
Posted by Christian Sager (Product Owner, Digitec Galaxus) and Anant Nawalgaria (ML Specialist, Google)
In the retail industry it is important to be able to engage and excite users by serving personalized content on newsletters at scale. It is important to do this in a manner which leverages existing trends, while exploring and unearthing potentially new trends with an even higher user engagement. This project was done as a collaboration between Digitec Galaxus and Google, by designing a system based on Contextual Bandits to personalize newsletters for more than 2 million users every week.
To accomplish this, we leveraged several products in the TensorFlow ecosystem and Google Cloud including TF Agents, TensorFlow Extended (TFX) running on Vertex AI , to build a system that personalizes newsletters in a scalable, modularized and cost effective manner with low latency. In this article, we’ll highlight a few of the pieces, and point you to resources you can use to learn more.
About Digitec Galaxus
Digitec Galaxus AG is the largest online retailer in Switzerland. It offers a wide range of products to its customers, from electronics to clothes. As an online retailer, we naturally make use of recommendation systems, not only on our home or product pages but also in our newsletters. We have multiple recommendation systems in place already for newsletters, and have been extensive early adopters of the Google Cloud recommendations AI. Because we have multiple recommendation systems and very large amounts of data, we are faced with the following complications.
1. Personalization
We have over 12 recommenders that it uses in the newsletters, however we would like to contextualize these by choosing different recommenders (which in turn select the items) for different users. Furthermore, we would like to exploit existing trends as well as experiment with new ones.
2. Latency
We would like to ensure that the ranked list of recommenders can be retrieved with sub 50 ms latency.
3. End-to-end easy to maintain and generalizable/modular architecture
We wanted the solution to be architected using an easy to maintain, platform invariant, complete with all MLops capabilities required to train and use contextual bandits models. It was also important to us that it is built in a modular fashion such that it can be adapted easily to other use cases which have in mind such as recommendations on the homepage, Smartags and more.
Before we get to the details of how we built a machine learning infrastructure capable of dealing with all requirements, we’ll dig a little deeper into how we got here and what problem we’re trying to solve.
Using contextual bandits
Digitec Galaxus has multiple recommendation systems in place already. Because we have multiple recommendation systems, it is sometimes difficult to choose between them in a personalized fashion. Hence we reached out to Google seeking assistance with implementing Contextual Bandit driven recommendations, which personalizes our homepage as well as our newsletter. Because we only send newsletters to registered users, we can incorporate features for every user.
We chose TFAgents to implement the contextual bandit model. Training and serving pipelines were orchestrated by Vertex AI pipelines running TFX, which in turn used TFAgents for the development of the contextual bandit models. Here’s an overview of our approach.
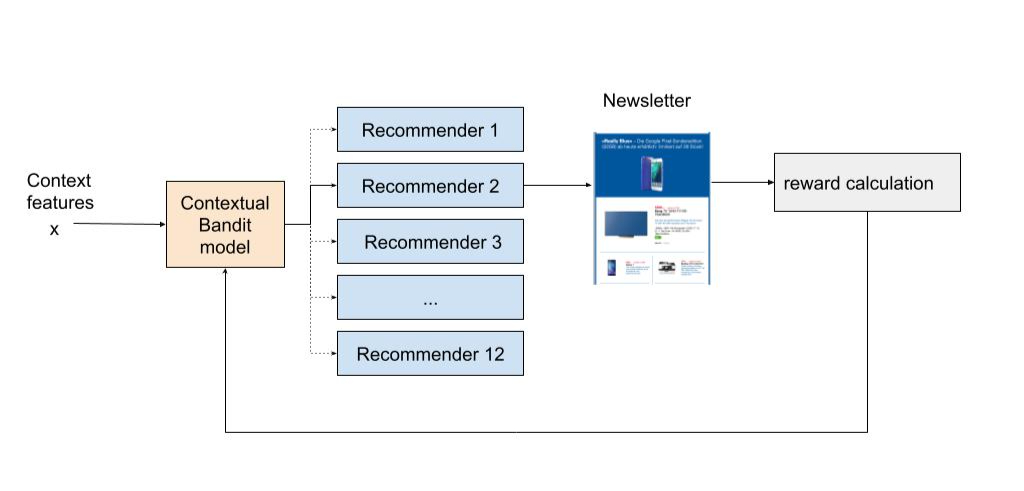
Rewarding subscribes, and penalizing unsubscribes
Given some features (context) about the user, and each of the 12 available recommenders, we aim to suggest best recommender (action) which increases the chance (reward) of the user clicking (reward = 1) on at least one of the recommendations by the selected recommender, and minimizes the chance of incurring a click which leads to unsubscribe (reward = -1).
By formulating the problem and reward function in this manner, we hypothesized that the system would optimize for increasing clicks, while still showing relevant (and not click-baity) content to the user in order to sustain the potential increase in performance. This is because the reward functions penalizes an event when a user unsubscribes, which a click-baity content is likely to lead to. The problem was then tackled by using contextual bandits because of the fact that they excel at exploiting trends that work well, as well as exploring and uncovering potentially even better-performing trends.
Serving millions of users every week with low latency
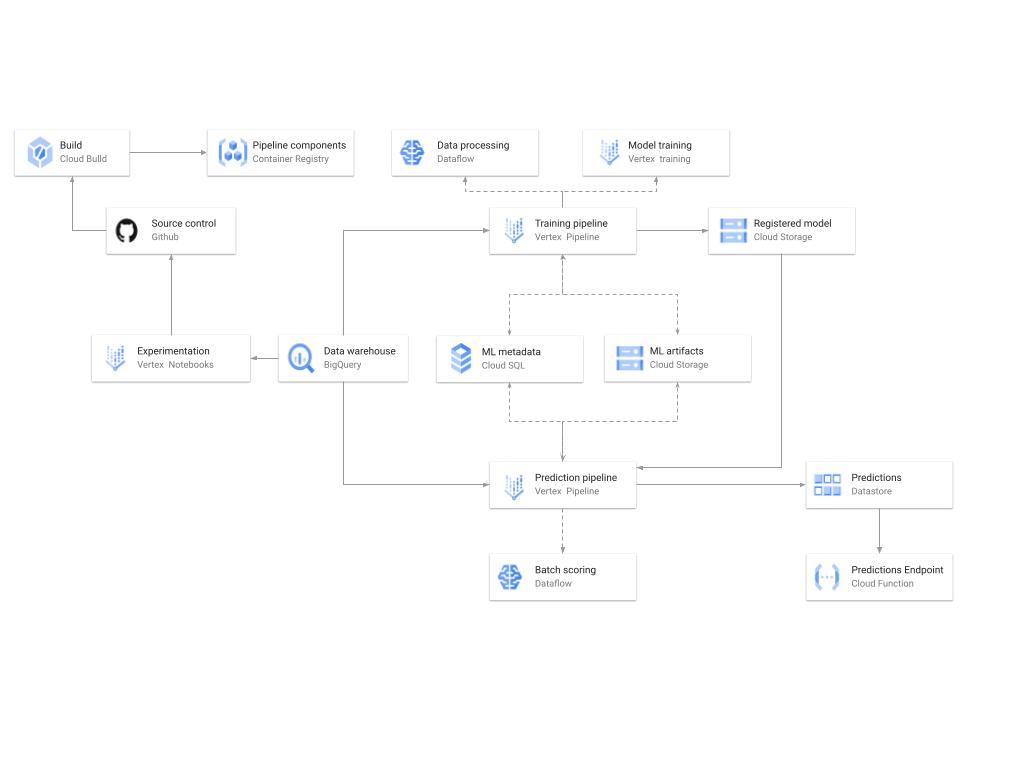 |
| A diagram showing the high-level architecture of the recommendation training and prediction systems on GCP. |
There’s a lot of detail here, as the architecture shown in the diagram covers three phases of ML development, training, and serving. Here are some of the key pieces.
Model development
Vertex Notebooks are used as data science environments for experimentation and prototyping, in addition to implementing model training and scoring components and pipelines. The source code is version controlled in GitHub. A continuous integration (CI) pipeline is set up to run unit tests, build pipeline components, and store the container images to Cloud Container Registry.
Training
The training pipeline is executed using TFX on Vertex Pipelines. In essence, the pipeline trains the model using new training data extracted from BigQuery, validates the produced model, and stores it in the model registry. In our system, the model registry is curated in Cloud Storage. The training pipeline uses Dataflow for large scale data extraction, validation, processing and model evaluation, as well as Vertex Training for large scale distributed training of the model. In addition, AI Platform Pipelines stores artifacts produced by the various pipeline steps to Cloud Storage, and information about these artifacts is stored in an ML metadata database in Cloud SQL.
Serving
Predictions are produced using a batch prediction pipeline, and stored in Cloud Datastore for consumption. The batch prediction pipeline is made using TFX and runs on Vertex Pipelines. The pipeline uses the most recent model in the model registry to score the serving queries from BigQuery. A Cloud Function is provided as a REST/HTTP endpoint to retrieve predictions from Datastore.
Continuous Training Pipeline
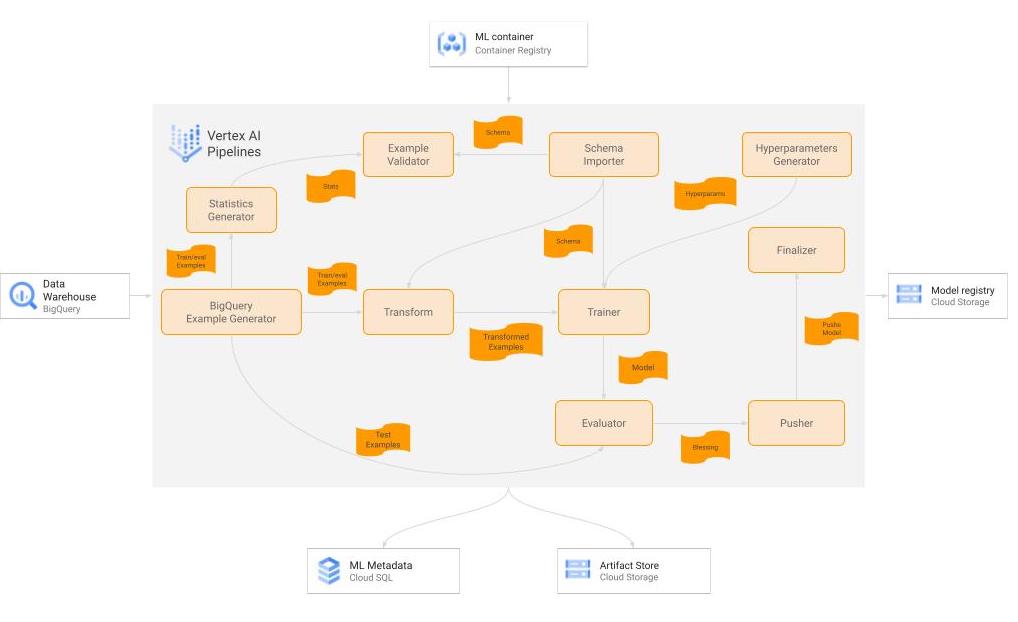 |
| A diagram of the TFX pipeline for the training workflow. |
There are many components used in our TFX-based Continuous training workflow, training is currently done on an on-demand basis, but later on it is planned to be executed on a bi-weekly cadence. Here is a little bit of detail on the important ones.
Raw Data
Our data consists of multiple datasets stored in heterogeneous formats across BigQuery tables and other formats, that are then joined in denormalized fashion by the customer into a single BigQuery table for training. To help avoid bias and drift in our model we train the model on a rolling window of 4 weeks cadence with one overlapping week per training cycle. This was a simple design choice as it was very straightforward to implement, as BigQuery has good compatibility as a source with TFX, and also allows the user to do some basic data preprocessing and cleaning during fetching.
BigQueryExampleGen
We first leverage BigQuery by leveraging built-in functions to preprocess the data. By embedding our own specific processes into the query calls made by the ExampleGen component, we were able to avoid building out a separate ETL that would exist outside the scope of a TFX pipeline. This ultimately proved to be a good way to get the model in production more quickly. This preprocessed data is then split into training and eval and converted to tf.Examples via the ExampleGen component.
Transform
This component does the necessary feature engineering and transformations necessary to handle strings, fill in missing values, log-normalize values, setup embeddings etc. The major benefit here is that the resulting transformation is ultimately prepended to the computational graph, so that the exact same code is used for training and serving. The Transform component runs on Cloud Dataflow in production.
Trainer
The Trainer component trains the model using TF-Agents. We leverage parallel training on Vertex Training to speed things up. The model is designed such that the user id passes in from the input to the output unaltered, so that it can be used as part of the downstream serving pipeline. The Trainer component runs on Vertex Training in production.
Evaluator
The Evaluator compares the existing production model to the model received by the Trainer and prepares the metrics required by the validator component to bless the “better” one for use in production. The model gating criteria is based on the AUC scores as well as counterfactual policy evaluation and possibly other metrics in the future. It is easy to implement custom metrics which meet the business requirements owing to the extensibility of the evaluator component. The Evaluator runs on Vertex AI.
Pusher
The Pusher’s primary function is to send the blessed model to our TFServing deployment for production. However, we added functionality to use the custom metrics produced in the Evaluator to determine decisioning criteria to be used in serving, and attach that to the computational graph. The level of abstraction available in TFX components made it easy to make this custom modification. Overall, the modification allows the pipeline to operate without a human in the loop so that we are able to make model updates frequently, while continuing to deliver consistent performance on metrics that are important to our business.
HyperparametersGen
This is a custom TFX component which creates a dictionary with hyperparameters (e.g., batch size, learning rate) and stores the dictionary as an artifact. The hyperparameters are passed as input to the trainer.
ServingModelResolver
This custom component takes a serving policy (which includes exploration) and a corresponding eval policy (without exploration), and resolves which policy will be used for serving.
Pushing_finalizer
This custom component copies the pushed/blessed model from the TFX artifacts directory to a curated destination.
The out-of-box components from TFX provided most of the functionality we require, and it is easy to create some new custom components to make the entire pipeline satisfy our requirements. There are also other components of the pipeline such as StatisticsGen (which also runs on Dataflow).
Batch Prediction Pipeline
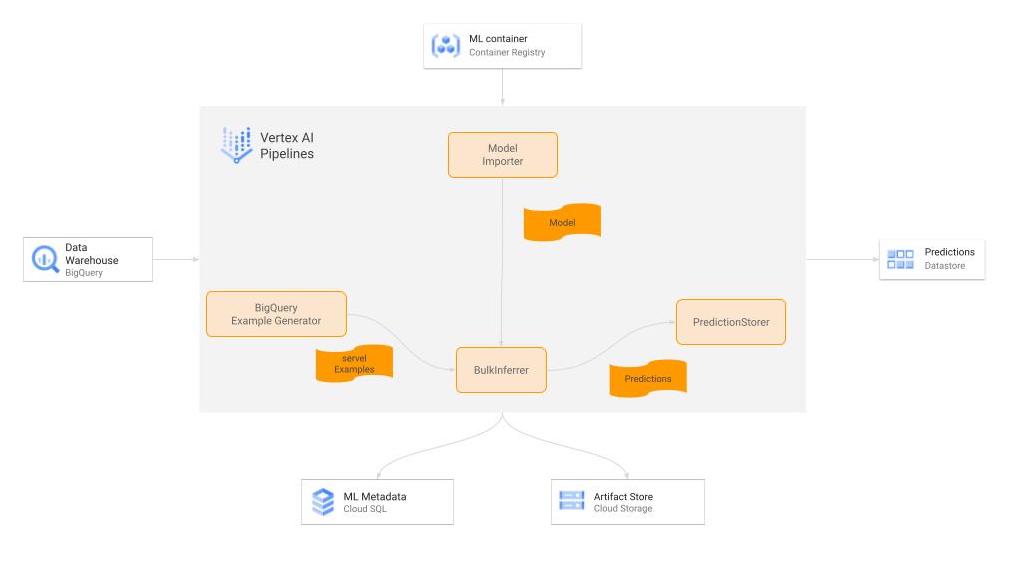 |
| A diagram showing the TFX pipeline for the batch prediction workflow. |
Here are a few of the key pieces of our batch prediction system.
Inference Dataset
Our inference dataset has nearly identical format to the training dataset, except that it is emptied and repopulated with new data daily.
BigQueryExampleGen
Just like for the Training pipeline, we use this component to read data from BigQuery and convert it into tf.Examples.
Model Importer
This component imports the computation graph exported by the Pusher component of the training pipeline. As mentioned above, since it contains the whole computation graph generated by the training pipeline, including feature transformation and the tf.Agents model (including the exploration/exploitation aspect), this is very portable and prevents train/test skew.
BulkInferrer
As the name implies, this component uses the imported computation graph to perform mass inference on the inference dataset. It runs on Cloud Dataflow in production and makes it very easy to scale.
PredictionStorer
This is a custom Python Component which takes the inference results from Bulkinfererrer, post-processes them to format/filter the fields as required, and persists it to Cloud Datastore. This runs on Cloud Dataflow in production as well.
Serving is done via cloud functions which take the user ids as input, and returns the precomputed results for each userId stored in DataStore with sub 50 ms latency.
Extending the work so far
In the few months since implementation of the first version we have been making dozens of improvements to the pipeline, everything from changing the architecture/approach of the original model, to changing the way the model’s results are used in the downstream application to generate newsletters. Moreover, each of these improvements brings new value to us more quickly than we’ve been able to in the past.
Since our initial implementation of this reference architecture, we have released a simple Vertex AI pipeline based github code samples to implementing recommender systems using TF Agents here. By using this template and guide, it will help them build recommender systems using contextual bandits on GCP in a scalable, modularized, low latency and cost effective manner. It’s quite remarkable how many of the existing TFX components that we have in place carry over to new projects, and even more so how drastically we’ve reduced the time it takes to get a model in production. As a result, even the software engineers on our team without much ML expertise feel confident in being able to reuse this architecture and adapt it to more use cases. The data scientists are able to spend more of their time optimizing the parameters and architectures of the models they produce, understanding their impact on the business, and ultimately delivering more value to the users and the business.
Acknowledgements
None of this would have been possible without the joint collaboration of the following Googlers: Khalid Salama, Efi Kokiopoulou, Gábor Bartók and Digitec Galaxus’s team of engineers.
A Google Cloud blog on this project can be found here.