It takes a lot of data for robots to autonomously learn to perform simple manipulation tasks as as grasping and pushing. For example, prior work12 has leveraged Deep Reinforcement Learning to train robots to grasp and stack various objects. These tasks are usually short and relatively simple – for example, picking up a plastic bottle in a tray. However, because reinforcement learning relies on gaining experiences through trial-and-error, hundreds of robot hours were required for the robot to learn to picking up objects reliably.
On the other hand, imitation learning can learn robot control policies directly from expert demonstrations without trial-and-error and thus require far less data than reinforcement learning. In prior work, a handful of human demonstrations have been used to train a robot to perform different skills such as pushing an object to a target location from only image input 3.


However, because the control policies are only trained with a fixed set of task demonstrations, it is difficult for the policies to generalize outside of the training data. In this work, we present a method for learning to solve new tasks by piecing together parts of training tasks that the robot has already seen in the demonstration data.
A Motivating Example
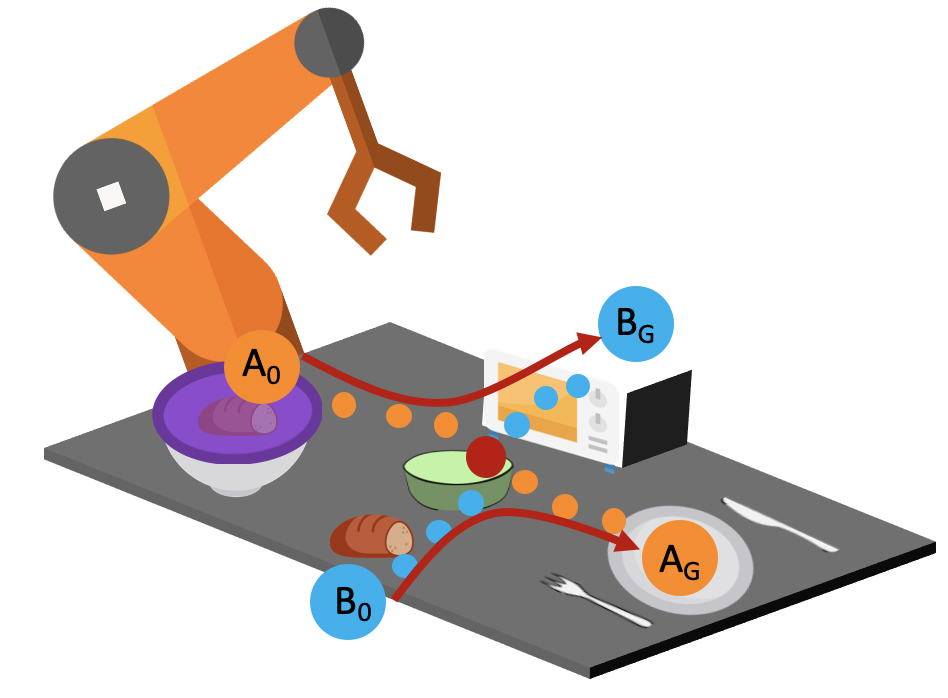
Consider the setup shown below. In the first task, the bread starts in the container, and the robot needs to remove the purple lid, retrieve the bread, put it into this green bowl, and then serve it on a plate.


In the second task, the bread starts on the table, and it needs to be placed in the green bowl and then put into the oven for baking.


We provide the robot with demonstrations of both tasks. Note that both tasks require the robot to place the bread into this green bowl! In other words, these task trajectories intersect in the state space! The robot should be able to generalize to new start and goal pairs by choosing different paths at the intersection, as shown in the picture. For example, the robot could retrieve the bread from the container and place the bread into the oven, instead of placing it on the plate.
In summary, our key insights are:
- Multi-task domains often contain task intersections.
- It should be possible for a policy to generate new task trajectories by composing training tasks via the intersections.
Generalization Through Imitation
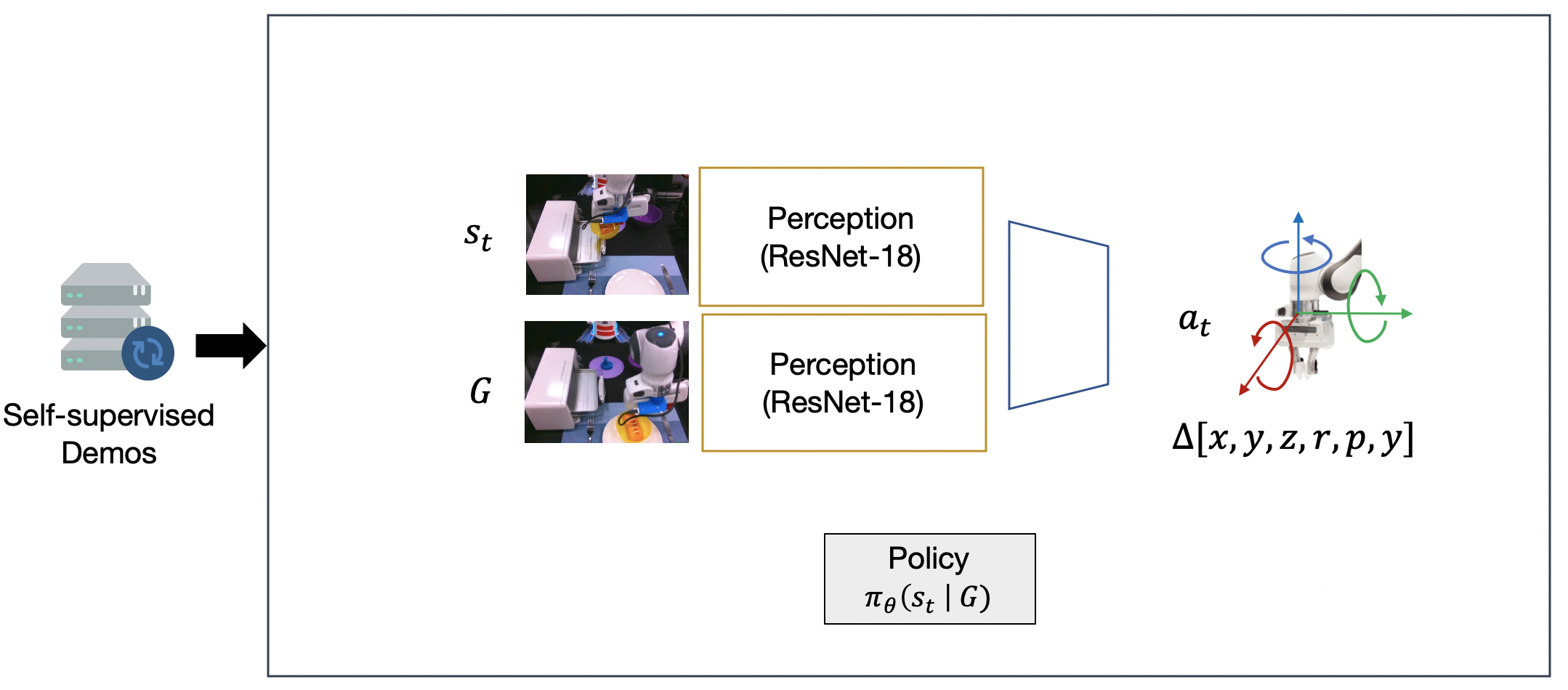
In this work, we introduce Generalization Through Imitation (GTI), a two-stage algorithm for enabling robots to generalize to new start and goal pairs through compositional imitation.
- Stage 1: Train policies to generate diverse (potentially new) rollouts from human demonstrations.
- Stage 2: Use these rollouts to train goal-directed policies to achieve targeted new behaviors by self-imitation.
Generating Diverse Rollouts from Human Demonstrations
In Stage 1, we would like to train policies that are able to both reproduce the task trajectories in the data and also generate new task trajectories consisting of unseen start and goal pairs. This can be challenging – we need to encourage our trained policy to understand how to stop following one trajectory from the dataset and start following a different one in order to end up in a different goal state.
Here, we list two core technical challenges.
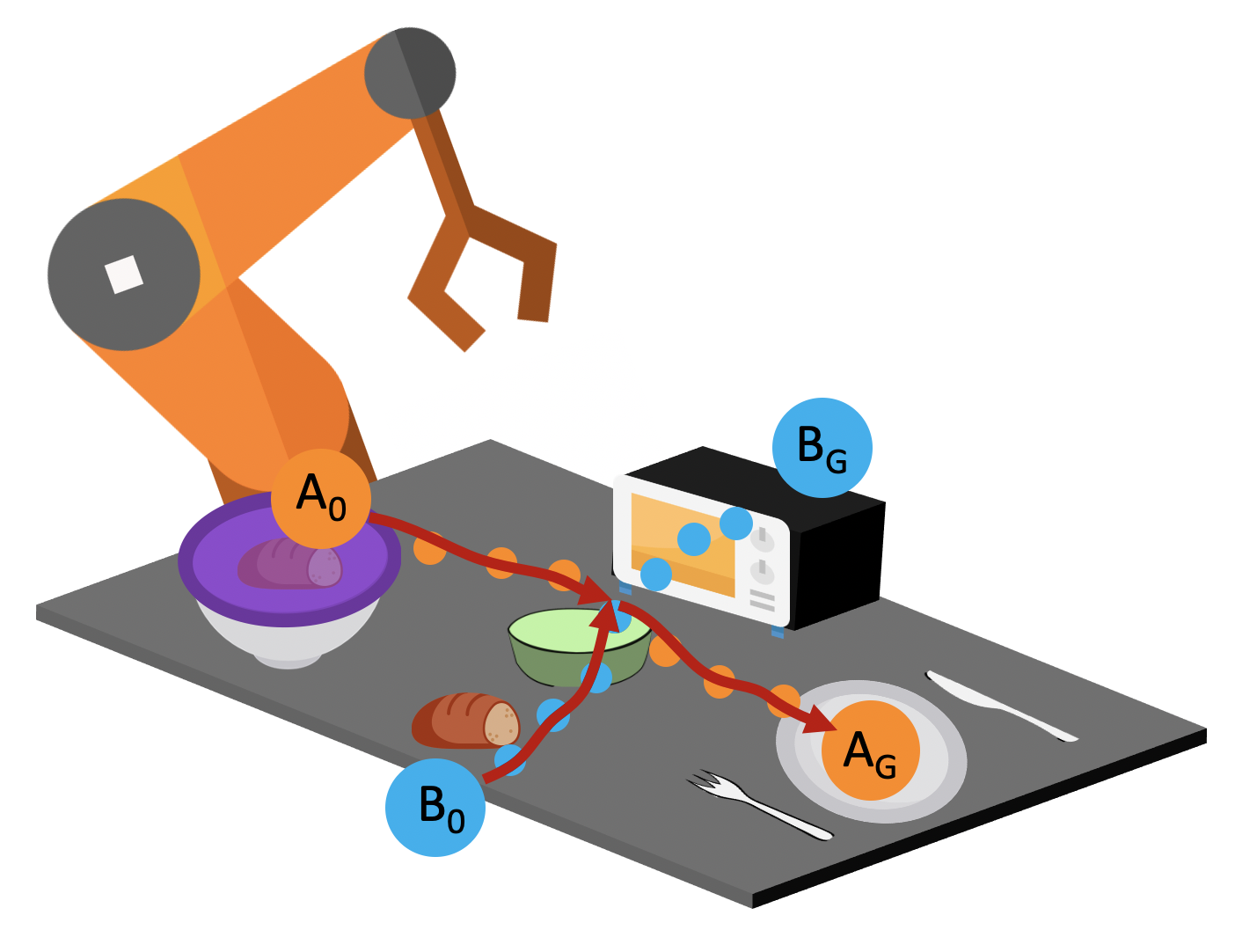
- Mode Collapse. If we naively train imitation learning policies on the demonstration data of the two tasks, the policy tends to only go to a particular goal regardless of the initial states, as indicated by the red arrows in the picture below.
- Spatio-temporal Variation There is a large amount of spatio-temporal variation from human demonstrations on a real robot that must be modeled and accounted for.
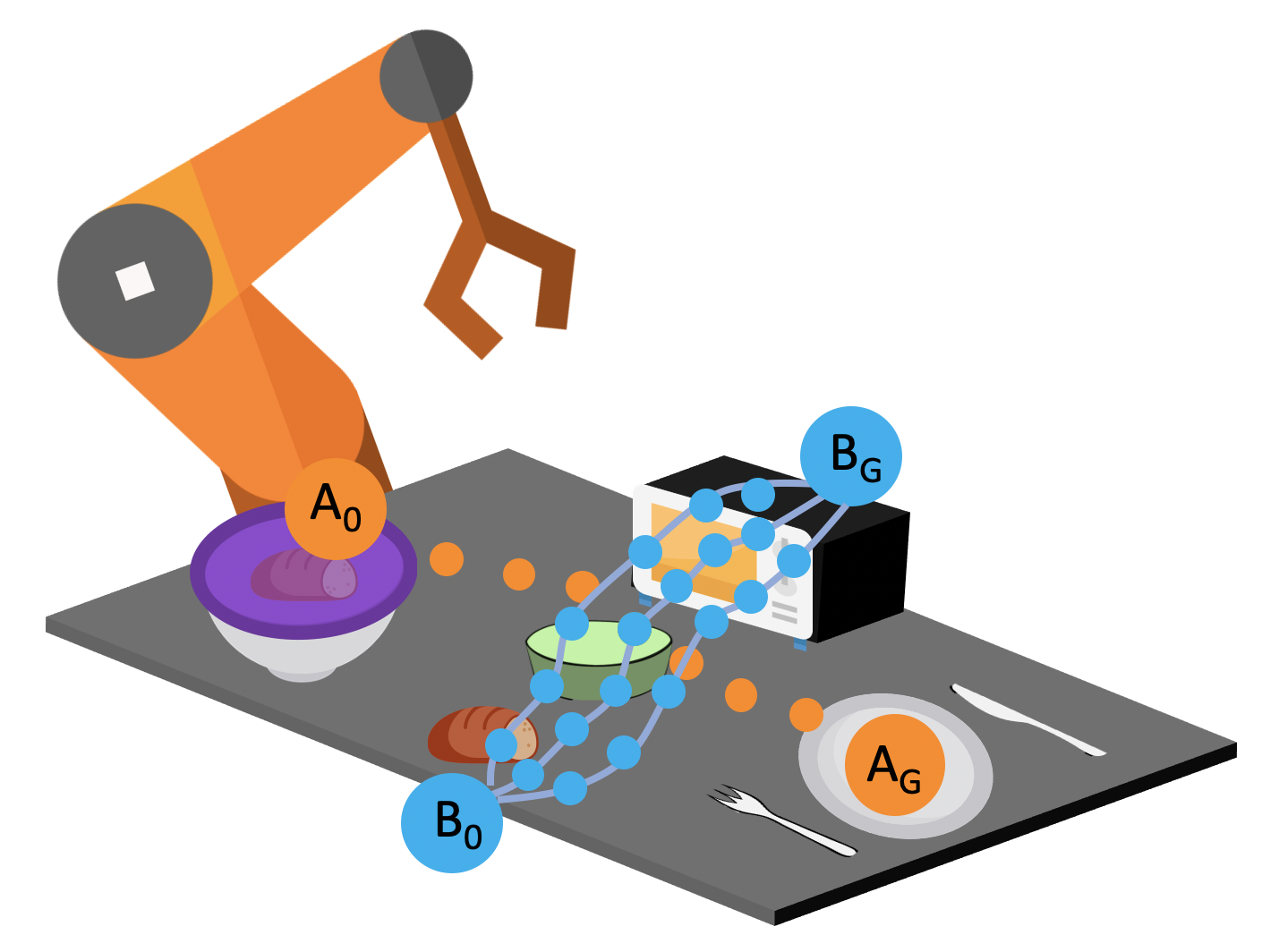
In order to get a better idea of how to encourage a policy to generate diverse rollouts, let’s take a closer look at the task space. The left image in the figure below shows the set of demonstrations. Consider a state near the beginning of a demonstration, as shown in the middle image. If we start in this state, and try to set a goal for our policy to achieve, according to the demonstration data, the goals can be modeled by a gaussian distribution. However, if we start at the intersection, the goal could spread across two tasks. It would be better for us to model the goal distributions with a multi-modal gaussian.
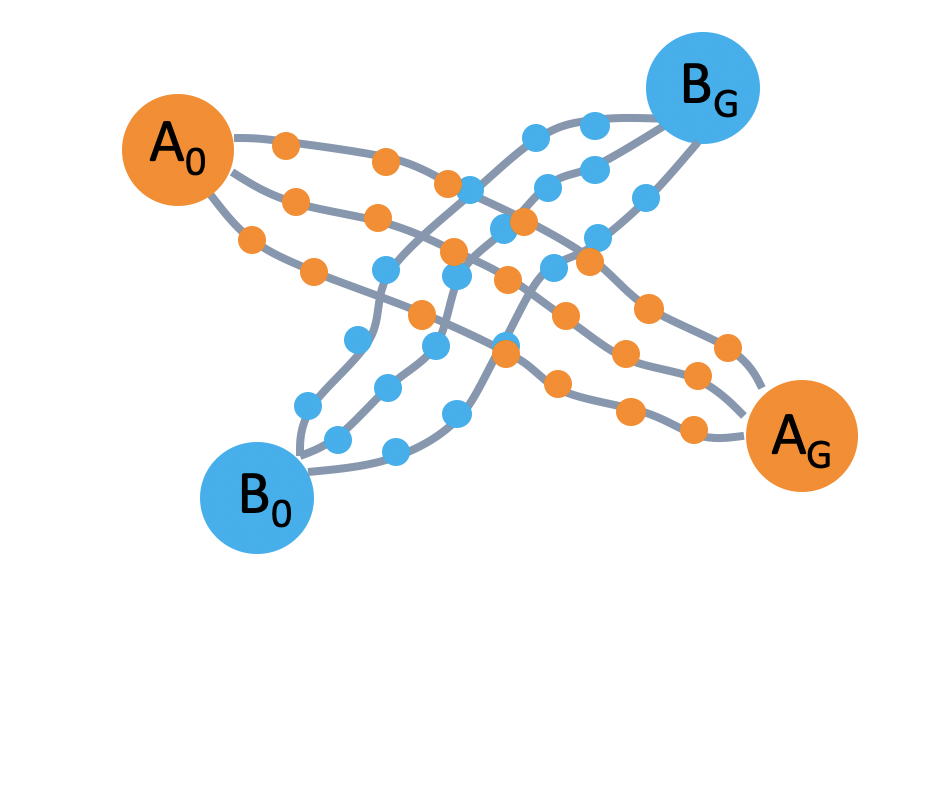
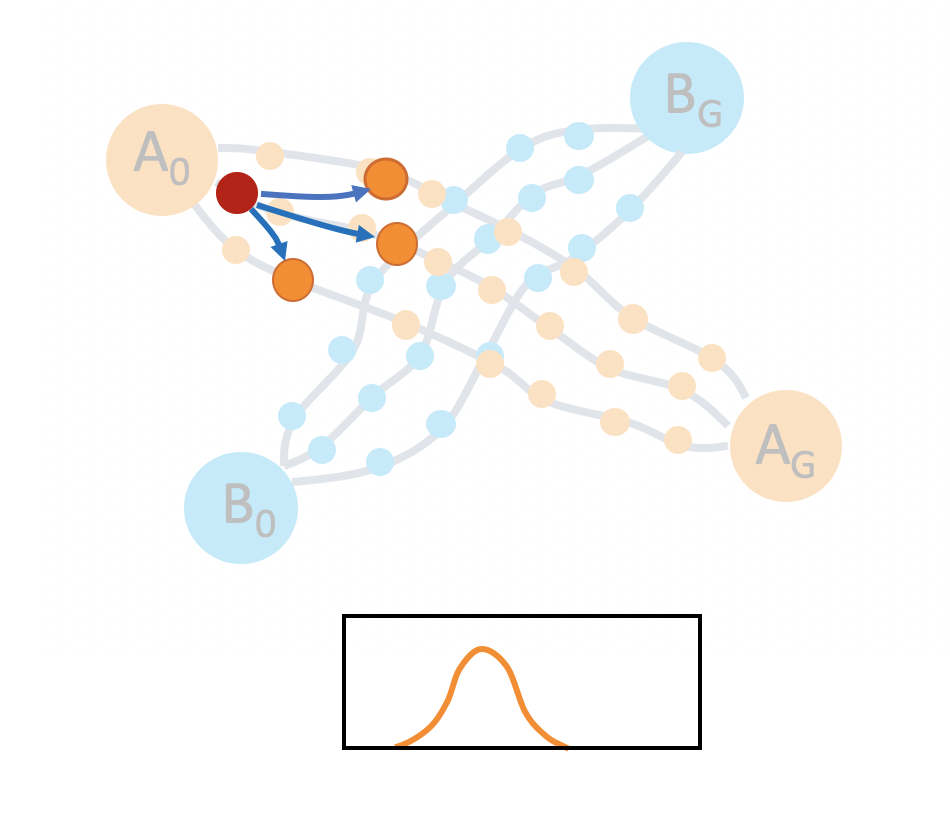
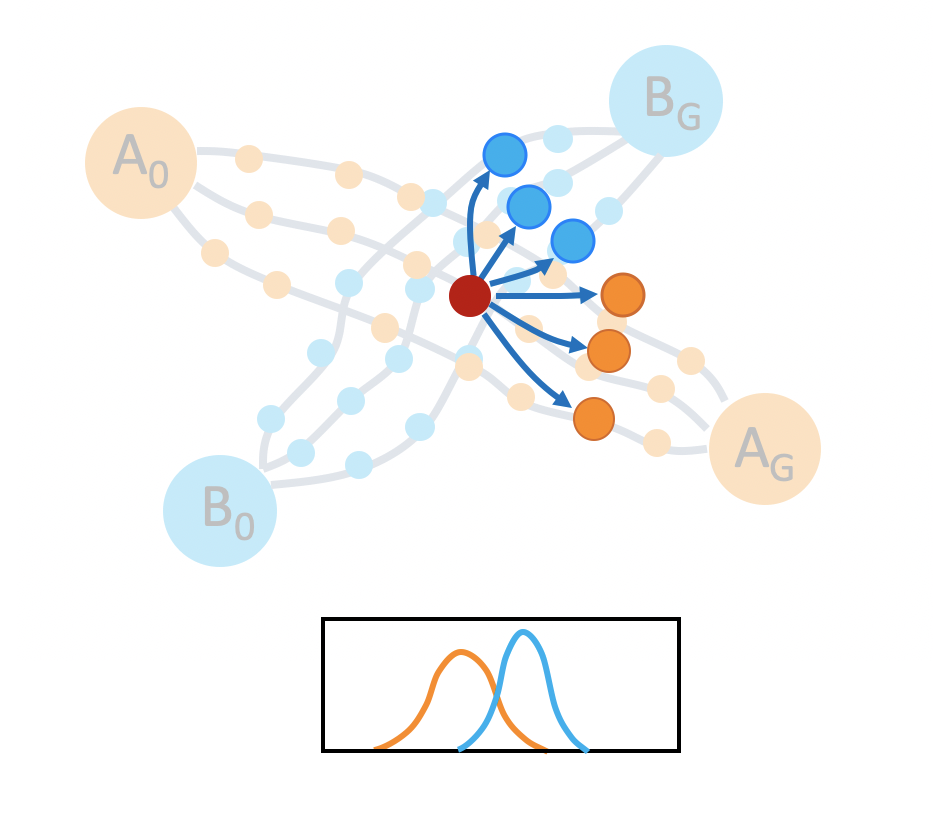
Based on this observation, we design a hierarchical policy learning algorithm, where the high-level policy captures distribution of future observations in a multimodal latent space. The low-level policy conditions on the latent goal to fully explore the space of demonstrations.
GTI Algorithm Details
Let’s take a closer look at the learning architecture for our Stage 1 policy, shown below. The high-level planner is a conditional variational autoencoder4, that attempts to learn the distribution of future image observations conditioned on current image observations. The encoder encodes both a current and future observation into a latent space. The decoder attempts to reconstruct the future observation from the latent. The latent space is regularized with a learned Gaussian mixture model prior. This prior encourages the model to a latent multimodal distribution of future observations. We can think of this latent space as modeling short-horizon subgoals. We train our low-level controller to imitate actions in the dataset that lead to particular subgoals.
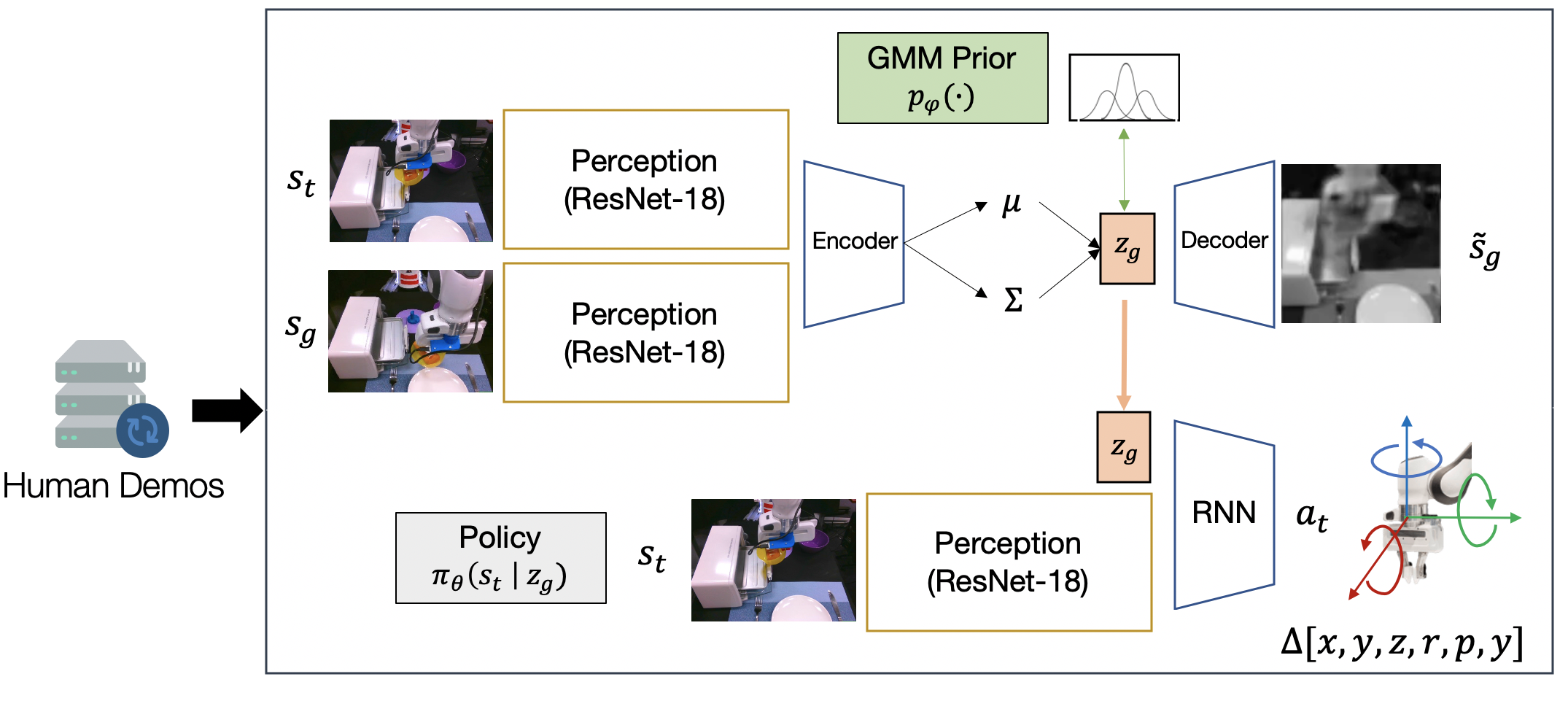
Next, we use the Stage 1 policy to collect a handful of self-generated diverse rollouts, shown below. Every 10 timesteps, we sample a new latent subgoal from the GMM prior, and use it to condition the low-level policy. The diversity captured in the GMM prior ensures that the Stage 1 policy will exhibit different behaviors at trajectory intersections, resulting in novel trajectories with unseen start and goal pairs.
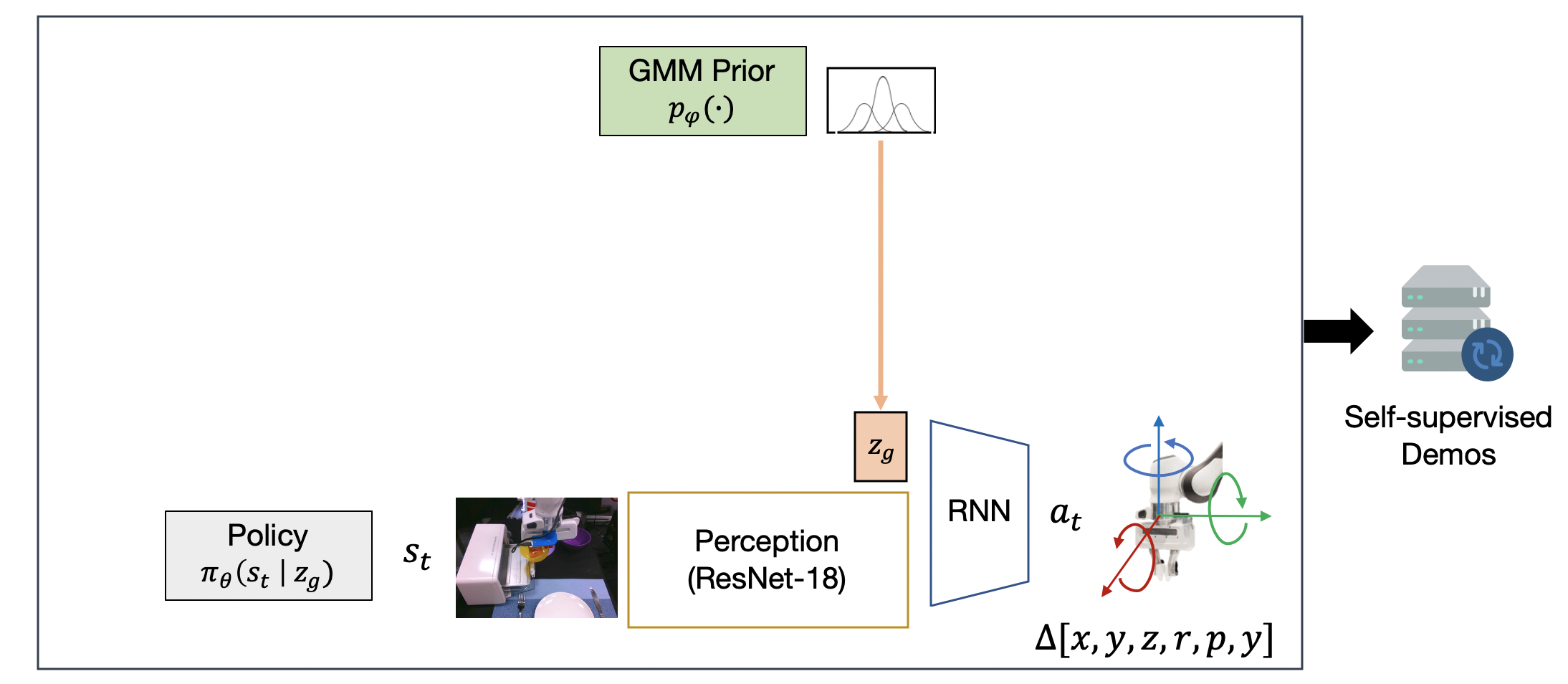
Finally, the self-generated dataset is used to train a new, goal-directed policy that can perform intentional behaviors from these undirected rollouts.
Real Robot Experiments
Data Collection
This is our hardware setup. We used a Franka robotic arm and two cameras for data collection – a front view camera and a wrist-mounted camera.
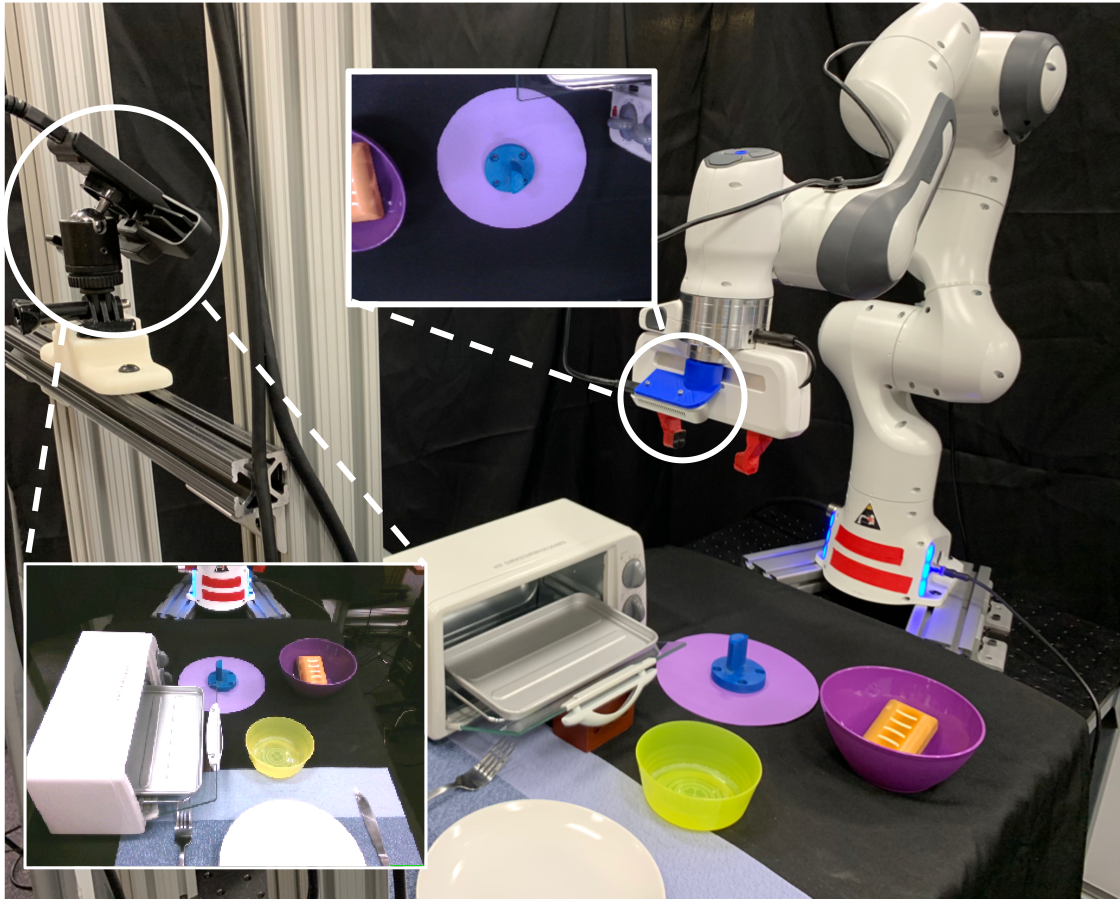
We used the RoboTurk phone teleoperation interface56 to collect human demonstrations. We collect only 50 demonstrations for each of the two tasks. The data collection took less than an hour.
Results
Below, we show the final trained Stage 2 model. We ask the robot to start from the initial state of one task, bread-in-container, and reach the goal of the other task, which is to put the bread in the oven. The goal is specified by providing an image observation that shows the bread in the oven. We emphasize that the policy is performing closed-loop visuomotor control at 20hz purely from image observations. Note that this task requires accurate contact-rich manipulations, and is long-horizon. With only visual information, our method can perform intricate tasks such as grasping, pushing the oven tray into the oven, or manipulating a constrained mechanism like closing door of the oven.
Our Stage 1 policy can recover all start and goal combinations, including both behavior seen in training and new unseen behaviors.
Finally, we show that our method is robust towards unexpected situations. In the case below (left), the policy is stuck because of conflicting supervisions. Sampling latent goals allows the policy to get unstuck and complete the task successfully. Our policy is also very reactive and can quickly recover from errors. In the case below (right), the policy failed to grasp the bread twice, and finally succeeded the third time. It also made two attempts to get a good grasp of the bowl, and complete the task successfully
Summary
- Imitation learning is an effective and safe technique to train robot policies in the real world because it does not depend on an expensive random exploration process. However, due to the lack of exploration, learning policies that generalize beyond the demonstrated behaviors is still an open challenge.
- Our key insight is that multi-task domains often present a latent structure, where demonstrated trajectories for different tasks intersect at common regions of the state space.
- We present Generalization Through Imitation (GTI), a two-stage offline imitation learning algorithm that exploits this intersecting structure to train goal-directed policies that generalize to unseen start and goal state combinations.
- We validate GTI on a real robot kitchen domain and showcase the capacity of trained policies to solve both seen and unseen task configurations.
This blog post is based on the following paper:
- “Learning to Generalize Across Long-Horizon Tasks from Human Demonstrations” by Ajay Mandlekar*, Danfei Xu*, Roberto Martin-Martin, Silvio Savarese, and Li Fei-Fei.
-
Quillen, D., Jang, E., Nachum, O., Finn, C., Ibarz, J., & Levine, S. (2018, May). Deep reinforcement learning for vision-based robotic grasping: A simulated comparative evaluation of off-policy methods. In 2018 IEEE International Conference on Robotics and Automation (ICRA) (pp. 6284-6291). IEEE. ↩
-
Cabi, S., Colmenarejo, S. G., Novikov, A., Konyushkova, K., Reed, S., Jeong, R., … & Sushkov, O. (2019). A Framework for Data-Driven Robotics. arXiv preprint arXiv:1909.12200. ↩
-
Zhang, T., McCarthy, Z., Jow, O., Lee, D., Chen, X., Goldberg, K., & Abbeel, P. (2018, May). Deep imitation learning for complex manipulation tasks from virtual reality teleoperation. In 2018 IEEE International Conference on Robotics and Automation (ICRA) (pp. 1-8). IEEE. ↩
-
Kingma, D. P., & Welling, M. (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114. ↩
-
Mandlekar, A., Zhu, Y., Garg, A., Booher, J., Spero, M., Tung, A., … & Savarese, S. (2018). Roboturk: A crowdsourcing platform for robotic skill learning through imitation. arXiv preprint arXiv:1811.02790. ↩
-
Mandlekar, A., Booher, J., Spero, M., Tung, A., Gupta, A., Zhu, Y., … & Fei-Fei, L. (2019). Scaling Robot Supervision to Hundreds of Hours with RoboTurk: Robotic Manipulation Dataset through Human Reasoning and Dexterity. arXiv preprint arXiv:1911.04052. ↩