Amazon Comprehend is a natural language processing (NLP) service that uses machine learning (ML) to discover insights from text. As a fully managed service, Amazon Comprehend requires no ML expertise and can scale to large volumes of data. Amazon Comprehend provides several different APIs to easily integrate NLP into your applications. You can simply call the APIs in your application and provide the location of the source document or text. The APIs output entities, key phrases, sentiment, document classification, and language in an easy-to-use format for your application or business.
The sentiment analysis APIs provided by Amazon Comprehend help businesses determine the sentiment of a document. You can gauge the overall sentiment of a document as positive, negative, neutral, or mixed. However, to get the granularity of understanding the sentiment associated with specific products or brands, businesses have had to employ workarounds like chunking the text into logical blocks and inferring the sentiment expressed towards a specific product.
To help simplify this process, starting today, Amazon Comprehend is launching the Targeted Sentiment feature for sentiment analysis. This provides the capability to identify groups of mentions (co-reference groups) corresponding to a single real-world entity or attribute, provide the sentiment associated with each entity mention, and provide the classification of the real-world entity based on a pre-determined list of entities.
This post provides an overview of how you can get started with Amazon Comprehend targeted sentiment, demonstrates what you can do with the output, and walks through three common targeted sentiment use cases.
Solution overview
The following is an example of targeted sentiment:

“Spa” is the primary entity, identified as type facility, and is mentioned two more times, referred to as the pronoun “it.” The Targeted Sentiment API provides the sentiment towards each entity. Positive sentiment is green, negative is red, and neutral is blue. We can also determine how the sentiment towards the spa changes throughout the sentence. We dive deeper into the API later in the post.
This capability opens up several different capabilities for businesses. Marketing teams can track popular sentiments toward their brands in social media over time. Ecommerce merchants can understand which specific attributes of their products were best- and worst-received by customers. Call center operators can use the feature to mine transcripts for escalation issues and to monitor customer experience. Restaurants, hotels, and other hospitality industry organizations can use the service to turn broad ratings categories into rich descriptions of good and bad customer experiences.
Targeted sentiment use cases
The Targeted Sentiment API in Amazon Comprehend takes text data such as social media posts, application reviews, and call center transcriptions as input. Then it analyzes the input using the power of NLP algorithms to extract entity-level sentiment automatically. An entity is a textual reference to the unique name of a real-world object, such as people, places, and commercial items, in addition to precise references to measures such as dates and quantities. For a full list of supported entities, refer to Targeted Sentiment Entities.
We use the Targeted Sentiment API to enable the following use cases:
- A business can identify parts of the employee/customer experience that are enjoyable and parts that may be improved.
- Contact centers and customer service teams can analyze on-call transcriptions or chat logs to identify agent training effectiveness, and conversation details such as specific reactions from a customer and phrases or words that were used to illicit that response.
- Product owners and UI/UX developers can identify features of their product that users enjoy and parts that require improvement. This can support product roadmap discussions and prioritizations.
The following diagram illustrates the targeted sentiment process:

In this post, we demonstrate this process using the following three sample reviews:
- Sample 1: Business and product review – “I really like how thick the jacket is. I wear a large jacket because I have broad shoulders and that’s what I ordered and it fits perfectly there. I almost feel like it balloons out from the chest down. I thought I would use the strings in the bottom of the jacket to help close it and bring it in, but those don’t work. The jacket feels very bulky.”
- Sample 2: Contact center transcription – “Hi there, there is a fraud block on my credit card, can you remove it for me. My credit card keeps getting flagged for fraud. It is quite annoying, every time I go to use it, I keep getting declined. I’m going to cancel the card if this happens again.”
- Sample 3: Employer feedback survey – “I’m glad management is upskilling the team. But the instructor did not go over the basics well. Management should do more due diligence on everyone’s skill level for future sessions.”
Prepare the data
To get started, download the sample files containing the example text using the AWS Command Line Interface (AWS CLI) by running the following commands:
Create an Amazon Simple Storage Service (Amazon S3) bucket, unzip the folder and upload the folder containing the three sample files. Make sure you’re using the same Region throughout.
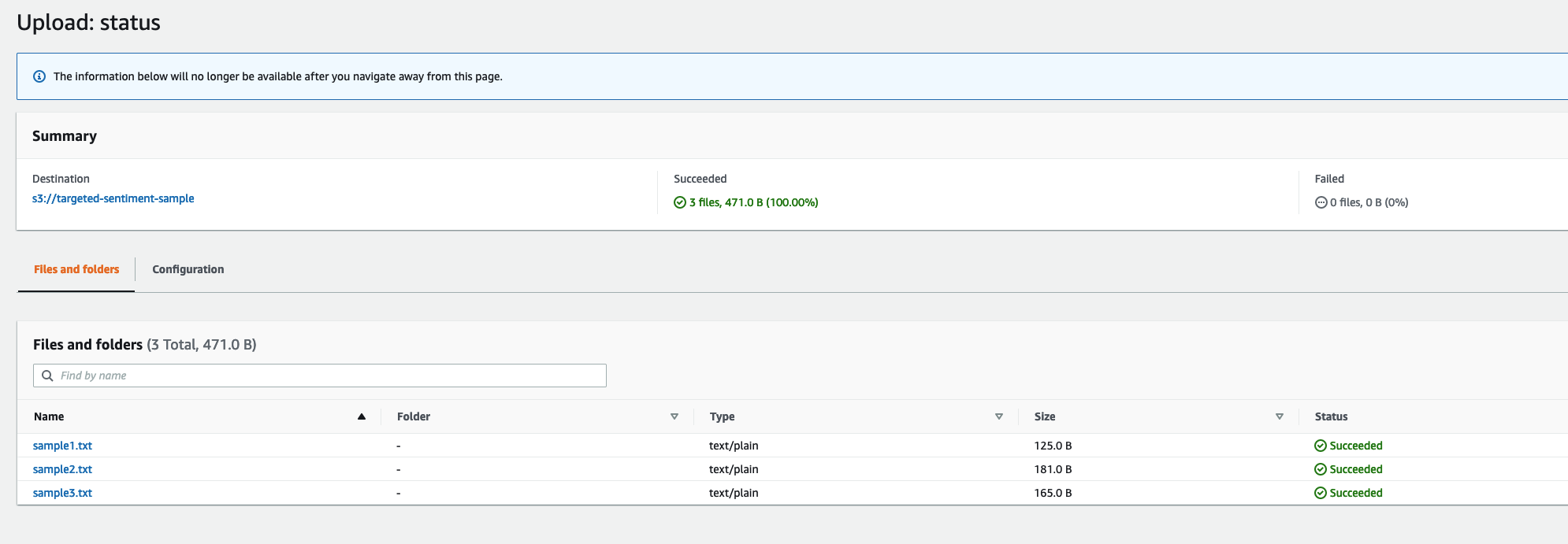
You can now access the three sample text files in your S3 bucket.
Create a job in Amazon Comprehend
After you upload the files to your S3 bucket, complete the following steps:
- On the Amazon Comprehend console, choose Analysis jobs in the navigation pane.

- Choose Create job.

- For Name, enter a name for your job.
- For Analysis type, choose Targeted sentiment.
- Under Input data, enter the Amazon S3 location of the ts-sample-data folder.
- For Input format, choose One document per file.
You can change this configuration if your data is in a single file delimited by lines.

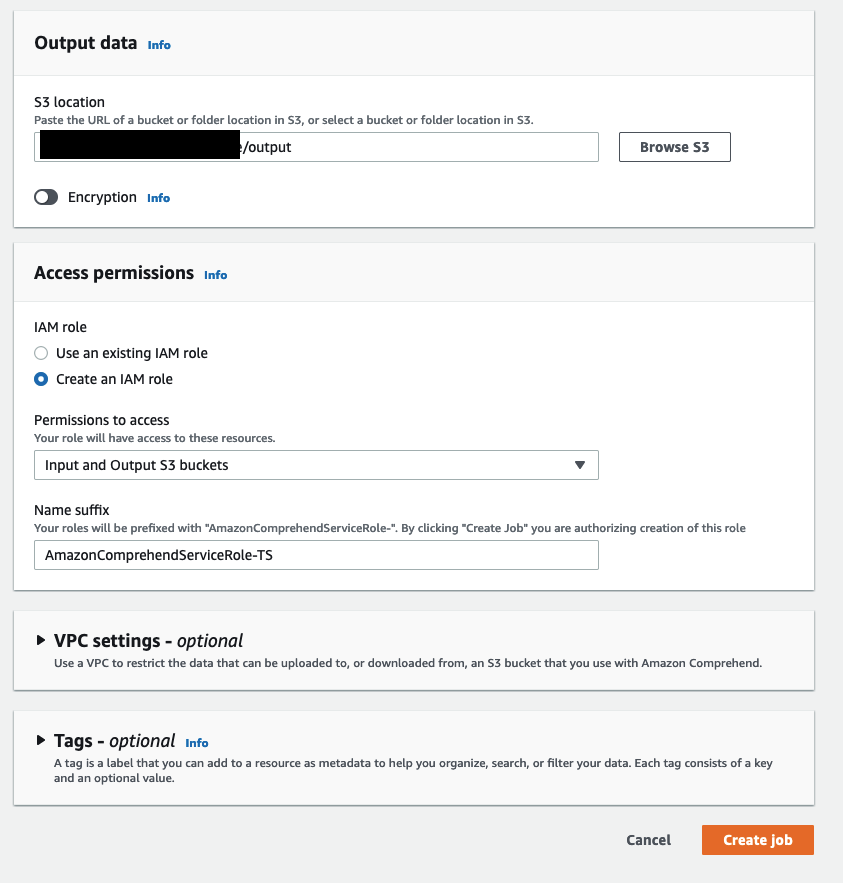
- Under Output location, enter the Amazon S3 location where you want to save the job output.
- Under Access permissions, for IAM role, choose an existing AWS Identity and Access Management (IAM) role or create one that has permissions to the S3 bucket.
- Leave the other options as default and choose Create job.
After you start the job, you can review your job details. The total job runtime depends on the size of the input data.

- When the job is complete, under Output, choose the link to the output data location.

Here you can find a compressed output file.
- Download and decompress the file.
You can now inspect the output files for each sample text. Open the files in your preferred text editor to review the API response structure. We describe this in more detail in the next section.

API response structure
The Targeted Sentiment API provides a simple way to consume the output of your jobs. It provides a logical grouping of the entities (entity groups) detected, along with the sentiment for each entity. The following are some definitions of the fields that are in the response:
-
Entities – The significant parts of the document. For example,
Person,Place,Date,Food, orTaste. - Mentions – The references or mentions of the entity in the document. These can be pronouns or common nouns such as “it,” “him,” “book,” and so on. These are organized in order by location (offset) in the document.
-
DescriptiveMentionIndex – The index in
Mentionsthat gives the best depiction of the entity group. For example, “ABC Hotel” instead of “hotel,” “it,” or other common noun mentions. - GroupScore – The confidence that all the entities mentioned in the group are related to the same entity (such as “I,” “me,” and “myself” referring to one person).
- Text – The text in the document that depicts the entity
- Type – A description of what the entity depicts.
- Score – The model confidence that this is a relevant entity.
- MentionSentiment – The actual sentiment found for the mention.
-
Sentiment – The string value of
positive,neutral,negative, ormixed. - SentimentScore – The model confidence for each possible sentiment.
- BeginOffset – The offset into the document text where the mention begins.
- EndOffset – The offset into the document text where the mention ends.
To demonstrate this visually, let’s take the output of the third use case, the employer feedback survey, and walk through the entity groups that represent the employee completing the survey, management, and the instructor.

Let’s first look at all the mentions of the co-reference entity group associated with “I” (the employee writing the response) and the location of the mention in the text. DescriptiveMentionIndex represents indexes of the entity mentions that best depict the co-reference entity group (in this case I):
The next group of entities provides all mentions of the co-reference entity group associated with management, along with its location in the text. DescriptiveMentionIndex represents indexes of the entity mentions that best depict the co-reference entity group (in this case management). Something to observe in this example is the sentiment shift towards management. You can use this data to infer what parts of management’s actions were perceived as positive, and what parts were perceived as negative and therefore can be improved upon.
To conclude, let’s observe all mentions of the instructor and the location in the text. DescriptiveMentionIndex represents indexes of the entity mentions that best depict the co-reference entity group (in this case instructor):
Reference architecture
You can apply targeted sentiment to many scenarios and use cases to drive business value, such as the following:
- Determine efficacy of marketing campaigns and feature launches by detecting the entities and mentions that contain the most positive or negative feedback
- Query output to determine which entities and mentions relate to a corresponding entity (positive, negative, or neutral)
- Analyze sentiment across the customer interaction lifecycle in contact centers to demonstrate efficacy of process or training changes
The following diagram depicts an end-to-end process:

Conclusion
Understanding the interactions and feedback organizations receive from customers about their products and services remains crucial in developing better products and customer experiences. As such, more granular details are required to infer better outcomes.
In this post, we provided some examples of how using these granular details can help organizations improve products, customer experiences, and training while also incentivizing and validating positive attributes. There are many use cases across industries where you can experiment with and gain value from targeted sentiment.
We encourage you to try this new feature with your use cases. For more information and to get started, refer to Targeted Sentiment.
About the Authors
 Raj Pathak is a Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Document Extraction, Contact Center Transformation and Computer Vision.
Raj Pathak is a Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Document Extraction, Contact Center Transformation and Computer Vision.
 Sanjeev Pulapaka is a Senior Solutions Architect in the U.S. Fed Civilian SA team at Amazon Web Services (AWS). He works closely with customers in building and architecting mission critical solutions. Sanjeev has extensive experience in leading, architecting and implementing high-impact technology solutions that address diverse business needs in multiple sectors including commercial, federal, state and local governments. He has an undergraduate degree in engineering from the Indian Institute of Technology and an MBA from the University of Notre Dame.
Sanjeev Pulapaka is a Senior Solutions Architect in the U.S. Fed Civilian SA team at Amazon Web Services (AWS). He works closely with customers in building and architecting mission critical solutions. Sanjeev has extensive experience in leading, architecting and implementing high-impact technology solutions that address diverse business needs in multiple sectors including commercial, federal, state and local governments. He has an undergraduate degree in engineering from the Indian Institute of Technology and an MBA from the University of Notre Dame.