Posted by Liu Huiyun, a senior algorithm engineer at NetEase
With the development of natural language processing (NLP) technology, Intelligent customer service has become an important use case in the e-commerce field. In recent years, this use case has received more and more attention. This is because, in the purchasing process, users need to be transferred to a customer services system for consultation and support if they encounter any problems or have questions. If the customer service system is able to provide accurate and effective responses, this will directly improve the user experience and have a positive impact on purchase conversion. For example:
- In pre-sales scenarios, users may ask for more detailed information about the products or promotional activities that they are interested in.
- In post-sales scenarios, users often have questions about returning and exchanging products, shipping fees, and logistics issues.
During actual business operations, NetEase Yanxuan, a large eCommerce platform in China, produces and accumulates large volumes of information, such as product attributes, activity operations, aftersales policies. In the meantime, the corresponding business logic is complicated. Intelligent customer service is an intelligent dialog system that leverages this information to automatically answer user questions or help human customer service representatives do so.
However, the e-commerce field involves many detailed and complicated business aspects, and users may ask their questions in many different ways and in a colloquial manner. These features require Intelligent customer service systems to possess strong semantic understanding. To this end, we have combined general customer scenarios with Yanxuan’s businesses and designed a deep learning based system. Check Yanxuan Intelligent customer service Framework full picture
- As a user inputs a question, the input text and its contextual information are first sent to the intent recognition (IR) module.
- The intent recognition module analyzes the user’s multi-layered intents and then distributes them to different sub-modules.
- The sub-modules are responsible for more targeted business Q&A, and different sub-modules apply different technical solutions.
As you can see, deep learning algorithms are applied to different modules in the framework. Because of the advanced NLP algorithms, we can extract more general and multi-granular semantic information from the user’s utterance.
Figure 3 shows the Xiaoxuan bot answering questions in a real dialog scenario. Next, I will introduce the different sub-modules that apply deep learning technology.
 |
| Figure 3. Online Conversation Example |
Intent Recognition Module — Multilayer Classification Model
As the user inputs text, we use a multilayer classification intent recognition model built with TensorFlow to analyze the input text, its context, and the historical behavior of the user. We divide first-level intents into four main categories: pre-sales product questions, aftersales questions, casual chatting, and the rest. When users ask common policy-related a ftersales questions, the input is summarized into more detailed sub-level intents. Click here (Figure 4) to check the structure of the intent recognition process.
In essence, intent recognition can be viewed as a classification problem. When building a classification system, we use the Attention+BiLSTM (ABL) model structure as a preliminary baseline. Except for the raw input text, we further design more features fed to the deep model, such as n-grams and positional encoding in the Transformer model. Ultimately, more manually crafted features improves the model accuracy by three percentage points. In addition, we also use a fine-tuned BERT model to train a classification model with less labeled data, and it performs as good as an ABL model. Pretrained models have better generalization, and can learn more semantic information based on fewer labeled data. However, this approach requires more computing resources.
FAQ Module — Text Matching Model
Answering FAQs is a key function of Intelligent customer service systems. This module is composed of two components, recall and re-rank.
- The recall stage adopts discrete searches at the word granularity as well as semantic searches based on dense sentence vectors.
- The re-rank stage uses a text matching model built with TensorFlow to re-rank the recalled candidature Q&A pairs.
- Then, filter by the final mixed strategies, the module returns the final answer.
In the automatic Q&A field, text matching algorithms are commonly applied to sentence similarity task and natural language inference task. From the most basic Siamese-LSTM networks, the structure of matching modules has evolved through InferNet, Decomposable Attention, ESIM, and finally to BERT models. Generally speaking, matching algorithms can be categorized into two kinds, one is representation-based and the other is interaction-based. Representation methods are focused on the encoding of single sentences, regardless of the interactive semantics between sentences which is used in interaction methods.
At the service layer, we adopt a variety of question matching solutions:
- Perform association matching between input question Q and answer A.
- Perform similarity matching between input question Q₁ and standard question Q₂.
- Perform similar question matching between input question Q and standard question Qs.
These three methods perform question relevance recall and Q&A association matching in different ways. In the match and rank stages, we can use flexible weighted discrimination.
We built a Siamese-LSTM model to use as our baseline model and then implemented the following model iteration solutions:
- We converted the LSTM units into the encoders of the Transformer model and replaced the cosine distance characterization module with the sentence-pair vector feature:
 to connect to the MLP layer.
to connect to the MLP layer. - We integrated an ESIM model with ELMo features.
- We fine tuned the BERT model.
Tests showed that these optimizations improved these models. For example, the encoders of the Transformer model showed better accuracy in tasks (1) and (3), increasing performance by nearly 5 percentage points.
In addition, we found that, without any additional feature construction or techniques, BERT could provide stable and outstanding matching performance. This is because, in the pretraining stage, BERT aims to predict whether a contextual relationship exists between two sentences, so it can learn the relationships between sentences. In addition, the self-attention mechanism is adept at capturing deep semantics and can obtain fine-grained matching results for a word in sentence A and any word in sentence B. This is crucial for text matching tasks.
KBQA Module — NER Module
In the product knowledge-base Q&A (KBQA) and shopping guide modules, we built a named-entity recognition (NER) model for the e-commerce field based on TensorFlow. The model can recognize product names, product attribute names, product attribute values, and other key product information in the questions asked by users, as shown in Figure 5. Then, entity names are sent to downstream modules, where Q&A knowledge graph techniques are used to generate a final answer.
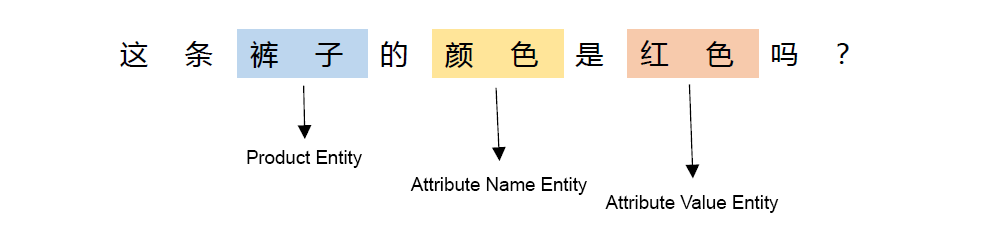 |
| Figure 5. E-commerce NER Example |
Generally, NER algorithm models use a bidirectional LSTM with a Conditional Random Field (CRF) layer. The former captures the before and after features, understands the context, and fully extracts contextual information. The latter focuses on the probabilistic transfer constructed from the local and global features of the current dialogue text, effectively mining the semantic information of the text. Yanxuan uses a BiLSTM-CRF model as a word-granularity baseline model, which serves the Intelligent customer service system. In later experiments, we tested feature extraction and fine-tuned BERT models.
In bert-based model optimization, we tried to use bert to extract sentence vector features and incorporate them into bilstm and crf, as well as two methods of bert-based fine-tuning: the last layer of embedding prediction, and the embedding method of weighted hidden layers. On the test set, the feature fusion performed best, with F1 as high as 0.92, followed by the multi-hidden layer fusion method (0.90), and finally the single high-layer method (0.88). In terms of the time efficiency of online inference, feature fusion takes about 100ms, and fine-tuning the model takes about 10ms.
The performance results using Yanxuan’s dataset are shown in Table 1. These results tell us the following:
- Feature extraction provides better performance than fine tuning. In addition to using BiLSTM for semantic and structure information extraction, by introducing BERT features into a feature extraction model, we obtain a wider range of semantic and structural representations. The performance boost obtained by adding additional parameters, as in feature extraction, is significantly higher than that of normal fine tuning.
- Multilayer feature fusion provides better performance than high-level features. This is because, for sequence tagging tasks, we need to consider both the semantic representation and the fusion of other granular representations of the sentence, such as syntactic structure information.
- In terms of response time, feature extraction, which adds additional parameters, is well-suited to offline systems, but cannot meet the needs of online systems. Fine-tuned models, however, can meet the timeliness requirements of online systems.
Casual Chat Module — Generative Model
A standalone customer service bot must be able to answer difficult questions from users. At the same time, it must also have the ability to chat casually so as to demonstrate both its humanity and intelligence.
To give our bot this capability, we built a casual chat module capable of handling routine chatting. This module includes two key models: retrieval-based QA and generative QA.
- The retrieval-based QA model first recalls answers from a prepared corpus and then uses a text matching model to re-rank the answers.
- The generative QA model uses the Transformer generative model trained using TensorFlow’s tensor2tensor to generate responses in an end-to-end (E2E) manner.
However, a purely E2E approach to response generation is difficult to control. Therefore, we decided to fuse the two models in our online system to ensure more reliable responses.
Model Deployment
Figure 6 shows an online service flow based on the BERT model. Thanks to the open-source TensorFlow versions of language models such as BERT, only a small number of labeled samples need to be used to build various text models that feature high accuracy. Then, we can use GPUs to accelerate computation in order to meet the QPS requirements of online services. Finally, we can quickly deploy and launch the model based on TensorFlow Serving (TFS). Therefore, it is the support provided by TensorFlow that allows us to deploy and iterate online services in a stable and efficient manner.
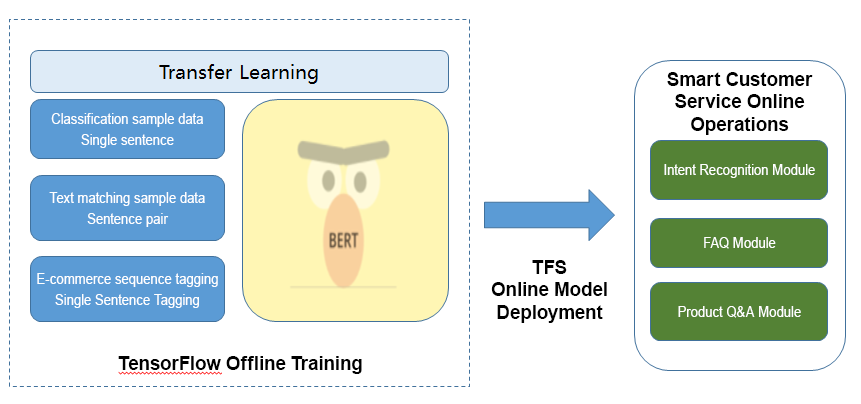 |
| Figure 6. BERT-based Online Service Flow |
Conclusion
As deep learning technology continues to develop, new models will make new breakthroughs in the NLP field. By continuing to apply academic advances in the industry, we can achieve outstanding business results. However, this would not be possible without the work of TensorFlow. In Yanxuan’s business scenarios, TensorFlow provides flexible and refined APIs that enables engineers to deal with agile development and test new models, greatly facilitating algorithm model iteration.