This post is co-written by Femi Olumofin, an analytics architect at Infoblox.
In the same way that you can conveniently recognize someone by name instead of government-issued ID or telephone number, the Domain Name System (DNS) provides a convenient means for naming and reaching internet services or resources behind IP addresses. The pervasiveness of DNS, its mission-critical role for network connectivity, and the fact that most network security policies often fail to monitor network traffic using UDP port 53 make DNS attractive to malicious actors. Some of the most well-known DNS-based security threats implement malware command and control communications (C&C), data exfiltration, fast flux, and domain generated algorithms, knowing that traditional security solutions can’t detect them.
For more than two decades, Infoblox has operated as a leading provider of technologies and services to manage and secure the networking core, namely DNS, DHCP, and IP address management (collectively known as DDI). Over 8,000 customers, including more than a third of Fortune 500, depend on Infoblox to reliably automate, manage, and secure their on-premises, cloud, and hybrid networks.
Over the past 5 years, Infoblox has used AWS to build its SaaS services and help customers extend their DDI services from physical on-premises appliances to the cloud. The focus of this post is how Infoblox used Amazon SageMaker and other AWS services to build a DNS security analytics service to detect abuse, defection, and impersonation of customer brands.
The detection of customer brands or domain names targeted by socially engineered attacks has emerged as a crucial requirement for the security analytic services offered to customers. In the DNS context, a homograph is a domain name that’s visually similar to another domain name, called a target. Malicious actors create homographs to impersonate highly-valued domain name targets and use them to drop malware, phish user information, attack the reputation of a brand, and so on. Unsuspecting users can’t readily distinguish homographs from legitimate domains. In some cases, homographs and target domains are indistinguishable from a mere visual comparison.
Infoblox’s Challenge
A traditional domain name is composed of digits, letters, and the hyphen characters from the ASCII character encoding scheme, which comprises 128 code points (or possible characters), or from the Extended ASCII, which comprises 256 code points. Internationalized domain names (IDNs) are domain names that also enable the usage of Unicode characters, or can be written in languages that either use Latin letters with ligatures or diacritics (such as é or ü), or don’t use the Latin alphabet at all. IDNs offer extensive alphabets for most writing systems and languages, and allow you to access the internet in your own language. Similarly, because internet usage is rising around the world, IDNs offer a great way for anyone to connect with their target market no matter what language they speak. To enable that many languages, every IDN is represented in Punycode, consisting of a set of ASCII characters. For example, amāzon.com would become xn--amzon-gwa.com. Subsequently, every IDN domain is translated into ASCII for compatibility with DNS, which determines how domain names are transformed into IP addresses.
IDNs, in short, make the internet more accessible to everyone. However, they attract fraudsters that try to substitute some of those characters with identical-looking imitations and redirect us to fake domains. The process is known as homograph attack, which uses Unicode characters to create fake domains that are indistinguishable from targets, such as pɑypal.com for paypal.com (Latin Small Letter Alpha ‘ɑ’ [U+0251]). These look identical at first glance; however, at a closer inspection, you can see the difference: pɑypal.com for paypal.com.
The most common homograph domains construction methods are:
- IDN homographs using Unicode chars (such as replacing “a” with “ɑ”)
- Multi-letter homoglyph (such as replacing “m” with “rn“)
- Character substitution (such as replacing “I” with “l”)
- Punycode spoofing (for example, 㿝㿞㿙㿗[.]com encodes as xn--kindle[.]com, and 䕮䕵䕶䕱[.]com as xn—google[.]com)
Interestingly, homograph attacks go beyond DNS attacks, and are currently used to obfuscate process names on operating systems, or bypass plagiarism detection and phishing systems. Given that many of Infoblox’s customers were concerned about homograph attacks, the team embarked on creating a machine learning (ML)-based solution with Amazon SageMaker.
From a business perspective, dealing with homograph attacks can divert precious resources from an organization. A common method to deal with domain name impersonation and homograph attacks is to beat malicious actors by pre-registering hundreds of domains that are potential homographs of their brands. Unfortunately, such mitigation can only be effective for limited attackers because a much larger number of plausible-looking homographs are still available for an attack. With Infoblox IDN homographs detector, we have observed IDN homographs in 43 of Alexa’s top 50 domain names and for financial services and cryptocurrency domain names. The following table shows a few examples.

Solution
Traditional approaches to the homograph attack problem are based on string distance computation, and while some deep learning ones have started to appear, they predominantly aim to classify whole domain names. Infoblox solved this challenge by aiming at the per character identification standpoint of the domain. Each character is then processed using image recognition techniques, which allowed Infoblox to exploit the glyphs (or visual shape) of the Unicode characters, instead of relying on their code points, which are mere numerical values that make up the code space in character encoding terminology.
Following this approach, Infoblox reached a 96.9% accuracy rate for the classifier detecting Unicode characters that look like ASCII characters. The detection process requires a single offline prediction, unlike existing deep learning approaches that require repeated online prediction. It has fewer false positives when compared with the methods that rely on distance computation between strings.
Infoblox used Amazon SageMaker to build two components:
- An offline identification of Unicode character homographs based on a CNN classifier. This model takes the images and labels of the ASCII characters of interest (such as the subset used for domain names) and outputs them to a Unicode map, which is rebuilt every time after each new release of the Unicode standard.
- An online detection of domain name homographs taking a target domain list and an input DNS stream and generating homographs detections.
The following diagram illustrates how the overall detection process uses these two components.

In this diagram, each character is rendered with a 28 x 28 pixel image. In addition, each character from the train and test set is associated to the closest-looking ASCII character (which is its label).
The remainder of this post dives deeper into the solution to discuss the following:
- Building the training data for the classifier
- The classifier’s CNN architecture
- Model evaluation
- The online detection model
Building the training data for the classifier
To build the classifier, Infoblox wrote some code to assemble training data in an MNIST-like format. The Modified National Institute of Standards and Technology (MNIST) issued a large handwritten digit images database, which has been used as the Hello World for any deep learning computer vision practitioner. Each image has a dimension of 28 x 28 pixels. Infoblox’s code used the following assets to create variations of each character:
- The Unicode standard list of visually confusable characters (the latest version is 13.0.0), along with their security considerations, which allow developers to act appropriately and steer away from visual spoofing attacks.
- The Unicode standard block that contains the most common combining characters in a diacritical marks block. For instance, in the following chart from the Wikipedia entry Combining Diacritical Marks, you can find the U+300 block where the U+030x row crosses the 0 column; U+300 appears to be the grave accent, because you can also find in the “è” character in the French language. Some combining diacritics were left aside for building the training set because they were less conspicuous from a homograph attack perspective (for example, U+0363). For more information, see Combining Diacritical Marks on the Unicode website.
- Multiple font typefaces, which attackers can use for malicious rendering and to radically transform the shapes of characters. For instance, Infoblox used multiple fonts from a local system, but can also add third-party fonts (such as Google Fonts) with the caveat that script fonts should be excluded. Using different fonts to generate many variations of each character acts as a powerful image augmentation technique for this use case: at this stage, Infoblox settled for 65 fonts to generate the training set. This number of fonts is sufficient to build a consistent training set that yields a decent accuracy. Using less fonts didn’t create enough representation for each character, and using more than these 65 fonts didn’t significantly improve the model accuracy.
In the future, Infoblox intends to use some data augmentation techniques (translate, scale, and shear operations, for instance) to further improve the robustness of their ML models. Indeed, each deep learning framework SDK offers rich data augmentations features that can be included in the data preparation pipeline.
CNN architecture of the classifier
When the training set was ready and with little to no learning curve to train a model on Amazon SageMaker, Infoblox started building a classifier based on the following CNN architecture.
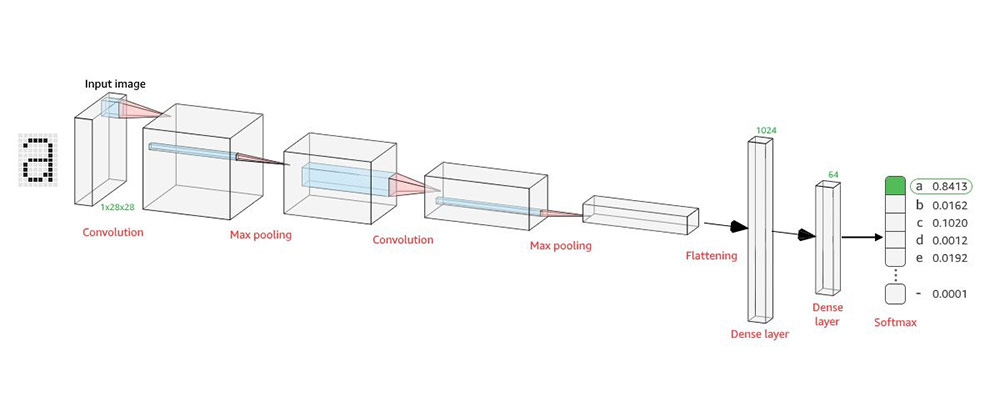
This CNN neural network is built around two successive CONV-POOL cells followed by the classifier. The convolution section automatically extracts features from the input images, and the classification section uses these features to map (classify) the input images to the ASCII character map. The last layer converts the output of the classification network into a vector of probabilities for each class (such as ASCII character) in the input.
Infoblox had already started to build a TensorFlow model and was able to bring it into Amazon SageMaker. From there, they used multiple Amazon SageMaker features to accelerate or facilitate model development:
- Support for distributed training with CPU and GPU instances – Infoblox mainly used ml.c4.xlarge (compute) and ml.p2.xlarge (GPU) instances. Although each training didn’t last long (approximately 20 minutes), each hyperparameter tuning job could span more than 7 hours because of the number of parameters and the granularity of their search space. Distributing the workload on many instances in the background without caring for any infrastructure consideration was key.
- The ability to train, deploy and test predictions right from the notebook environment – From the same environment used to explore and prepare the data, Infoblox used Amazon SageMaker to transparently launch and manage training clusters and inference endpoints. These infrastructures are independent from the Amazon SageMaker notebook instance and are fully managed by the service.
Getting started was easy thanks to the existing documentation and many example notebooks made available by AWS on their public GitHub repo or directly from within the Amazon SageMaker notebook environment.
They started to test a TensorFlow training script locally in Amazon SageMaker with a few lines of code. Training in local mode had the following benefits:
- Infoblox could easily monitor metrics (like GPU consumption), and ensure that the code written was actually taking advantage of the hardware that they would use during training jobs
- While debugging, changes to the training and inference scripts were taken into account instantaneously, making iterating on the code much easier
- There was no need to wait for Amazon SageMaker to provision a training cluster, and the script could run instantaneously
Having the flexibility to work in local mode in Amazon SageMaker was key to easily porting the existing work to the cloud. You can also prototype your inference code locally by deploying the Amazon SageMaker TensorFlow serving container on the local instance. When you’re happy with the model and training behavior, you can switch to a distributed training and inference by changing just a few lines of code so you create a new estimator, optimize the model, or even deploy the trained artifacts to a persistent endpoint.
After completing the data preparation and training process using the local mode, Infoblox started tuning the model in the cloud. This phase started with a coarse set of parameters that were gradually refined through several tuning jobs. During this phase, Infoblox used Amazon SageMaker hyperparameter tuning to help them select the best hyperparameter values. The following hyperparameters appeared to have the highest impact on the model performance:
- Learning rate
- Dropout rate (regularization)
- Kernel dimensions of the convolution layers
When the model was optimized and reached the required accuracy and F1-score performance, the Infoblox team deployed the artifacts to an Amazon SageMaker endpoint. For added security, Amazon SageMaker endpoints are deployed in isolated dedicated instances, and as such, they need to be provisioned and are ready to serve new predictions after a few minutes.
Having the right or cleansed train, validation, and test sets was most important when trying to reach a decent accuracy. For instance, to select the 65 fonts of the training sets, the Infoblox team printed out the available fonts they had on their workstation and reviewed them manually to select the most relevant fonts.
Model evaluation
Infoblox used accuracy and the F1-score as the main metrics to evaluate the performance of the CNN classifier.
Accuracy is the fraction of homographs the model got right. It’s defined as the number of correct predictions detected over the total number of predictions the model generated. Infoblox achieved an accuracy greater than 96.9% (to put it another way, out of 1000 predictions made by the model, 969 were correctly classified as either homographs or not).
Two other important metrics for a classification problem are the precision and the recall.
Precision is defined as a ratio between the number of true positives and the total of true positives and false positives:

Recall is defined as the ratio between the number of true positives over the total of true positives and false negative:

Infoblox made use of a combined metric, the F1-score, which takes a harmonic mean between precision and recall. This helps the model strike a good balance between these two metrics.
From a business impact perspective, the preference is to minimize false negatives over false positives. The impact of a false negative is missed detections, which you can mitigate with an ensemble of classifiers. False positives have a direct negative effect on end-users, especially when you configure a block response policy action for DNS resolution of homographs in detector results.
Online detection model
The following diagram illustrates the architecture of the online detection model.

The online model uses the following AWS components:
- Amazon Simple Storage Service (Amazon S3) stores train and test sets (1), Unicode glyphs (1), passive datasets, historical data, and model artifacts (3).
- Amazon SageMaker trains the CNN model (2) and delivers offline inference with the homograph classifier (4). The output is the ASCII to Unicode map (5).
- AWS Data Pipeline runs the batch detection pipeline (6) and manages the Amazon EMR clusters (creating them and submitting the different steps of the processing until shutdown).
- Amazon EMR runs ETL jobs for both batch and streaming pipelines.
- The batch pipeline reads input data from Amazon S3 (loading a list of targets and reading passive DNS data (7)), applies some ETL (8), and makes them available to the online detection system (10).
- The online detection system is a streaming pipeline applying the same kind of transformation (10), but gets additional data by subscribing to an Apache Kafka broker (11).
- Amazon DynamoDB (a NoSQL database) stores very detailed detection data (12) coming from the detection algorithm (the online system). Heavy writing is the main access pattern used here (large datasets and infrequent read requirement).
- Amazon RDS for PostgreSQL stores a subset of the detection results at a higher level with a brief description of the results (13). Infoblox found Amazon RDS to be very suitable for storing a subset of the detection results that require high frequency read access for their use case while keeping cost under control.
- AWS Lambda functions orchestrate and connect the different components of the architecture.
The overall architecture also follows AWS best practices with Amazon Virtual Private Cloud (Amazon VPC), Elastic Load Balancing, and Amazon Elastic Block Store (Amazon EBS).
Conclusion
The Infoblox team used Amazon SageMaker to train a deep CNN model that identifies Unicode characters that are visually similar to ASCII characters of DNS domains. The model was subsequently used to identify homograph characters from the Unicode standard with 0.969 validation accuracy and 0.969 test F1 score. Then they wrote a detector to use the model predictions to detect IDN homographs over passive DNS traffic without online image digitization or prediction. As of this writing, the detector has identified over 60 million resolutions of homograph domains, some of which are related to online campaigns to abuse popular online brands. There are more than 500 thousand unique homographs, among 60 thousand different brands. It has also identified attacks across 100 industries, with the majority (approximately 49%) aiming at financial services domains.
IDNs inadvertently allow attackers more creative ways to form homograph domains beyond what brand owners can anticipate. Organizations should consider DNS activities monitoring for homographs and not rely solely on pre-registering a shortlist of homograph domains for brand protection.
The following screenshots show examples of homograph domain webpage content compared to the domain they attempt to impersonate. We show the content of a homograph domain on the left and the real domain on the right.
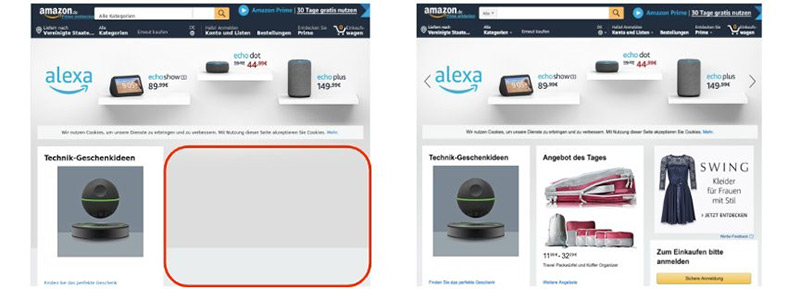
Amazon: xn--amzon-hra.de => amäzon.de vs. amazon.de. Notice the empty area on the homograph domain page.
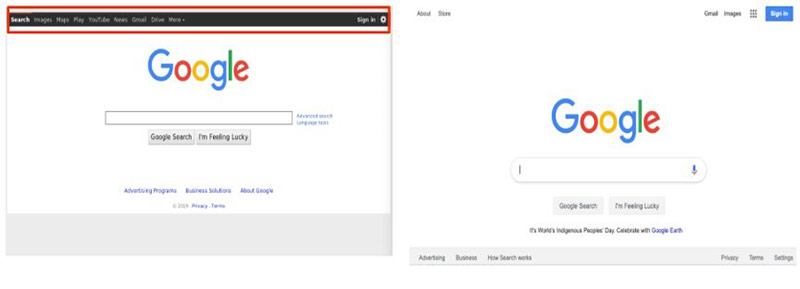
Google: xn--goog-8va3s.com => googļę.com vs. google.com. There is a top menu bar on the homograph domain page.
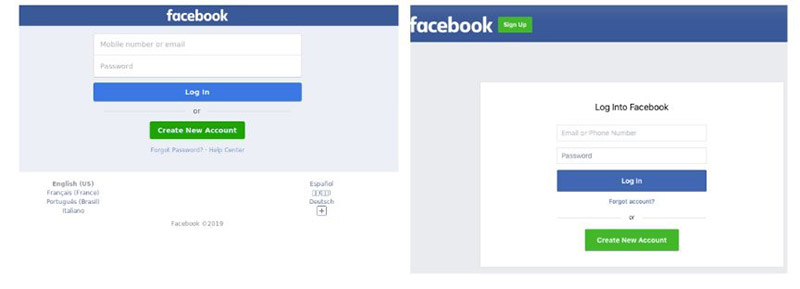
Facebook: xn--faebook-35a.com => faċebook.com vs. facebook.com. The difference between the login pages is not readily apparent unless we view them side-by-side.
About the authors
 Femi Olumofin is an analytics architect at Infoblox, where he leads a company-wide effort to bring AI/ML models from research to production at scale. His expertise is in security analytics and big data pipelines architecture and implementation, machine learning models exploration and delivery, and privacy enhancing technologies. He received his Ph.D. in Computer Science from the University of Waterloo in Canada. In his spare time, Femi enjoys cycling, hiking, and reading.
Femi Olumofin is an analytics architect at Infoblox, where he leads a company-wide effort to bring AI/ML models from research to production at scale. His expertise is in security analytics and big data pipelines architecture and implementation, machine learning models exploration and delivery, and privacy enhancing technologies. He received his Ph.D. in Computer Science from the University of Waterloo in Canada. In his spare time, Femi enjoys cycling, hiking, and reading.
 Michaël Hoarau is an AI/ML specialist solution architect at AWS who alternates between data scientist and machine learning architect, depending on the moment. He has worked on a wide range of ML use cases, ranging from anomaly detection to predictive product quality or manufacturing optimization. When not helping customers develop the next best machine learning experiences, he enjoys observing the stars, traveling, or playing the piano.
Michaël Hoarau is an AI/ML specialist solution architect at AWS who alternates between data scientist and machine learning architect, depending on the moment. He has worked on a wide range of ML use cases, ranging from anomaly detection to predictive product quality or manufacturing optimization. When not helping customers develop the next best machine learning experiences, he enjoys observing the stars, traveling, or playing the piano.
 Kosti Vasilakakis is a Sr. Business Development Manager for Amazon SageMaker, AWS’s fully managed service for end-to-end machine learning, and he focuses on helping financial services and technology companies achieve more with ML. He spearheads curated workshops, hands-on guidance sessions, and pre-packaged open-source solutions to ensure that customers build better ML models quicker, and safer. Outside of work, he enjoys traveling the world, philosophizing, and playing tennis.
Kosti Vasilakakis is a Sr. Business Development Manager for Amazon SageMaker, AWS’s fully managed service for end-to-end machine learning, and he focuses on helping financial services and technology companies achieve more with ML. He spearheads curated workshops, hands-on guidance sessions, and pre-packaged open-source solutions to ensure that customers build better ML models quicker, and safer. Outside of work, he enjoys traveling the world, philosophizing, and playing tennis.