Many of our AWS customers provide research, analytics, and business intelligence as a service. This type of research and business intelligence enables their end customers to stay ahead of markets and competitors, identify growth opportunities, and address issues proactively. For example, some of our financial services sector customers do research for equities, hedge funds, and investment management companies to help them understand trends and identify portfolio strategies. In the health industry, an increasingly large portion of health research is now information-based. A great deal of research entails the analysis of data that was initially collected for diagnostic, treatment, or for other research projects, and is now being used for new research purposes. These forms of health research have led to effective primary prevention to avoid new cases, secondary prevention for early detection, and prevention for better disease management. The research outcomes not only improve the quality of life but also help reduce healthcare expenses.
Customers tend to digest the information from public and private sources. They then apply established or custom natural language processing (NLP) models to summarize and identify a trend and generate insights based on this information. The NLP models used for these types of research tasks deal with large models and usually involve long articles to be summarized considering the size of the corpus—and dedicated endpoints, which aren’t cost-optimized at the moment. These applications receive a burst of incoming traffic at different times of the day.
We believe customers would greatly benefit from the ability to scale down to zero and ramp up their inference capability on as needed basis. This optimizes the research cost and still doesn’t compromise on quality of inferences. This post discusses how Hugging Face along with Amazon SageMaker asynchronous inference can help achieve this.
You can build text summarization models with multiple deep-learning frameworks like TensorFlow, PyTorch, and Apache MXNet. These models typically have a large input payload of multiple text documents of varying size. Advanced deep learning models require compute-intensive preprocessing before model inference. Processing times can be as long as a few minutes, which removes the option to run real-time inference by passing payloads over an HTTP API. Instead, you need to process input payloads asynchronously from an object store like Amazon Simple Storage Service (Amazon S3) with automatic queuing and a predefined concurrency threshold. The system should be able to receive status notifications and reduce unnecessary costs by cleaning up resources when the tasks are complete.
SageMaker helps data scientists and developers prepare, build, train, and deploy high-quality machine learning (ML) models quickly by bringing together a broad set of capabilities purpose-built for ML. SageMaker provides the most advanced open-source model-serving containers for XGBoost (container, SDK), Scikit-Learn (container, SDK), PyTorch (container, SDK), TensorFlow (container, SDK), and Apache MXNet (container, SDK).
- Real-time inference endpoints are suitable for workloads that need to be processed with low latency requirements in the order of ms to seconds.
- Batch transform is ideal for offline predictions on large batches of data.
- Amazon SageMaker Serverless Inference (in preview mode and not recommended for production workloads as of this writing) is a purpose-built inference option that makes it easy for you to deploy and scale ML models. Serverless Inference is ideal for workloads that have idle periods between traffic spurts and can tolerate cold starts.
- Asynchronous Inference endpoints queue incoming requests. They’re ideal for workloads where the request sizes are large (up to 1 GB) and inference processing times are in the order of minutes (up to 15 minutes). Asynchronous inference enables you to save on costs by auto scaling the instance count to zero when there are no requests to process.
Solution overview
In this post, we deploy a PEGASUS model that was pre-trained to do text summarization from Hugging Face to SageMaker hosting services. We use the model as is from Hugging Face for simplicity. However, you can fine-tune the model based on a custom dataset. You can also try out other models available in the Hugging Face Model Hub. We also provision an asynchronous inference endpoint that hosts this model, from which you can get predictions.
The asynchronous inference endpoint’s inference handler expects an article as input payload. The summarized text of the article is the output. The output is stored in the database for analyzing the trends or be fed downstream for further analytics. This downstream analysis derives data insights that help with the research.
We demonstrate how asynchronous inference endpoints enable you to have user-defined concurrency and completion notifications. We configure auto scaling of instances behind the endpoint to scale down to zero when traffic subsides and scale back up as the request queue fills up.
We also use Amazon CloudWatch metrics to monitor the queue size, total processing time, and invocations processed.
In the following diagram, we show the steps involved while performing inference using an asynchronous inference endpoint.
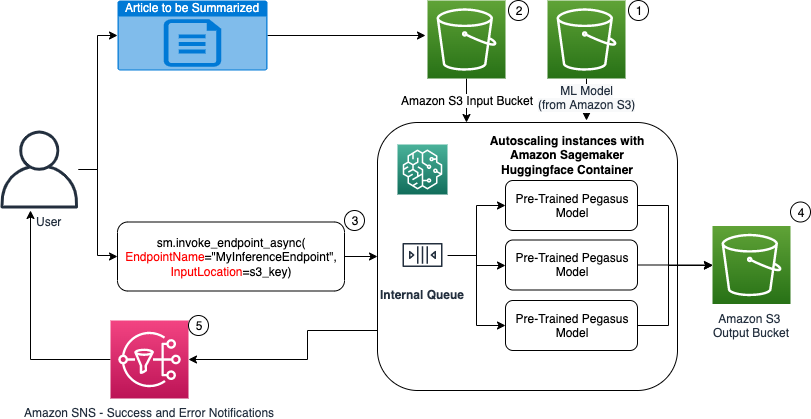
- Our pre-trained PEGASUS ML model is first hosted on the scaling endpoint.
- The user uploads the article to be summarized to an input S3 bucket.
- The asynchronous inference endpoint is invoked using an API.
- After the inference is complete, the result is saved to the output S3 bucket.
- An Amazon Simple Notification Service (Amazon SNS) notification is sent to the user notifying them of the completed success or failure.
Create an asynchronous inference endpoint
We create the asynchronous inference endpoint similar to a real-time hosted endpoint. The steps include creating a SageMaker model, followed by configuring the endpoint and deploying the endpoint. The difference between the two types of endpoints is that the asynchronous inference endpoint configuration contains an AsyncInferenceConfig section. Here we specify the S3 output path for the results from the endpoint invocation and optionally include SNS topics for notifications on success and failure. We also specify the maximum number of concurrent invocations per instance as determined by the customer. See the following code:
For details on the API to create an endpoint configuration for asynchronous inference, see Create an Asynchronous Inference Endpoint.
Invoke the asynchronous inference endpoint
The following screenshot shows a brief article that we use as our input payload:

The following code uploads the article as an input.json file to Amazon S3:
We use the Amazon S3 URI to the input payload file to invoke the endpoint. The response object contains the output location in Amazon S3 to retrieve the results after completion:
The following screenshot shows the sample output post summarization:

For details on the API to invoke an asynchronous inference endpoint, see Invoke an Asynchronous Inference Endpoint.
Queue the invocation requests with user-defined concurrency
The asynchronous inference endpoint automatically queues the invocation requests. This is a fully managed queue with various monitoring metrics and doesn’t require any further configuration. It uses the MaxConcurrentInvocationsPerInstance parameter in the preceding endpoint configuration to process new requests from the queue after previous requests are complete. MaxConcurrentInvocationsPerInstance is the maximum number of concurrent requests sent by the SageMaker client to the model container. If no value is provided, SageMaker chooses an optimal value for you.
Auto scaling instances within the asynchronous inference endpoint
We set the auto scaling policy with a minimum capacity of zero and a maximum capacity of five instances. Unlike real-time hosted endpoints, asynchronous inference endpoints support scaling down instances to zero by setting the minimum capacity to zero. We use the ApproximateBacklogSizePerInstance metric for the scaling policy configuration with a target queue backlog of five per instance to scale out further. We set the cooldown period for ScaleInCooldown to 120 seconds and the ScaleOutCooldown to 120 seconds. The value for ApproximateBacklogSizePerInstance is chosen based on the traffic and your sensitivity to scaling speed. The faster you scale in, the less cost you incur, but the more likely you’ll have to scale up again when new requests come in. The slower you scale in, the more cost you incur, but you’re less likely to have a request come in when you’re under-scaled.
For details on the API to auto scale an asynchronous inference endpoint, see the Autoscale an Asynchronous Inference Endpoint.
Configure notifications from the asynchronous inference endpoint
We create two separate SNS topics for success and error notifications for each endpoint invocation result:
Other options for notifications include periodically checking the output of the S3 bucket, or using S3 bucket notifications to initialize an AWS Lambda function on file upload. SNS notifications are included in the endpoint configuration section as previously described.
For details on how to set up notifications from an asynchronous inference endpoint, see Check Prediction Results.
Monitor the asynchronous inference endpoint
We monitor the asynchronous inference endpoint with built-in additional CloudWatch metrics specific to asynchronous inference. For example, we monitor the queue length in each instance with ApproximateBacklogSizePerInstance and total queue length with ApproximateBacklogSize.
For a complete list of metrics, refer to Monitoring Asynchronous Inference Endpoints.
We can optimize the endpoint configuration to get the most cost-effective instance with high performance. For example, we can use an instance with Amazon Elastic Inference or AWS Inferentia. We can also gradually increase the concurrency level up to the throughput peak while adjusting other model server and container parameters.
CloudWatch graphs
We simulated a traffic of 10,000 inference requests flowing in over a period to the asynchronous inference endpoint enabled with the auto scaling policy described in the previous section.
The following screenshot shows instance metrics before requests started flowing in. We start with a live endpoint with zero instances running:

The following graph showcases how the BacklogSize and BacklogSizePerInstance metrics change as the auto scaling kicks in and the load on the endpoint is shared by multiple instances that were provisioned as part of the auto scaling process.
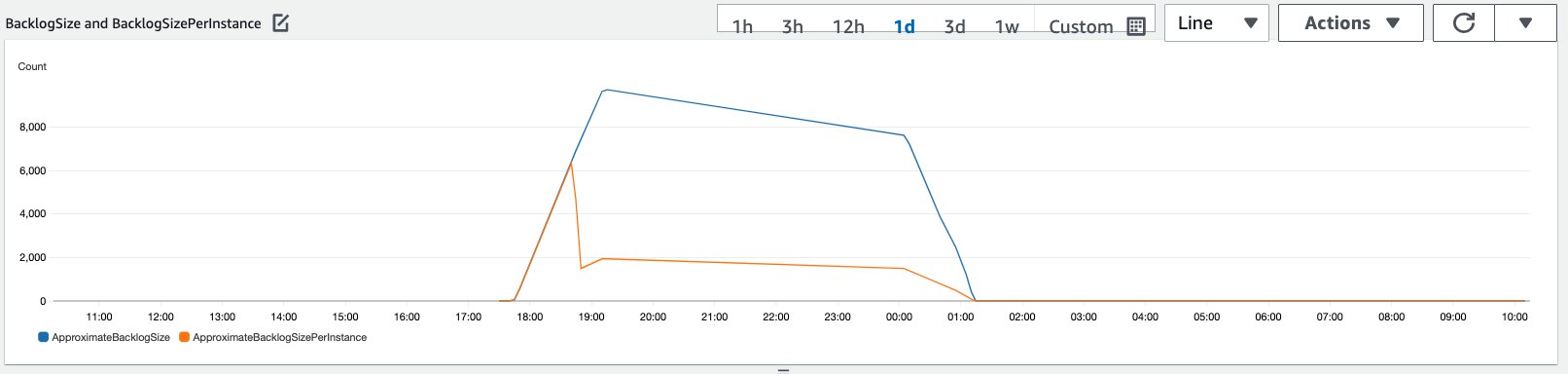
As shown in the following screenshot, the number of instances increased as the inference count scaled up:

The following screenshot shows how the scaling in brings back the endpoint to the initial state of zero running instances:

Clean up
After all the requests are complete, we can delete the endpoint similar to deleting real-time hosted endpoints. Note that if we set the minimum capacity of asynchronous inference endpoints to zero, there are no instance charges incurred after it scales down to zero.
If you enabled auto scaling for your endpoint, make sure you deregister the endpoint as a scalable target before deleting the endpoint. To do this, run the following code:
Remember to delete your endpoint after use as you will be charged for the instances used in this demo.
You also need to delete the S3 objects and SNS topics. If you created any other AWS resources to consume and action on the SNS notifications, you may also want to delete them.
Conclusion
In this post, we demonstrated how to use the new asynchronous inference capability from SageMaker to process a typical large input payload that is part of a summarization task. For inference, we used a model from Hugging Face and deployed it on asynchronous inference endpoint. We explained the common challenges of burst traffic, high model processing times, and large payloads involved with research analytics. The asynchronous inference endpoint’s inherent ability to manage internal queues, predefined concurrency limits, configure response notifications and to automatically scale down to zero helped us address these challenges. The complete code for this example is available on GitHub.
To get started with SageMaker asynchronous inference, check out Asynchronous Inference.
About the Authors
 Dinesh Kumar Subramani is a Senior Solutions Architect with the UKIR SMB team, based in Edinburgh, Scotland. He specializes in artificial intelligence and machine learning. Dinesh enjoys working with customers across industries to help them solve their problems with AWS services. Outside of work, he loves spending time with his family, playing chess and enjoying music across genres.
Dinesh Kumar Subramani is a Senior Solutions Architect with the UKIR SMB team, based in Edinburgh, Scotland. He specializes in artificial intelligence and machine learning. Dinesh enjoys working with customers across industries to help them solve their problems with AWS services. Outside of work, he loves spending time with his family, playing chess and enjoying music across genres.
 Raghu Ramesha is an ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is an ML Solutions Architect with the Amazon SageMaker Service team. He focuses on helping customers build, deploy and migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.