Why simulation for AI?
We are living in a Golden Age of simulation environments in AI and robotics. Looking back ten years, simulation environments were rare, with only a handful of available solutions, and were complex and used only by experts. Today, there are many available simulation environments and most papers in AI and robotics at first tier conferences such as NeurIPS, CoRL or even ICRA and IROS, make some use of them. What has changed?

This extensive use of simulation environments is the result of several trends:
- First, the increasing role of machine learning in robotics creates a demand for more data (for example, interactive experiences) than what can be generated in real time 1234. Also, the initial data collection process often involves random exploration that may be dangerous for physical robots or their surroundings.
- Second, simulation environments have matured to be more robust, realistic (visually and physically), user friendly and accessible to all types of users, and the necessary computation to simulate complex physics is reasonably fast on most modern machines. Therefore, simulation environments have the potential to lower the barrier to entry in robotics, even for researchers without the funds to acquire expensive real robot platforms.
- Finally, the increasing number of robotic solutions to tasks such as grasping, navigation or manipulation have brought more attention to a critical absence in our community: the lack of repeatable benchmarks. Mature sciences are based on experiments that can be easily and reliably replicated, so that different techniques, theories, and solutions can be compared in fair conditions. Simulation environments can help us to establish repeatable benchmarks, which is very difficult to achieve with real robots, which can in turn help us understand the status of our field.

Why iGibson?
These ideas motivated us in the Stanford Vision and Learning Lab to develop a simulation environment that can serve as a “playground” to train and test interactive AI agents – an environment we call iGibson5. What makes iGibson special? To understand this, let’s first define what a simulation environment is and how it is different from a physics simulator. A physics simulator is an engine capable of computing the physical effect of actions on an environment (e.g. motion of bodies when a force is applied, or flow of liquid particles when being poured). There are many existing physics simulation engines. The best known in robotics are Bullet and its python extension, PyBullet, MuJoCo, Nvidia PhysX and Flex, UnrealEngine, DART, Unity, and ODE. Given a physical problem (objects, forces, particles, and physics parameters), these engines compute the temporal evolution of the system. On the other hand, a simulation environment is a framework that includes a physics simulator, a renderer of virtual signals, and a set of assets (i.e. models of scenes, objects, and robots) that can be used to create simulations of problems to study and develop solutions for different tasks. The decision on what physics engine to use is based on the type of physical process that dominates the problem, for example rigid body physics or motion of fluids. However, to decide on what simulation environment to use, researchers are guided by the application domain they are interested in, and the research questions they want to explore. With iGibson, we aim to support the study of interactive tasks in large realistic scenes, guided by high quality virtual visual signals.
Comparison to existing simulators
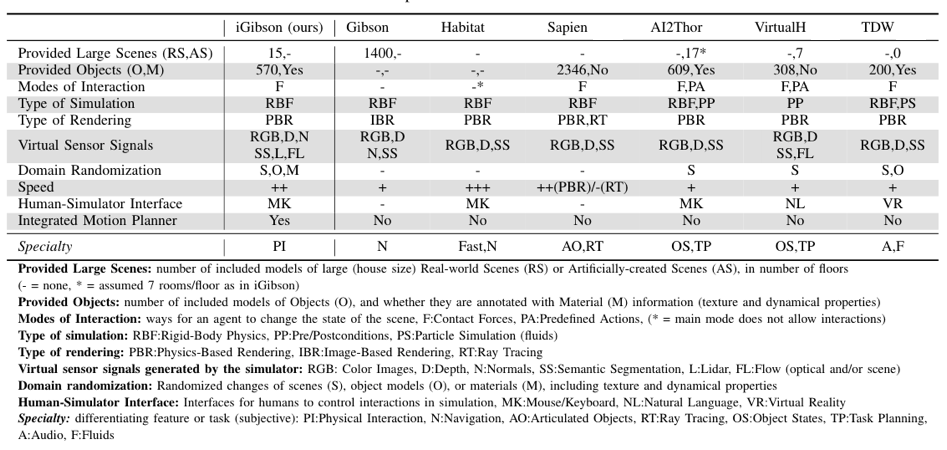
No existing simulation environments support developing solutions for problems involving interactions in large scale scenes like full houses. There are several simulation environments for tasks with stationary arms, such as meta-world, RLBench, RoboSuite or DoorGym, but none of them include large realistic scenes like homes with multiple rooms for tasks that include navigation. For navigation, our previous version, Gibson (v1) and Habitat have proven to be great environments that allow researchers to study visual and language guided navigation. However, the included assets (scenes) are single meshes that cannot change when interactions are applied, like opening doors or moving objects.
Finally, a set of recent simulation environments allow for scene-level interactive tasks, such as Sapien, AI2Thor and ThreeDWorld (TDW). Sapien focuses on interaction with articulated objects (doors, cabinets, and drawers). TDW is a multi-modal simulator with audio, high quality visuals, and simulation of flexible materials and liquids via Nvidia Flex. But neither Sapien nor TDW include fully interactive scenes aligned with real object distribution and layout as part of the environment. AI2Thor includes fully interactive scenes, but the interactions are scripted: interactable objects are annotated with the possible actions they can receive. When the agent is close enough to an object and the object is in the right state (precondition), the agent can select a predefined action, and the object is “transitioned’” to the next state (postcondition). RoboThor, an alternative version of AI2Thor, enables continuous interactions but focuses on navigation. It provides limited sensory signals to the agent (only RGB-D images) that is always embodied as a locobot, a low-cost platform with limited interaction capabilities. Here at SVL, we want to study complex, long-horizon mobile manipulation tasks such as tidying a house or searching for objects, which requires access to fully interactive realistic large-scale scenes.
iGibson’s new features
The main focus of iGibson in interactivity: enabling realistic interactions in large scenes. For that, we have included several key features:
- Fifteen fully interactive visually realistic scenes representing real world homes with furniture and articulated object models annotated with materials and dynamics properties.
- Capabilities to import models from CubiCasa5K 6 and 3D-Front 7, giving access to more than 8000 additional interactive home scenes.
- Realistic virtual sensor signals, including high quality RGB images from a physics-based renderer, depth maps, 1 beam and 16 beams virtual LiDAR signals, semantic/instance/material segmentation, optical and scene flow, and surface normals.
- Domain randomization for visual texture, dynamics properties and object instances for endless variations of scenes.
- Human-computer interface for humans to provide demonstrations of fully physical interactions with the scenes.
- Integration with sampling-based motion planners to facilitate motion of robotic bases (navigation in 2D layout) and arms (interaction in 3D space).




Using iGibson for robot learning
These novel features in iGibson allow us to study and develop solutions for new interactive tasks in large environments. One of these new problems is Interactive Navigation, where the agents need to interact with the environment to change its configuration, for example, to open doors or push obstacles away. This is a common type of navigation in our homes and offices, but non-interactive simulation environments cannot be used to study it. In iGibson we have developed hierarchical reinforcement learning solutions for interactive navigation that decide explicitly what part of the body to use in the next phase of the task: the arm (for interactions), the base (for navigation) or the combination of both 8. We also propose a new learning solution for interactive navigation that integrates a motion planner: the learning algorithm decides on the next point to interact, and the motion planner finds a collision free path to that point of interaction 9. But these are just the tips of the iceberg: many of SVL’s projects are leveraging iGibson to study a wide variety of interactive tasks in large realistic scenes.


Summary
Simulation environments have the potential to support researchers in their study of robotics and embodied AI problems. With iGibson, SVL contributes to the community with an open source, fully academically developed simulation environment for interactive tasks in large realistic scenes. If you want to start using it, visit our website and download – setup should be straightforward, and we’re happy to answer any questions about getting the simulator up and running for your research! We hope we can facilitate new avenues of research in robotics and AI.

-
Andrychowicz, OpenAI: Marcin, et al. “Learning dexterous in-hand manipulation.” The International Journal of Robotics Research 39.1 (2020): 3-20. ↩
-
Rajeswaran, Aravind, et al. “Learning complex dexterous manipulation with deep reinforcement learning and demonstrations.” Robotics: Science and Systems, 2017 ↩
-
Peng, Xue Bin, et al. “Sfv: Reinforcement learning of physical skills from videos.” ACM Transactions on Graphics (TOG) 37.6 (2018): 1-14. ↩
-
Zhu, Yuke, et al. “robosuite: A modular simulation framework and benchmark for robot learning.” arXiv preprint arXiv:2009.12293 (2020). ↩
-
A note on Gibson – Our simulation environment takes the name from James J. Gibson [1904-1979]. Gibson was an influential psychologist and cognitive scientist with, at the time, disruptive ideas. He pushed forward a new concept of perception to be considered 1) an ecological process that cannot and should not be studied in isolation from the environment, and 2) an active process that needs agency and interactivity. This was in contrast to the predominant view of the time of perception to be a passive process where signals “arrive” and “are processed” by the brain. Instead, he argued that agents seek for information, interacting and revealing it. He also coined the term “affordance” as the opportunity the environment offers to an agent to perform a task. This is a quote from a colleague summarizing his research that directly connects to the guiding principle behind our work in the iGibson team: “ask not what’s inside your head, but what your head is inside of”. ↩
-
Kalervo, Ahti, et al. “Cubicasa5k: A dataset and an improved multi-task model for floorplan image analysis.” Scandinavian Conference on Image Analysis. Springer, Cham, 2019. ↩
-
Fu, Huan, et al. “3D-FRONT: 3D Furnished Rooms with layOuts and semaNTics.” arXiv preprint arXiv:2011.09127 (2020). ↩
-
Li, Chengshu, et al. “Hrl4in: Hierarchical reinforcement learning for interactive navigation with mobile manipulators.” Conference on Robot Learning. PMLR, 2020. ↩
-
Xia, Fei, et al. “Relmogen: Leveraging motion generation in reinforcement learning for mobile manipulation.” arXiv preprint arXiv:2008.07792 (2020). ↩