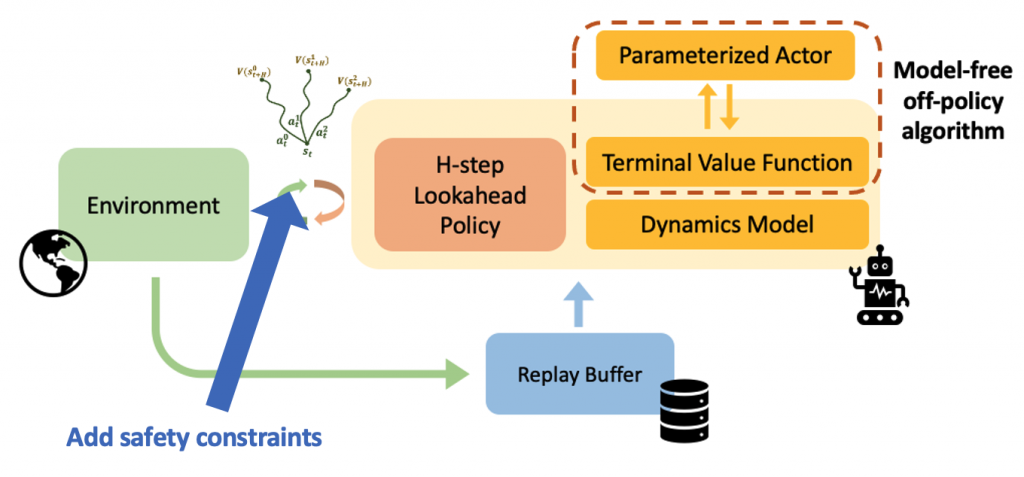
Figure 1. Overview of LOOP: Model-free Reinforcement Learning learns a policy by training a value function. In this setting, the performance of the policy is dependent on the accuracy of the learned value function. We propose LOOP, an efficient framework to learn with a policy that finds the best action sequence using imaginary rollouts with a learned model. This allows LOOP to potentially reduce dependence on value function errors. LOOP achieves strong performance across a range of tasks and problem settings.
Model-Free Off-Policy Reinforcement Learning
Reinforcement learning (RL) enables artificial agents to learn different tasks by interacting with the environment. Within RL, off-policy methods have brought about numerous successes recently for efficiently learning behaviors in applications such as robotics due to their ability to leverage previously collected data efficiently and incorporate data from a variety of sources.
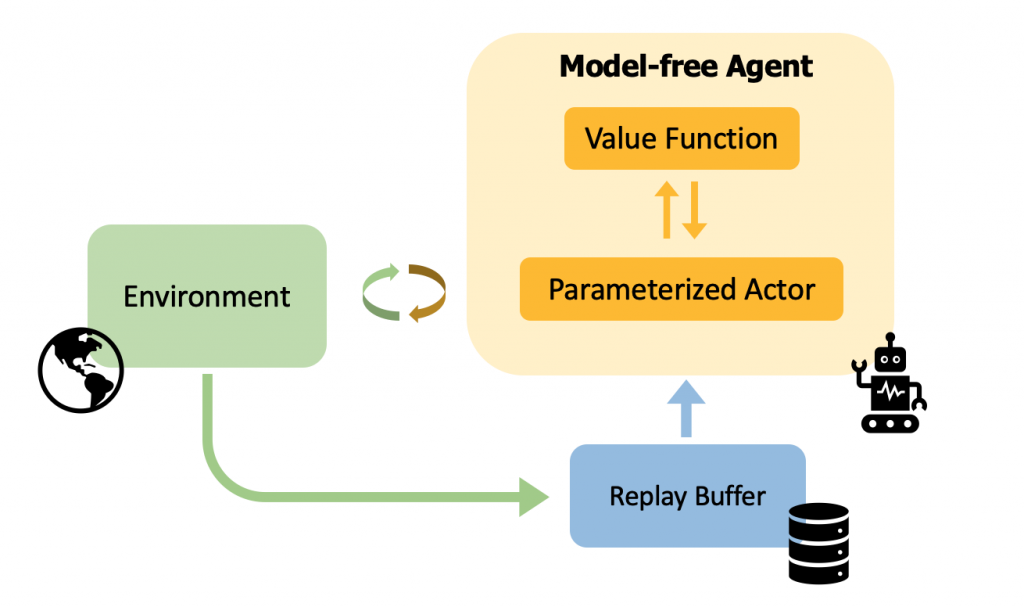
How does off-policy reinforcement learning work? A model-free off-policy reinforcement learning algorithm typically consists of a parameterized actor and a value function (see Figure 2). The actor interacts with the environment collecting the transitions in the replay buffer. The value function is trained using the transitions from the replay buffer to predict the cumulative return of the actor, and the actor is updated by maximizing the action-values at the states visited in the replay buffer. This framework suffers from the following issues:
- The performance of the actor is highly dependent on the accuracy of the learned value function. Learning an accurate value function is challenging in deep reinforcement learning with issues pointed out by previous works such as divergence, instability, rank loss, delusional bias and overestimation.
- Traditionally in model-free RL methods, the parametrized actor is a neural network which is uninterpretable and inflexible in dealing with constraints during deployment. On the other hand, risk-sensitive domains such as healthcare or autonomous driving require us to reason about why the policy chose a particular action or incorporate safety constraints.
So, how should the actor choose actions if the value function is inaccurate? In this work, we suggest using a policy that looks ahead in the future using a learned model to find the best action sequence. This lookahead policy is more interpretable than the parametric actor and also allows us to incorporate constraints. Then we present a computationally efficient framework of learning with the lookahead policy that we call LOOP. We also show how LOOP can also be applied to the offline RL and safe RL along with the online RL setting.
H-step Lookahead Policy
In order to increase the performance, safety, and interpretability of reinforcement learning, we use online planning (“H-step lookahead”) with a terminal value function. In H-step lookahead, we use a learned dynamics model to roll out action sequences for H-horizon into the future and get the cumulative reward. To reason about the future reward beyond H steps, we attach a value function at the end of the rollout. The objective is to select the action sequence that will lead to rollout with the best cumulative return.
Stated formally, H-step lookahead objective aims to find an action sequence ((a_{0:H-1})) that maximizes the following objective:
$$max_{a_{0:H-1}} left[mathbb{E}_{hat{M}}[sum_{t=0}^{H-1}gamma^tr(s_t,a_t)+gamma^Hhat{V}(s_H)]right]$$
where (hat{M}) is the learned dynamics model, (hat{V}) is the learned terminal value function, (r) is the reward function and (gamma) is the discount factor.
H-step lookahead provides several benefits: 1. H-step lookahead reduces dependency on value function errors by using the model rollouts which allows it to trade-off value errors with model-errors. 2. H-step lookahead offers a degree of interpretability that is missing in fully parametric methods and 3. H-step lookahead allows the user to incorporate constraints (even non-stationary) and behavior priors during deployment.
We can also provide theoretical guarantees that demonstrate using an H-step lookahead instead of a parametric actor (1-step greedy actor) can reduce dependency on value errors by a large margin while introducing a dependence on model errors. Despite the additional model errors, we argue that the H-step lookahead is useful as value errors can stem from several reasons as discussed in the previous section. In the low data regime, value errors can also stem from compounding sampling errors whereas the model can be expected to have smaller errors as it is trained with denser supervision using supervised learning. We hypothesize that these numerous sources of errors in value learning make the tradeoff of value-errors with model-errors beneficial and see empirical evidence for the same in our experiments.
LOOP: Learning Off-Policy with Online Planning
As described above, the H-step lookahead policy uses a terminal value function at the end of the H steps. How do we learn the value function for this H-step lookahead policy? The difficulty is that, in learning a value function, we need to evaluate the H-step lookahead policy from different states. However, evaluating the H-step lookahead policy is somewhat slow (Lowrey et al.), since the lookahead policy requires simulating the dynamics for H-steps, which makes such an approach computationally expensive.
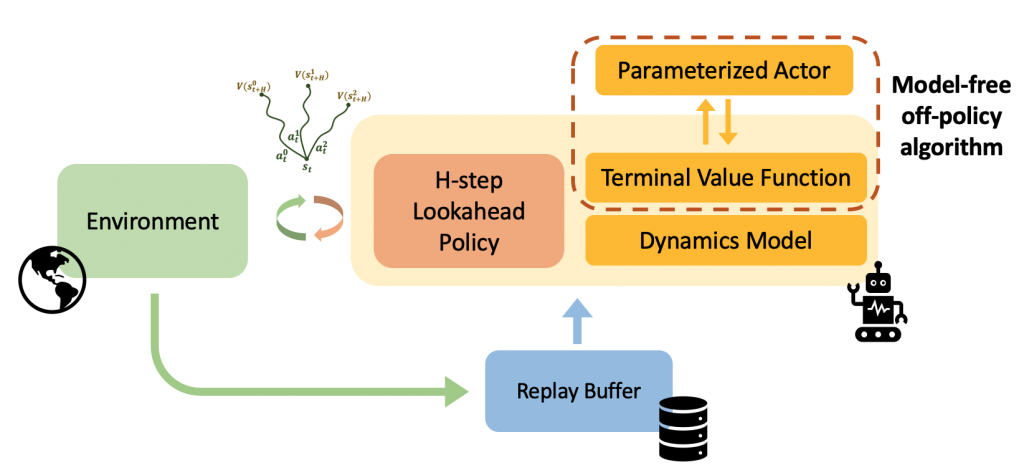
Instead, we propose to learn a parameterized actor to more efficiently learn the terminal value function; to learn the value function, we can evaluate the actor (which is fast) instead of evaluating the H-step lookahead policy (which is slow). We call this approach LOOP: Learning off-policy with online planning. However, the problem with this approach is that there might be a difference between the H-step lookahead policy and the parametric actor (see Figure 3). The difference between these policies can cause unstable learning, which we refer to as “actor divergence.”
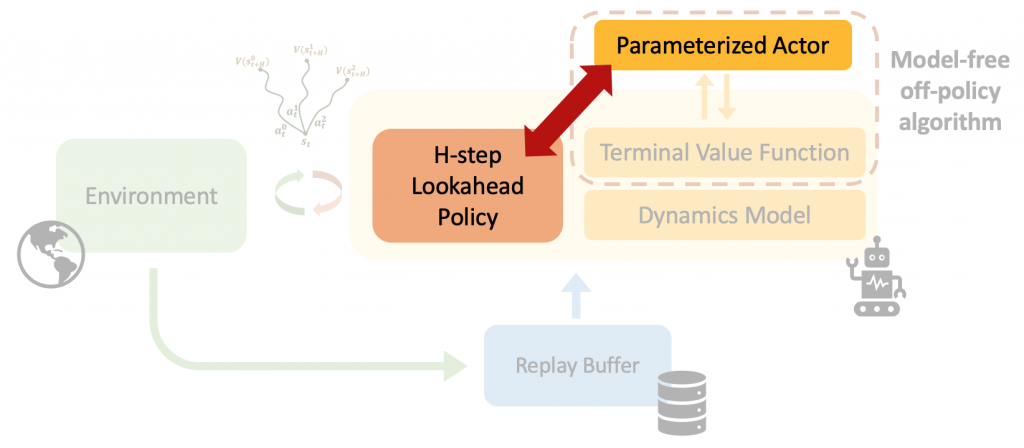
Our solution to actor divergence is to constrain the H-step lookahead policy based on the KL-divergence to a prior, where the prior is based on the parametric actor. This constrained optimization helps ensure that the H-step lookahead policy remains similar to the parametric actor, leading to significantly more stable training. Specifically, we propose actor regularized control (ARC), which uses the following objective
$$p^tau_{opt}=text{argmax}_{p^tau} mathbb{E}_{p^tau} left[mathbb{E}_{hat{M}}[R_{H,hat{V}}(s_t,tau)]right]~,~textrm{s.t}~~D_{KL}(p^tau||p^tau_{prior})le epsilon$$
The inner expectation estimates the return of the H-step lookahead (R_{H,hat{V}}) under model uncertainty while the outer expectation is under a distribution of action sequences.
In the above objective, we aim to find a distribution (p^tau=p^tau_{opt}) over the action sequence (tau) that maximizes the H-step lookahead return (R_{H,hat{V}}(s_t,tau)) while ensuring that the distribution of the action sequence is close to some predefined prior (p^tau_{prior}). In ARC we set this prior to be equal to the parametrized actor and this ensures that H-step lookahead is close to the parametrized actor while still improving the cumulative return. This constrained optimization has a closed-form solution given by ( p^tau_{opt} propto p^tau_{prior} e^{frac{1}{eta}mathbb{E}_{hat{M}}[R_{H,hat{V}}(s_t,tau)]} ). Since the closed-form solution is unnormalized, we approximate it by a gaussian and improve the estimate of its mean and variance by iterative self-normalized importance sampling.
LOOP for Offline and Safe RL
In the previous section, we have seen that ARC optimizes for the expected return in the online RL setting. LOOP can be extended to work in two other domains: 1. Offline RL: Learning from a fixed dataset of collected experience 2. Safe RL: Learning to maximize rewards which ensures that the constraint violations are below some threshold.
For offline RL, ARC optimizes for the following underestimate of H-step lookahead return similar to previous offline RL methods ([1,2]).
$$text{mean}_{[K]}[R_{H,hat{V}}(s_t,tau)] – beta_{pess}text{std}_{[K]}[R_{H,hat{V}}(s_t,tau)]$$
where ([K]) denote model ensembles for uncertainty estimation and (beta_{pess}) is an hyperparameter.
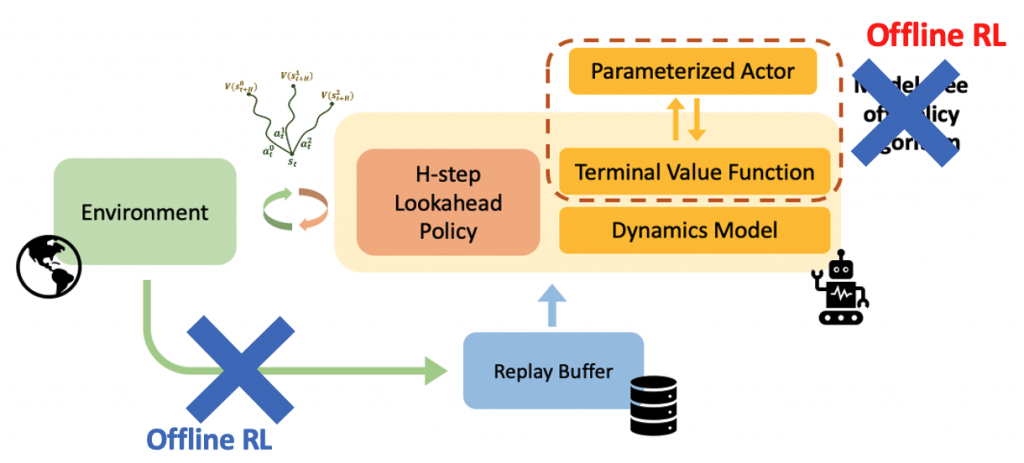
In this setting, the off-policy algorithm is also replaced by an offline RL algorithm (see Figure 5).
For safe RL, ARC optimizes for a constrained H-step lookahead objective which ensures that the cumulative constraint cost in the planning horizon are less than the predefined threshold (see Figure 6).
$$text{argmax}_{a_t} mathbb{E}_{hat{M}}[R_{H,hat{V}}(s_t,tau)]~~text{s.t}~max_{[K]}sum_{t=t}^{t+H-1}gamma^t c(s_t,a_t)le d_0$$
where (c) is the cost function.
Experiments: Online, Offline, and Safe RL
Online RL: We use SAC as the off-policy algorithm in LOOP and test it on a set of MuJoCo locomotion and manipulation tasks. LOOP is compared against a variety of baselines covering model-free (SAC), model-based (PETS-restricted), and hybrid model-free+model-based (MBPO, LOOP-SARSA, SAC-VE) methods. LOOP-SARSA is a variant of LOOP that evaluates the replay buffer policy in its critic.
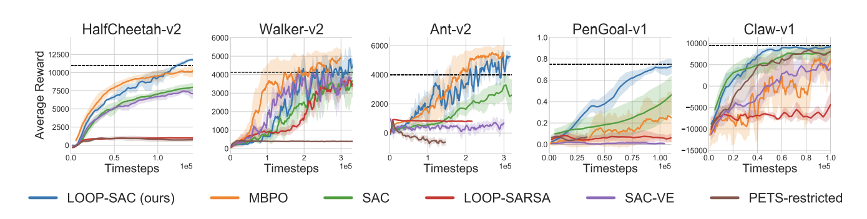
LOOP-SAC significantly improves performance over SAC, the underlying off-policy algorithm used to learn the terminal value function. The increase in efficiency over the SAC empirically confirms that model-error tradeoff with value-error is indeed beneficial. LOOP-SAC is also competitive to MBPO in locomotion tasks, outperforming it significantly in manipulation tasks.

Offline RL: We combine LOOP with two offline RL methods Critic Regularized Regression (CRR) and Policy in latent action space (PLAS) and test it on D4RL datasets. LOOP improves over CRR and PLAS with an average improvement of 15.91% and 29.49% respectively on the D4RL locomotion datasets. This empirically demonstrates that H-step lookahead improves performance over a pre-trained value function (obtained from offline RL) by reducing dependence on value errors.
Safe RL: For testing the safety performance of LOOP we experiment on the OpenAI safety gym environments. In the two environments, CarGoal and PointGoal, the agent needs to navigate to a goal while avoiding obstacles.
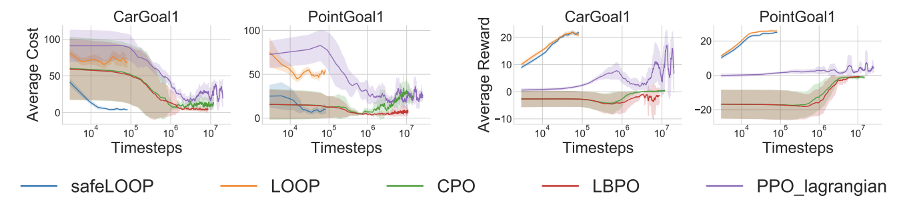
SafeLOOP (Figure above) is the modification of LOOP with constrained H-step lookahead that incorporates constraints. safeLOOP can learn orders of magnitude faster while still being safer than safeRL baselines.
Next Steps
A benefit of using H-step lookahead for deployment is its ability to incorporate non-stationary exploration priors, as this framework disentangles the exploitation policy (parametrized actor) and the exploration policy (H-step lookahead) to a certain degree. Exploring how more principled exploration techniques can enable data collection that leads to better policy improvement is an interesting future direction.
Learning with H-step lookahead efficiently is challenging and unscalable. In our work, we demonstrated one particular way to learn efficiently with H-step lookahead but our approach introduced the issue of actor divergence. Some open questions are 1. What are other ways to learn efficiently with an H-step lookahead policy that does not suffer from actor divergence? 2. How can the actor divergence be reduced without restricting the H-step lookahead policy to be near the parametrized policy (eg. Offline RL)?
Further reading
If you’re interested in more details, please check out the links to the full paper, the project website, talk, and more!
Citation
This blog post is based on the following paper (BibTeX) :
Harshit Sikchi, Wenxuan Zhou, and David Held.
Learning Off-Policy with Online Planning.
In Conference of Robot Learning, November 2021.Acknowledgments
Thanks to Wenxuan Zhou, Ben Eysenbach, Paul Liang, and David Held for feedback on this post! This material is based upon work supported by the United States Air Force and DARPA under Contract No. FA8750-18-C-0092, LG Electronics and the National Science Foundation under Grant No. IIS-1849154.