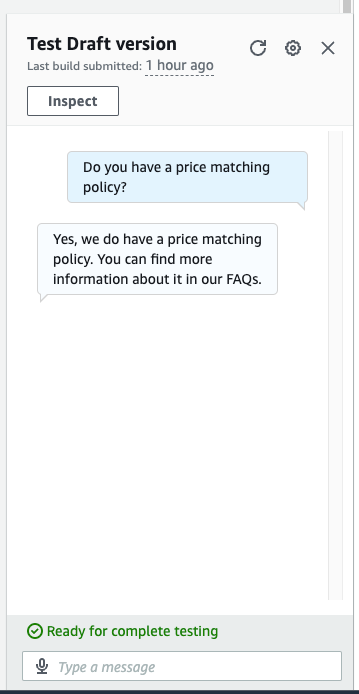
In the preceding interaction, the price-matching policy answer isn’t helpful for our user. This answer is short because the FAQ referenced is a link to a specific page about the price matching policy and our web crawl was only for the single page. Achieving better answers will mean crawling these links as well. The next section shows how to get answers to questions that require two or more levels of page depth.
N-level crawling
When we crawl a web page for FAQ knowledge, the information we want can be contained in linked pages. For example, in our Zappos example, we ask the question “Do you have a price matching policy?” and the answer is “Yes please visit <link> to learn more.” If someone asks “What is your price matching policy?” then we want to give a complete answer with the policy. Achieving this means we have the need to traverse links to get the actual information for our end-user. During the ingestion process, we can use our web loader to find the anchor links to other HTML pages and then traverse them. The following code change to our web crawler allows us to find links in the pages we crawl. It also includes some additional logic to avoid circular crawling and allow a filter by a prefix.
In the preceding code, we introduce the ability to crawl N levels deep, and we give a prefix that allows us to restrict crawling to only things that begin with a certain URL pattern. In our Zappos example, the customer service pages all are rooted from zappos.com/c, so we include that as a prefix to limit our crawls to a smaller and more relevant subset. The code shows how we can ingest up to two levels deep. Our bot’s Lambda logic remains the same because nothing has changed except the crawler ingests more documents.
We now have all the documents indexed and we can ask a more detailed question. In the following screenshot, our bot provides the correct answer to the question “Do you have a price matching policy?”

We now have a complete answer to our question about price matching. Instead of simply being told “Yes see our policy,” it gives us the details from the second-level crawl.
Clean up
To avoid incurring future expenses, proceed with deleting all the resources that were deployed as part of this exercise. We have provided a script to shut down the Sagemaker endpoint gracefully. Usage details are in the README. Additionally, to remove all the other resources you can run cdk destroy in the same directory as the other cdk commands to deprovision all the resources in your stack.
Conclusion
The ability to ingest a set of FAQs into a chatbot enables your customers to find the answers to their questions with straightforward, natural language queries. By combining the built-in support in Amazon Lex for fallback handling with a RAG solution such as a LlamaIndex, we can provide a quick path for our customers to get satisfying, curated, and approved answers to FAQs. By applying N-level crawling into our solution, we can allow for answers that could possibly span multiple FAQ links and provide deeper answers to our customer’s queries. By following these steps, you can seamlessly incorporate powerful LLM-based Q and A capabilities and efficient URL ingestion into your Amazon Lex chatbot. This results in more accurate, comprehensive, and contextually aware interactions with users.
About the authors
 Max Henkel-Wallace is a Software Development Engineer at AWS Lex. He enjoys working leveraging technology to maximize customer success. Outside of work he is passionate about cooking, spending time with friends, and backpacking.
Max Henkel-Wallace is a Software Development Engineer at AWS Lex. He enjoys working leveraging technology to maximize customer success. Outside of work he is passionate about cooking, spending time with friends, and backpacking.
 Song Feng is a Senior Applied Scientist at AWS AI Labs, specializing in Natural Language Processing and Artificial Intelligence. Her research explores various aspects of these fields including document-grounded dialogue modeling, reasoning for task-oriented dialogues, and interactive text generation using multimodal data.
Song Feng is a Senior Applied Scientist at AWS AI Labs, specializing in Natural Language Processing and Artificial Intelligence. Her research explores various aspects of these fields including document-grounded dialogue modeling, reasoning for task-oriented dialogues, and interactive text generation using multimodal data.
 John Baker is a Principal SDE at AWS where he works on Natural Language Processing, Large Language Models and other ML/AI related projects. He has been with Amazon for 9+ years and has worked across AWS, Alexa and Amazon.com. In his spare time, John enjoys skiing and other outdoor activities throughout the Pacific Northwest.
John Baker is a Principal SDE at AWS where he works on Natural Language Processing, Large Language Models and other ML/AI related projects. He has been with Amazon for 9+ years and has worked across AWS, Alexa and Amazon.com. In his spare time, John enjoys skiing and other outdoor activities throughout the Pacific Northwest.