
Posted by Amandeep Singh (Vodafone), Max Vökler (Google Cloud)

Vodafone leverages Google Cloud to deploy AI/ML use cases at scale
As one of the largest telecommunications companies worldwide, Vodafone is working with Google Cloud to advance their entire data landscape, including their data lake, data warehouse (DWH), and in particular AI/ML strategies. While Vodafone has used AI/ML for some time in production, the growing number of use cases has posed challenges for industrialization and scalability. For Vodafone, it is key to rapidly build and deploy ML use cases at scale in a highly regulated industry. While Vodafone’s AI Booster Platform – built on top of Google Cloud’s Vertex AI – has provided a huge step to achieve that, this blog post will dive into how TensorFlow Data Validation (TFDV) helps advance data governance at scale.
High-quality Data is a Prerequisite for ML Use Cases, yet not Easily Achieved
Excelling in data governance is a key enabler to utilize the AI Booster Platform at scale. As Vodafone works in distributed teams and has shared responsibilities when developing use cases, it is important to avoid disruptions across the involved parties:
- Machine Learning Engineer at Vodafone Group level (works on global initiatives and provides best practices on productionizing ML at scale)
- Data Scientist in local market (works on a concrete implementation for their specific country, needs to ensure proper data quality and feature engineering)
- Data Owner in local market (needs to ensure data schemas do not change)
An issue that often arises is that table schemas are modified, or feature names and data types change. This could be due to a variety of reasons. For example, the data engineering process, which is owned by IT teams, is revised.
Data Contracts Define the Expected Form and Shape of Data
Data Contracts in machine learning are a set of rules that define the structure, data types, and constraints of the data that your models are trained on. The contracts provide a way to specify the expected schema and statistics of your data. The following can be included as part of your Data Contract:
- Feature names
- Data types
- Expected distribution of values in each column.
It can also include constraints on the data, such as:
- Minimum and maximum values for numerical columns
- Allowed values for categorical columns.
Before a model is productionized, the Contract is agreed upon by the stakeholders working on the pipeline, such as the ML Engineers, Data Scientists and Data Owners. Once the Data Contract is agreed upon, it cannot change. If a pipeline breaks due to a change, the error can be traced back to the responsible party. If the Contract needs amending, it needs to go to a review between the stakeholders, and once agreed upon, the changes can be implemented into the pipeline. This helps ensure the quality of data going into our model in production.
Vodafone Benefits from TFDV Data Contracts as a Way to Streamline Data Governance
As part of Vodafone’s efforts to streamline data governance, we made use of Data Contracts. A Data Contract ensures all teams work in unison, helping to maintain quality throughout the data lifecycle. These contacts are a powerful tool for managing and validating data used for machine learning. They provide a way to ensure that data is of high quality, free of errors and has the expected distribution. This blog post covers the basics of Data Contracts, discusses how they can be used to validate and understand your data better, and shows you how to use them in combination with TFDV to improve the accuracy and performance of your ML models. Whether you’re a data scientist, an ML engineer, or a developer working with machine learning, understanding Data Contracts is essential for building high-quality, accurate models.
How Vodafone Uses Data Contracts
Utilizing such a Data Contract, both in training and prediction pipelines, we can detect and diagnose issues such as outliers, inconsistencies, and errors in the data before they can cause problems with the models. Another great use of using Data Contracts is that it helps us detect data drift. Data drift is the most common reason for performance degradation in ML Models. Data drift is when the input data to your model changes to what it was trained on, leading to errors and inaccuracies in your predictions. Using Data Contracts can help you identify this issue.
Data Contracts are just one example of the many KPIs we have within Vodafone regarding AI Governance and Scalability. Since the development and release of AI Booster, more and more markets are using the platform to productionize their use case, and as part of this, we have the resources to scale components vertically. Examples of this, apart from Data Contracts, can be specialized logging, agreed-upon ways of calculating Model Metrics and Model Testing strategies, such as Champion/Challenger and A/B Testing.
How TensorFlow Data Validation (TFDV) Brings Data Contracts to Life
TFDV is a library provided by the TensorFlow team, for analyzing and validating machine learning data. It provides a way to check that the data conforms to a Data Contract. TFDV also provides visualization options to help developers understand the data, such as histograms and summary statistics. It allows the user to define data constraints and detect errors, anomalies, and drift between datasets. This can help to detect and diagnose issues such as outliers, inconsistencies, and errors in your data before they can cause problems with your models.
When you use TFDV to validate your data, it will check that the data has the expected schema. If there are any discrepancies, such as a missing column or a column with the wrong datatype, TFDV will raise an error and provide detailed information about the problem.
At Vodafone, before a pipeline is put into production, a schema is agreed upon for the input data. The agreement is between the Product Manager/Use Case Owner, Data Owner, Data Scientist and ML Engineer. The first thing we do in our pipeline, as seen in Figure 1, is to generate statistics about our data.
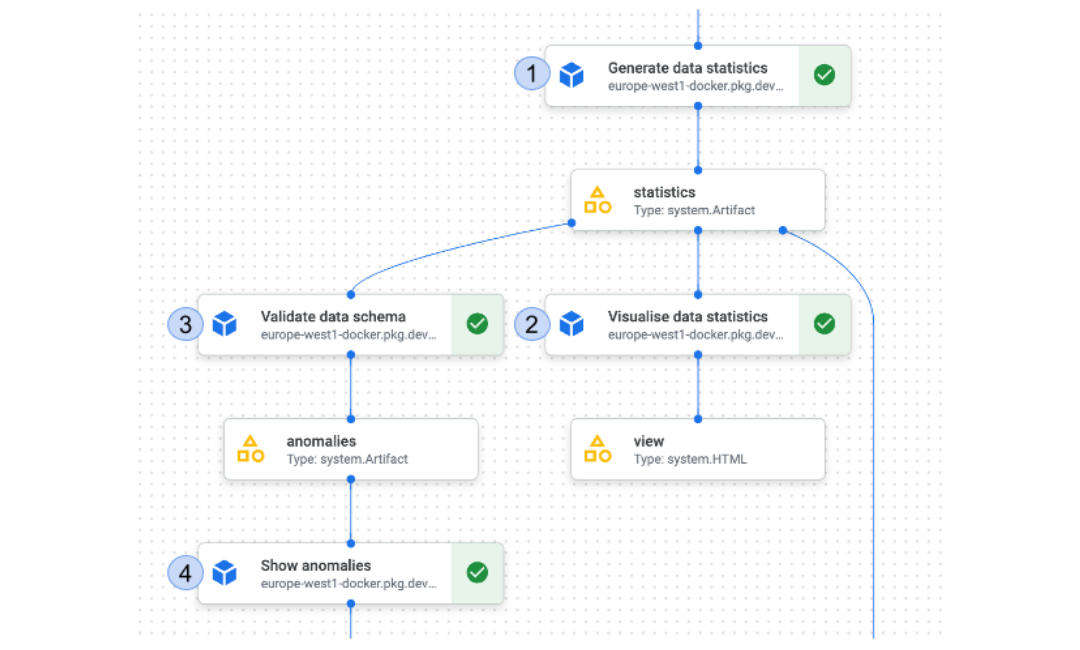 |
| Figure 1: Components of a Data Contract in a typical Vodafone training pipeline |
The code below uses TFDV to generate statistics for the training dataset and visualizes them (step 2), making it easy to understand the distribution of the data and how it’s been transformed. The output of this step is an HTML file, displaying general statistics about our input dataset. You can also choose a range of different functionalities on the HTML webpage to play around with the statistics and get a deeper understanding of the data.
# generate training statisticsgen_statistics = generate_statistics( dataset=train_dataset.output, file_pattern=file_pattern, ).set_display_name("Generate data statistics") # visualise statisticsvisualised_statistics = visualise_statistics( statistics=gen_statistics.output, statistics_name="Training Statistics").set_display_name("Visualise data statistics") |
Step 3 is concerned with validating the schema. Within our predefined schema, we also define some thresholds for certain data fields. We can specify domain constraints on our Data Contract, such as minimum and maximum values for numerical columns or allowed values for categorical columns. When you validate your data, TFDV will check that all the values in the dataset are within the specified domain. If any values are out of range, TFDV will provide a warning and give you the option to either discard or correct the data. There is also the possibility to specify the expected distribution of values in each feature of the Data Contract. TFDV will compute the actual statistics of your data, as shown in Figure 2, and compare them to the expected distribution. If there are any significant discrepancies, TFDV will provide a warning and give you the option to investigate the data further.
Furthermore, this allows us to detect outliers and anomalies in the data (step 4) by comparing the actual statistics of your data to the expected statistics. It can flag any data points that deviate significantly from the expected distribution and provide visualizations to help you understand the nature of the anomaly.
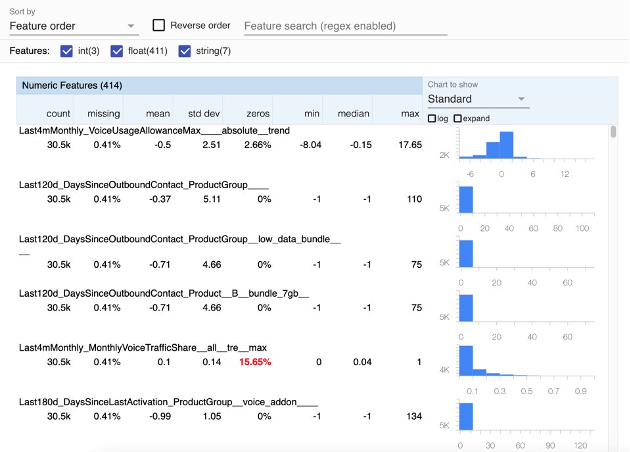 |
| Figure 2: Example visualization of the dataset statistics created by TFDV |
This code below is using the TFDV library to validate the data schema and detect any anomalies. The validate_schema function takes two arguments, statistics, and schema_path. Statistics argument is the output of a previous step which is generating statistics, and schema_path is the path to the schema file that was constructed in the first line. This function checks if the data conforms to the schema specified in the schema file.
# Construct schema_path from base GCS path + filenametfdv_schema_path = ( f"{pipeline_files_gcs_path}/{tfdv_schema_filename}") # validate data schemavalidated_schema = validate_schema( statistics=gen_statistics.output, schema_path=tfdv_schema_path ).set_display_name("Validate data schema") # show anomalies and fail if any anomalies were detectedanomalies = show_anomalies( anomalies=validated_schema.output, fail_on_anomalies=True).set_display_name("Show anomalies") |
The next block calls the show_anomalies function which takes two arguments, anomalies and fail_on_anomalies. The anomalies argument is the output of the previous validate_schema function, which includes the detected anomalies if any. The fail_on_anomalies argument is a flag that when set to true, will fail the pipeline if any anomalies are detected. This function will display the anomalies if any were detected, which looks something like this.
anomaly_info { key: "producer_used" value { description: "Examples contain values missing from the schema: Microsoft (<1%), Sony Ericsson (<1%), Xiaomi (<1%), Samsung (<1%), IPhone (<1%). " severity: ERROR short_description: "Unexpected string values" reason { type: ENUM_TYPE_UNEXPECTED_STRING_VALUES short_description: "Unexpected string values" description: "Examples contain values missing from the schema: Microsoft (<1%), Sony Ericsson (<1%), Xiaomi (<1%), Samsung (<1%), IPhone (<1%). " } path { step: "producer_used" } } } |
All the above components were developed internally using Custom KFP components and TFDV.
How Vodafone Industrialized the Approach on its AI Booster Platform
As part of the AI Booster platform, we have also provided templates for different Modeling Libraries such as XGBoost, TensorFlow, AutoML and BigQuery ML. These templates, which are based on Kubeflow Pipelines (KFP) pipelines, offer a wide range of customizable components that can be easily integrated into your machine learning workflow.
Our templates provide a starting point for our Data Scientists and ML Engineers, but they are fully customizable to fit their specific needs. However, we do enforce the inclusion of certain components in the pipeline when it is being productionized. As shown in Figure 1, we require that all production pipelines include Data Contract components. These components are not specific to a particular model and are intended to be used whenever data is being ingested for training or prediction.
Automating this step helps with our data validation process, making it more efficient and less prone to human error. It gives all stakeholders the confidence that whenever the model is in production, the data being used by the Model is always up to standard and not full of surprises. In addition, it helps with reproducibility of use cases in different markets, using local data. But most importantly it helps with Compliance and Privacy. It ensures us that our data is being used in compliance with company policies and regulations, and provides a framework for tracking and monitoring the usage of the data to make sure that it is being used appropriately.
Data Contracts with TFDV Helped Vodafone Industrialize their ML Workflow
Data Contracts play a critical role in ensuring the quality and integrity of the data used in machine learning models. Data Contracts provide:
- a set of rules and guidelines for how data should be collected, stored, and used, and help to ensure that the data is of high quality and free of errors
- a framework for identifying and resolving issues with the data, such as outliers, inconsistencies, and errors, before they can cause problems with the models
- a way to ensure compliance with company policies and regulations
- a way to trace back the origin and history of the data, which can be useful for auditing and troubleshooting purposes
They also help to ensure that the data is being used consistently and in a reproducible way, which can help to improve the accuracy and performance of the models and reduce the risk of errors and inaccuracies in the predictions. Data contracts used in conjunction with tools like TFDV help automate the data validation process, making it more efficient and less prone to human error. Applying this concept in AI Booster helped us at Vodafone to make a key step forward in industrializing our AI/ML use cases.
Find Out More
For more information about TFDV, see the user guide and tutorials on tensorflow.org. Special thanks to Amandeep Singh of Vodafone and Max Vökler of Google Cloud for their work to create this design and for writing this post.