To delight customers and minimize packaging waste, Amazon must select the optimal packaging type for billions of packages shipped every year. If too little protection is used for a fragile item such as a coffee mug, the item will arrive damaged and Amazon risks their customer’s trust. Using too much protection will result in increased costs and overfull recycling bins. With hundreds of millions of products available, a scalable decision mechanism is needed to continuously learn from product testing and customer feedback.
To solve these problems, the Amazon Packaging Innovation team developed machine learning (ML) models that classify whether products are suitable for Amazon packaging types such as mailers, bags, or boxes, or could even be shipped with no additional packaging. Previously, the team developed a custom pipeline based on AWS Step Functions to perform weekly training and daily or monthly inference jobs. However, over time the pipeline didn’t provide sufficient flexibility to launch models with new architectures. Development for the new pipelines presented an overhead and required coordination between data scientists and developers. To overcome these difficulties and improve speed of deploying new models and architectures, the team chose to orchestrate model training and inference with Amazon SageMaker Pipelines.
In this post, we discuss the previous orchestration architecture based on Step Functions, outline training and inference architectures using Pipelines, and highlight the flexibility the Amazon Packaging Innovation team achieved.
Challenges of the former ML pipeline at Amazon Packaging Innovation
To incorporate continuous feedback about performance of packages, a new model is trained every week using a growing number of labels. The inference for the entire inventory of products is performed monthly, and a daily inference is performed to deliver just-in-time predictions for the newly added inventory.
To automate the process of training multiple models and provide predictions, the team had developed a custom pipeline based on Step Functions to orchestrate the following steps:
- Data preparation for training and inference jobs and loading of predictions to the database (Amazon Redshift) with AWS Glue.
- Model training and inference with Amazon SageMaker.
- Calculation of model performance metrics on the validation set with AWS Batch.
- Using Amazon DynamoDB to store model configurations (such as data split ratio for training and validation, model artifact location, model type, and number of instances for training and inference), model performance metrics, and the latest successfully trained model version.
- Calculation of the differences in the model performance scores, changes in the distribution of the training labels, and comparing the size of the input data between the previous and the new model versions with AWS Lambda functions.
- Given the large number of steps, the pipeline also required a reliable alarming system at each step to alert the stakeholders of any issues. This was accomplished via a combination of Amazon Simple Queue Service (Amazon SQS) and Amazon Simple Notification Service (Amazon SNS). The alarms were created to notify the business stakeholders, data scientists, and developers about any failed steps and large deviations in the model and data metrics.
After using this solution for nearly 2 years, the team realized that this implementation only worked well for a typical ML workflow where a single model was trained and scored on a validation dataset. However, the solution wasn’t sufficiently flexible for complex models and wasn’t resilient to failures. For example, the architecture didn’t easily accommodate sequential model training. It was difficult to add or remove a step without duplicating the entire pipeline and modifying the infrastructure. Even simple changes in the data processing steps such as adjusting the data split ratio or selecting a different set of features required coordination from both a data scientist and a developer. When the pipeline failed at any step, it had to be restarted from the beginning, which resulted in repeated runs and increased cost. To avoid repeated runs and having to restart from the failed step, the team would create a new copy of an abridged state machine. This troubleshooting led to a proliferation of the state machines, each starting from the commonly failing steps. Finally, if a training job encountered a deviation in the distribution of labels, model score, or number of labels, a data scientist had to review the model and its metrics manually. Then a data scientist would access a DynamoDB table with the model versions and update the table to ensure that the correct model was used for the next inference job.
The maintenance of this architecture required at least one dedicated resource and an additional full-time resource for development. Given the difficulties of expanding the pipeline to accommodate new use cases, the data scientists had begun developing their own workflows, which in turn had led to a growing code base, multiple data tables with similar data schemes, and decentralized model monitoring. Accumulation of these issues had resulted in lower team productivity and increased overhead.
To address these challenges, the Amazon Packaging Innovation team evaluated other existing solutions for MLOps, including SageMaker Pipelines (December 2020 release announcement). Pipelines is a capability of SageMaker for building, managing, automating, and scaling end-to-end ML workflows. Pipelines allows you to reduce the number of steps across the entire ML workflow and is flexible enough to allow data scientists to define a custom ML workflow. It takes care of monitoring and logging the steps. It also comes with a model registry that automatically versions new models. The model registry has built-in approval workflows to select models for inference in production. Pipelines also allows for caching steps called with the same arguments. If a previous run is found, a cache is created, which allows for an easy restart instead of recomputing of the successfully completed steps.
In the evaluation process, Pipelines stood out from the other solutions for its flexibility and availability of features for supporting and expanding current and future workflows. Switching to Pipelines freed up developers’ time from platform maintenance and troubleshooting and redirected attention towards the addition of the new features. In this post, we present the design for training and inference workflows at the Amazon Packaging Innovation team using Pipelines. We also discuss the benefits and the reduction in costs the team realized by switching to Pipelines.
Training pipeline
The Amazon Packaging Innovation team trains models for every package type using a growing number of labels. The following diagram outlines the entire process.

The workflow begins by extracting labels and features from an Amazon Redshift database and unloading the data to Amazon Simple Storage Service (Amazon S3) via a scheduled extract, transform, and load (ETL) job. Along with the input data, a file object with the model type and parameters is placed in the S3 bucket. This file serves as the pipeline trigger via a Lambda function.
The next steps are completely customizable and defined entirely by a data scientist using the SageMaker Python SDK for Pipelines. In the scenario we present in this post, the input data is split into training and validation sets and saved back in an S3 bucket by launching a SageMaker Processing job.
When the data is ready in Amazon S3, a SageMaker training job starts. After the model is successfully trained and created, the model evaluation step is performed on the validation data via a SageMaker batch transform job. The model metrics are then compared to the previous week’s model metrics using a SageMaker Processing job. The team has defined multiple custom criteria for evaluating deviations in the model performance. The model is either rejected or approved based on these criteria. If the model is rejected, the previous approved model is used for the next inference jobs. If the model is approved, its version is registered and that model is used for inference jobs. The stakeholders receive a notification about the outcome via Amazon CloudWatch alarms.
The following screenshot from Amazon SageMaker Studio shows the steps of the training pipeline.
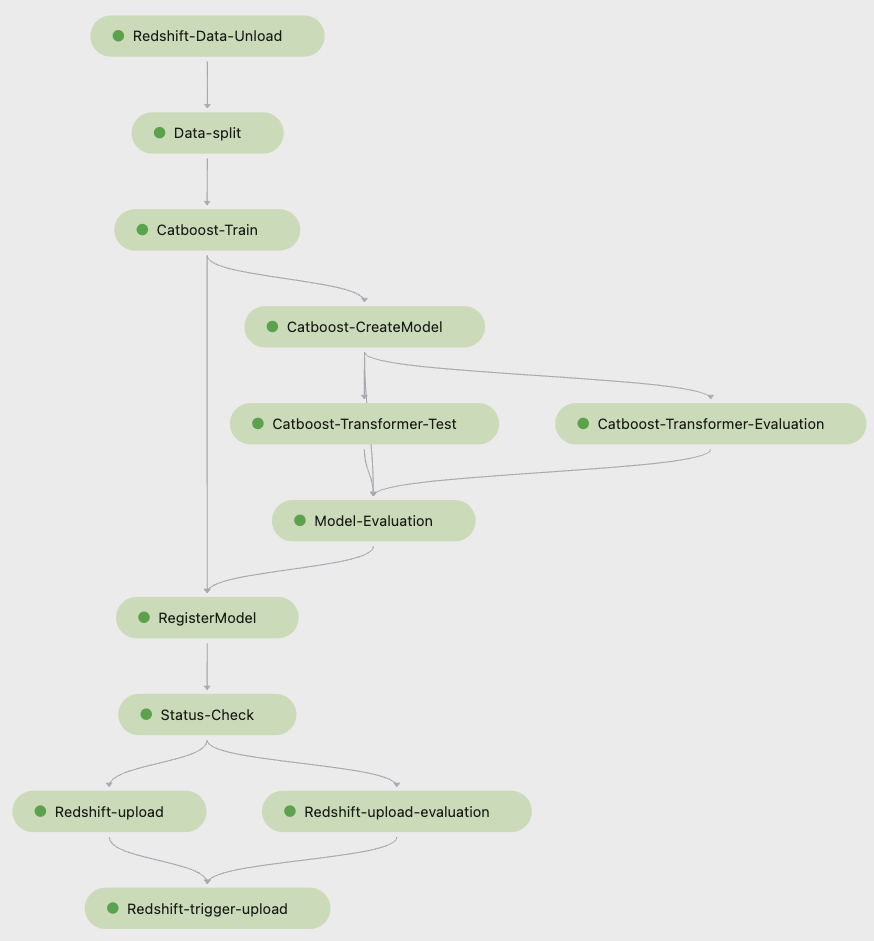
Pipelines tracks each pipeline run, which you can monitor in Studio. Alternatively, you can query the progress of the run using Boto3 or the AWS Command Line Interface (AWS CLI). You can visualize the model metrics in Studio and compare different model versions.
Inference pipeline
The Amazon Packaging Innovation team refreshes predictions for the entire inventory of products monthly. Daily predictions are generated to provide just-in-time packaging recommendations for newly added inventory using the latest trained model. This requires the inference pipeline to run daily with different volumes of data. The following diagram illustrates this workflow.
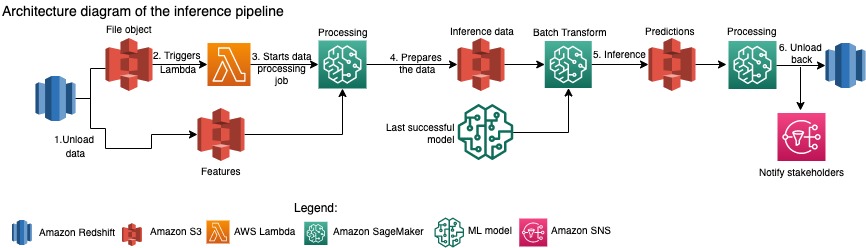
Similar to the training pipeline, the inference begins with unloading the data from Amazon Redshift to an S3 bucket. A file object placed in Amazon S3 triggers the Lambda function that initiates the inference pipeline. The features are prepared for inference and the data is split into appropriately sized files using a SageMaker Processing job. Next, the pipeline identifies the latest approved model to run the predictions and load them to an S3 bucket. Finally, the predictions are loaded back to Amazon Redshift using the boto3-data API within the SageMaker Processing job.
The following screenshot from Studio shows the inference pipeline details.

Benefits of choosing to architect ML workflows with SageMaker Pipelines
In this section, we discuss the gains the Amazon Packaging Innovation team realized by switching to Pipelines for model training and inference.
Out-of-the-box production-level MLOps features
While comparing different internal and external solutions for the next ML pipeline solution, a single data scientist was able to prototype and develop a full version of an ML workflow with Pipelines in a Studio Jupyter environment in less than 3 weeks. Even at the prototyping stage, it became clear that Pipelines provided all necessary infrastructure components required for a production level workflow: model versioning, caching, and alarms. Immediate availability of these features meant that no additional time would be spent developing and customizing them. This was a clear demonstration of value, which convinced the Amazon Packaging Innovation team that Pipelines was the right solution.
Flexibility in developing ML models
The biggest gain for the data scientists on the team was the ability to experiment easily and iterate through different models. Regardless of what framework they preferred for their ML work and the number of steps and features it involved, Pipelines accommodated their needs. The data scientists were empowered to experiment without having to wait to get on the software development sprint to add an additional feature or step.
Reduced Costs
The Pipelines capability of SageMaker is free: you pay only for the compute resources and the storage associated with training and inference. However, when thinking about the cost, you need to account not only for the cost of the services used but also the developer hours needed to maintain the workflow, debug, and patch it. Orchestrating with Pipelines is simpler because it consists of fewer pieces and familiar infrastructure. Previously, adding a new feature required at least two people (data scientist and software engineer) at the Amazon Packaging Innovation team to implement it. With the redesigned pipeline, engineering efforts are now directed towards additional custom infrastructure around the pipeline, such as creation of a single repository for tracking of the machine learning code, simplification of the model deployment across AWS accounts, development of the integrated ETL jobs and common reusable functions.
The ability to cache the steps with a similar input also contributed to the reduction in cost, because the teams were less likely to rerun the entire pipeline. Instead, they could easily start it from the point of failure.
Conclusion
The Amazon Packaging Innovation team trains ML models on a monthly basis and regularly updates predictions for the recommended product packaging types. These recommendations helped them achieve multiple team- and company-wide goals by reducing waste and delighting customers with each order. The training and inference pipelines must run reliably on a regular basis yet allow for constant improvement of the models.
Transitioning to Pipelines allowed the team to deploy four new multi-modal model architectures to production under 2 months. Deploying a new model using the previous architecture would have required 5 days (with the same model architecture) to 1 month (with a new model architecture). Deploying the same model using Pipelines enabled the team to reduce the development time to 4 hours with the same model architecture and to 5 days with a new model architecture. That evaluates to a savings of almost 80% of working hours.
Additional resources
For more information, see the following resources:
- How Amazon is using machine learning to eliminate 915,000 tons of packaging
- Inside Amazon’s quest to use less cardboard
- Train and deploy a custom GPU-supported ML model on Amazon SageMaker
- SageMaker Pipelines Metrics
- Comparing model metrics with SageMaker Pipelines and SageMaker Model Registry
About the Authors
 Ankur Shukla is a Principal Data Scientist at AWS-ProServe based in Palo Alto. Ankur has more than 15 years of consulting experience working directly with the customer and help them solve business problem with technology. He leads multiple global applied science and ML-Ops initiatives within AWS. In his free time, he enjoys reading and spending time with family.
Ankur Shukla is a Principal Data Scientist at AWS-ProServe based in Palo Alto. Ankur has more than 15 years of consulting experience working directly with the customer and help them solve business problem with technology. He leads multiple global applied science and ML-Ops initiatives within AWS. In his free time, he enjoys reading and spending time with family.
 Akash Singla is a Sr. System Dev Engineer with Amazon Packaging Innovation team. He has more than 17 years of experience solving critical business problems through technology for several business verticals. He currently focuses on upgrading NAWS infrastructure for variety of packaging centric applications to scale them better.
Akash Singla is a Sr. System Dev Engineer with Amazon Packaging Innovation team. He has more than 17 years of experience solving critical business problems through technology for several business verticals. He currently focuses on upgrading NAWS infrastructure for variety of packaging centric applications to scale them better.
![]() Vitalina Komashko is a Data Scientist with AWS Professional Services. She holds a PhD in Pharmacology and Toxicology but transitioned to data science from experimental work because she wanted “to own data generation and the interpretation of the results”. Earlier in her career she worked with biotech and pharma companies. At AWS she enjoys solving problems for customers from variety of industries and learning about their unique challenges.
Vitalina Komashko is a Data Scientist with AWS Professional Services. She holds a PhD in Pharmacology and Toxicology but transitioned to data science from experimental work because she wanted “to own data generation and the interpretation of the results”. Earlier in her career she worked with biotech and pharma companies. At AWS she enjoys solving problems for customers from variety of industries and learning about their unique challenges.
 Prasanth Meiyappan is an Sr. Applied Scientist with Amazon Packaging Innovation for 4+ years. He has 6+ years of industry experience in machine learning and has shipped products to improve search customer experience and improve customer packaging experience. Prasanth is passionate about sustainability and has a PhD in statistical modeling of climate change.
Prasanth Meiyappan is an Sr. Applied Scientist with Amazon Packaging Innovation for 4+ years. He has 6+ years of industry experience in machine learning and has shipped products to improve search customer experience and improve customer packaging experience. Prasanth is passionate about sustainability and has a PhD in statistical modeling of climate change.
 Matthew Bales is a Sr. Research Scientist working to optimize package type selection using customer feedback and machine learning. Prior to Amazon, Matt worked as a post doc performing simulations of particle physics in Germany and in a previous life, a production manager of radioactive medical implant devices in a startup. He holds a Ph.D. in Physics from the University of Michigan.
Matthew Bales is a Sr. Research Scientist working to optimize package type selection using customer feedback and machine learning. Prior to Amazon, Matt worked as a post doc performing simulations of particle physics in Germany and in a previous life, a production manager of radioactive medical implant devices in a startup. He holds a Ph.D. in Physics from the University of Michigan.