Last year, Stanford won 2nd place in the Alexa Prize Socialbot Grand Challenge 3 for social chatbots. In this post, we look into building a chatbot that combines the flexibility and naturalness of neural dialog generation with the reliability and practicality of scripted dialogue. We also announce an open-source version of our socialbot with the goal of enabling future research.
Our bot, Chirpy, is a modern social chatbot, tested and validated by real users, capable of discussing a broad range of topics. We can’t wait to introduce it to you!
What makes Chirpy special?
Social conversations – such as one you would have with a friend – challenge chatbots to demonstrate human traits: emotional intelligence and empathy, world knowledge, and conversational awareness. They also challenge us – researchers and programmers – to imagine novel solutions and build fast and scalable systems. As an Alexa Prize team, we created Chirpy, a social chatbot that interacted with hundreds of thousands of people who rated the conversations and validated our approaches. We were able to successfully incorporate neural generation into Chirpy and here we explain what went into making that happen.
Recently, there has been enormous progress in building large neural net models that can produce fluent, coherent text by training them on a very large amount of text 12. One might wonder, “Why not just extend these models and fine-tune them (or train them) on large dialogue corpora?” In fact Meena3, BlenderBot4, and DialoGPT5 attempt to do exactly this, yet they are not being used to chat with people in the real world – why? First, they lack controllability and can respond unpredictably to new, or out-of-domain inputs. For example they can generate toxic language and cause safety issues. Furthermore, they lack consistency over long conversations – forgetting, repeating, and contradicting themselves. Although neurally-generated dialog is more flexible and natural than scripted dialog, as the number of neural turns increases, their errors compound and so does the likelihood of producing inconsistent or illogical responses.
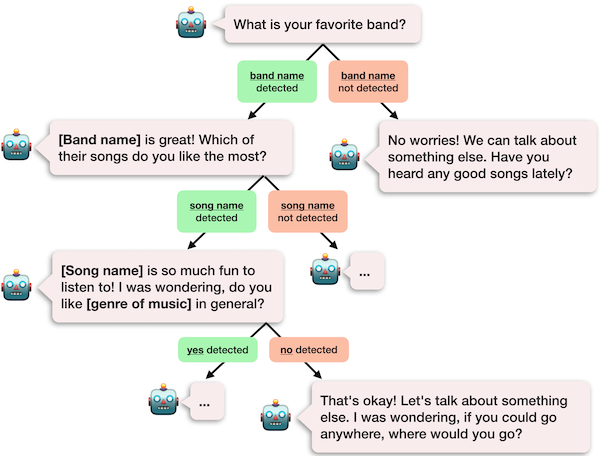
Since neural generation is unreliable, practical conversational agents are dominated by hand-written rules: dialogue trees, templated responses, topic ontologies, and so on. Figure 1 shows an example of this type of conversation. The bot gives a series of scripted responses, choosing responses based on fixed criteria – for example, whether or not a song name is detected. This design has benefits: developers writing these rules can interpret the system’s choices, control the direction of the conversation, and ensure consistency. But these rules are brittle! An unanticipated user utterance that gets misclassified into a wrong branch can lead to absurd responses and lead down a path that is hard to recover from. Additionally, depending on a predetermined set of templated responses limits the range of possibilities and can make the bot sound unnatural.
Both neural and scripted dialog have clear benefits and drawbacks. We designed Chirpy to take advantage of both, choosing a modular architecture that lets us fluidly combine elements of neural and scripted conversations. We refer to our bot’s modules as response generators, or RGs. Each response generator is designed for a specific type of conversation such as talking about music, exchanging opinions, or sharing factual information. Based on their roles, some response generators are scripted, some are entirely neural, and others use a combination of neural and scripted dialog. We track entities, topics, emotions, and opinions using rules that maintain consistency across response generators, without sacrificing the flexibility of our neural components. This modular design allows users to add new response generators without needing to alter large parts of the codebase every time they want to extend Chirpy’s coverage. In the following sections, we highlight a few response generators and how they fit into our broader system.
Response Generators
Our response generators range from fully rule-based to fully neural. First, we’ll highlight three to demonstrate this range: the music response generator, which is entirely rule-based, the personal chat response generator, which relies entirely on a neural generative model, and the wikipedia response generator, which combines both rule-based and neurally-generated content. In the next section, we’ll discuss how Chirpy decides which RG to use, so that it can leverage their different strengths.
Music Response Generator
Chirpy’s music response generator uses rule-based, scripted dialog trees, like the example shown in Figure 1. It asks the user a series of questions about their musical preferences and, depending on their answers, selects a response. All possible responses are hand-written in advance, so this RG is highly effective at handling cases where the user responds as expected, but has more difficulty when they say something it doesn’t have a rule for.
Personal Chat Response Generator
We wanted Chirpy to have the ability to discuss users’ personal experiences and emotions. Since these are highly varied, we used neural generation because of its flexibility when handling previously unseen utterances. As shown in Figure 2, neural generation models input a context and then generate the response word-by-word. We fine-tuned a GPT2-medium model 6 on the EmpatheticDialogues dataset 7, which consists of conversations between a speaker describing an emotional personal experience and a listener who responds to the speaker. Since the conversations it contains are relatively brief, grounded in specific emotional situations, and focused on empathy, this dataset is well suited to the personal chat RG.
To keep neural conversations focused and effective, we begin each personal chat discussion by asking the user a scripted starter question, e.g., What do you like to do to relax? On each subsequent turn, we pass the conversation history as context to the GPT-2 model, and then sample 20 diverse responses. When selecting the final response, we prioritize generations that contain questions. However, if fewer than one third of the responses contain questions, we assume that the model no longer has a clear path forward, select a response without a question, and hand over to another response generator. Not continuing neurally generated conversation segments for too long is a simple but effective strategy for preventing the overall conversation quality from degrading.
Wiki Response Generator
We wanted Chirpy to be able to discuss a broad range of topics in depth. One source of information for a broad range of topics is Wikipedia, which provides in-depth content for millions of entities. Chirpy tracks the entity under discussion and if it is able to find a corresponding Wikipedia article, the Wiki RG searches for relevant sentences using TF-IDF, a standard technique used by search engines to find relevant documents based on text overlap with an underlying query. To encourage such overlap, we have our bot ask a handwritten open-ended question that is designed to evoke a meaningful response, eg in Figure 2 “I’m thinking about visiting the Trevi fountain. Do you have any thoughts about what I should do?”
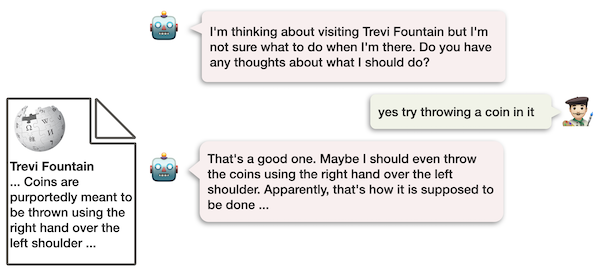
However, quoting sentences from Wikipedia is insufficient, due to its encyclopedic, stiff writing style. When people share information they connect it to the conversation thus far and style it conversationally. Thus, we use a neural rephrasing model that takes the conversational history and the retrieved wikipedia sentence as input and generates a conversationally phrased reply. This model is trained on a modified version of the Topical Chat Dataset 8 which contains conversations paired with factual sentences. Unfortunately, the model isn’t perfect and makes mistakes from time to time. We handle user’s confusion with a few handwritten rules.
How do the response generators fit together?
There are clear benefits to all three types of dialog – entirely scripted, partially scripted, and entirely neural. So on a given turn, how do we decide which kind of response to give?
Many other chatbots use a dialog management strategy where on a given turn, the bot gets a user utterance, decides which module can handle it best, and then returns the next response from this module. Our bot delays that decision until after generation, so that it can make a more informed choice. On each turn, every module within the bot generates a response and a self-assessed priority using module specific context. Once every response generator has produced some output, the bot will then use these priorities to select the highest priority response.
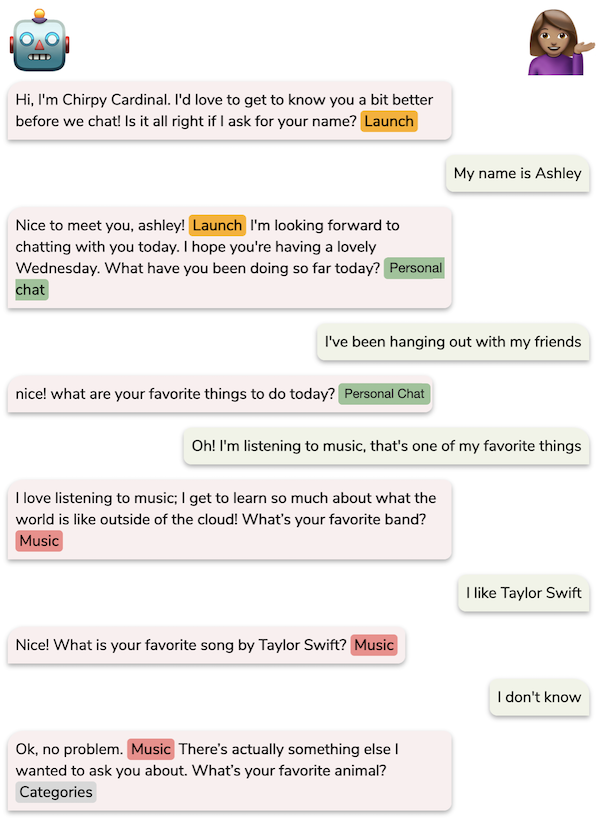
Since a module may decide it has finished discussing a topic, we allow another module to append a prompt and take over on the same turn. The first module’s response acknowledges the users’ previous utterance, and the second module’s prompt gives the user direction for the next turn. For example, the user might receive a response “I also like avocados” from the opinions response generator, which is used for casual exchange of personal opinions, and then a prompt “Would you like to know more about the history of avocados?” from the Wikipedia response generator, which is used for sharing factual information. Figure 3 shows an example of the type of conversation our bot has, with different RGs handling their own specialized types of dialog.
The animations below show how the response and prompt selection works. The opinion, wikipedia, and personal chat modules use the state and annotations to generate responses, the bot selects the best response and prompt, and then the bot updates its state based on this choice.
How can I use Chirpy?
We’re open-sourcing Chirpy Cardinal, so that others can expand on the existing socialbot, create their own, or simply have a social conversation. This release is unique for several reasons.
- User-tested design
- Our bot has already been tested over hundreds of thousands of conversations during the Alexa Prize Competition. Its strategies are verified and can appeal to a broad range of users with diverse interests.
- Essential building blocks
- We’ve implemented time-consuming but essential basics, such as entity-linking and dialog management, so that you won’t have to. This allows new developers to move chatbot design forward faster, focusing on higher-level research and design.
- Customizable architecture
- Our bot’s flexible architecture allows easier customization for your own unique use cases. You can introduce new areas of content by creating specialized response generators, and you can choose what your bot prioritizes by adjusting the settings of the dialog manager.
- Experiment framework
- Finally, our bot was designed to enable dialog research. Users can create their own experiments, which are stored as parameters of the state, determine how often these experiments should be triggered, and then use the collected data to compare different strategies or models.
To get started, you can try the live demo of chirpy yourself before diving into the code in our github repo.
You can find more details about our system in a 30 minute overview presentation or our technical paper.
Our team continues to work on improving open-domain dialogue. You can find more about our current Alexa Prize team, publications and other updates at https://stanfordnlp.github.io/chirpycardinal/
Acknowledgements
We thank our colleages at Stanford’s Alexa Prize Team: Abigail See (co-lead), Kathleen Kenealy, Haojun Li, Peng Qi, Kaushik Ram Sadagopan, Nguyet Minh Phu, Dilara Soylu, Christopher D. Manning (faculty advisor).
We also thank Haojun Li and Dilara Soylu for helping us with open sourcing of the codebase.
Thanks to Siddharth Karamcheti, Megha Srivastava and rest of the SAIL Blog Team for reviewing and publishing our blog post.
This research was supported in part by Stanford Open Virtual Assistant Lab (OVAL) (for Amelia Hardy) and Alexa Prize Stipend Award (for Haojun Li, Kaushik Ram Sadagopan, Nguyet Minh Phu, Dilara Soylu).
-
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. (2019). Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. CoRR, abs/1910.13461. ↩
-
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, … and Dario Amodei. (2020). Language Models are Few-Shot Learners. arXiv:2005.14165 ↩
-
Daniel Adiwardana, Minh-Thang Luong, David R. So, Jamie Hall, Noah Fiedel, Romal Thoppilan, … Quoc V. Le. (2020). Towards a human-like open-domain chatbot. arXiv preprint arXiv:2001.09977. ↩
-
Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, … Jason Weston. (2020). Recipes for building an open-domain chatbot. arXiv preprint arXiv:2004.13637. ↩
-
Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, & Bill Dolan. (2020). DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation. arXiv preprint arXiv:1911.00536. ↩
-
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. (2019). Language Models are Unsupervised Multitask Learners. ↩
-
Hannah Rashkin, Eric Michael Smith, Margaret Li and Y-Lan Boureau. (2019). Towards Empathetic Open-domain Conversation Models: a New Benchmark and Dataset. arXiv preprint arXiv:1811.00207. ↩
-
Karthik Gopalakrishnan, Behnam Hedayatnia, Qinlang Chen, Anna Gottardi, Sanjeev Kwatra, Anu Venkatesh, Raefer Gabriel, & Dilek Hakkani-Tür (2019). Topical-Chat: Towards Knowledge-Grounded Open-Domain Conversations. In Proc. Interspeech 2019 (pp. 1891–1895). ↩