Overview
INT8 quantization is a powerful technique for speeding up deep learning inference on x86 CPU platforms. By reducing the precision of the model’s weights and activations from 32-bit floating-point (FP32) to 8-bit integer (INT8), INT8 quantization can significantly improve the inference speed and reduce memory requirements without sacrificing accuracy.
In this blog, we will discuss the recent progress on INT8 quantization for x86 CPU in PyTorch, focusing on the new x86 quantization backend. We will also briefly look at the new quantization path with PyTorch 2.0 Export (PT2E) and TorchInductor.
X86 Quantization Backend
The current recommended way of quantization in PyTorch is FX. Before PyTorch 2.0, the default quantization backend (a.k.a. QEngine) on x86 CPUs was FBGEMM, which leveraged the FBGEMM performance library to achieve the performance speedup. In the PyTorch 2.0 release, a new quantization backend called X86 was introduced to replace FBGEMM. The x86 quantization backend offers improved INT8 inference performance when compared to the original FBGEMM backend by leveraging the strengths of both FBGEMM and the Intel® oneAPI Deep Neural Network Library (oneDNN) kernel libraries.
Performance Benefit from X86 Backend
To measure the performance benefits of the new X86 backend, we ran INT8 inference on 69 popular deep learning models (shown in Figures 1-3 below) using 4th Gen Intel® Xeon® Scalable processors. The results showed a 2.97X geomean performance speedup compared to FP32 inference performance, while the speedup was 1.43X with the FBGEMM backend. The charts below show the per-model performance speedup comparing the x86 backend and the FBGEMM backend.
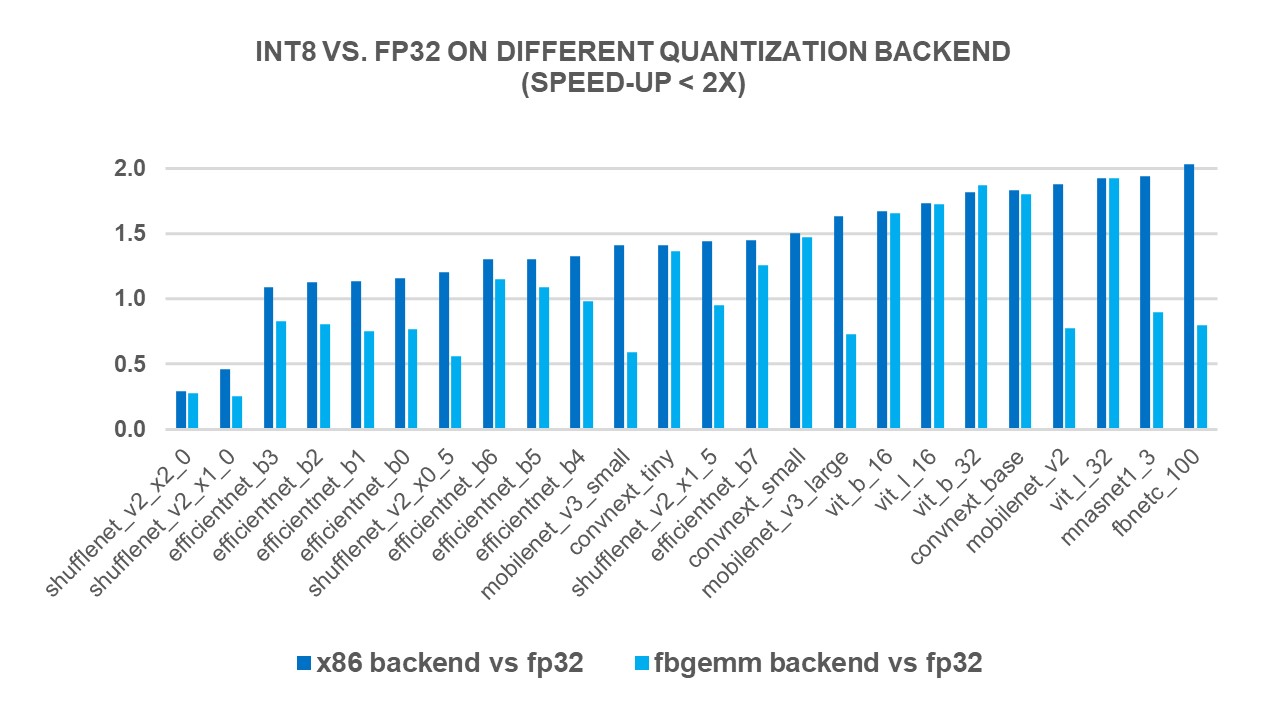
Figure 1: Models with less than 2x performance boost with x86 backend1
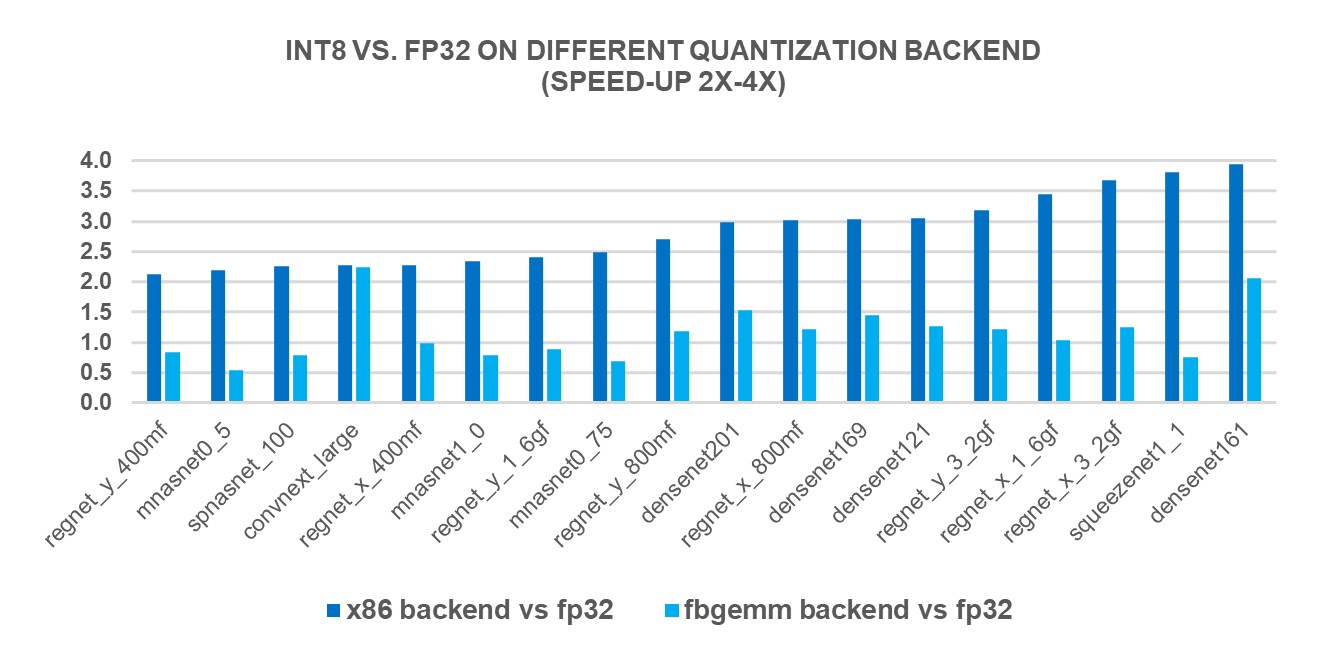
Figure 2: Models with 2x-4x performance boost with x86 backend1
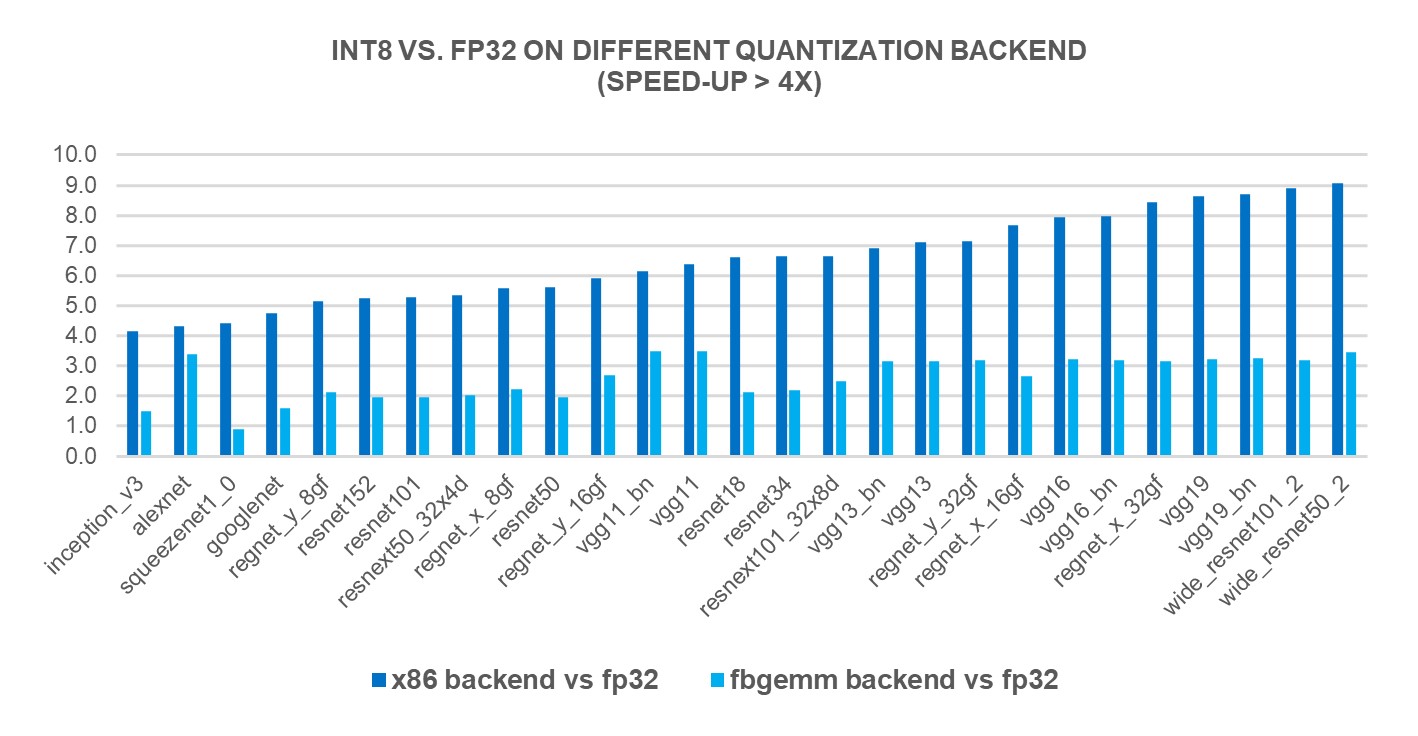
Figure 3: Models with larger than 4x performance boost with x86 backend1
Usage of x86 Backend
By default in 2.0, users on x86 platforms will use the x86 quantization backend and their PyTorch programs will remain unchanged when using the default backend. Alternatively, users can specify x86 as the quantization backend explicitly.
Below is an example code snippet of PyTorch static post-training quantization with x86 quantization backend.
import torch
from torch.ao.quantization import get_default_qconfig_mapping
from torch.quantization.quantize_fx import prepare_fx, convert_fx
qconfig_mapping = get_default_qconfig_mapping()
# Or explicity specify the qengine
# qengine = 'x86'
# torch.backends.quantized.engine = qengine
# qconfig_mapping = get_default_qconfig_mapping(qengine)
model_fp32 = MyModel().eval()
x = torch.randn((1, 3, 224, 224), dtype=torch.float)
x = x.to(memory_format=torch.channels_last)
# Insert observers according to qconfig and backend config
prepared_model = prepare_fx(model_fp32, qconfig_mapping, example_inputs=x)
# Calibration code not shown
# Convert to quantized model
quantized_model = convert_fx(prepared_model)
Technical Details of x86 Backend
We devised heuristic dispatching rules according to the performance numbers from the models we benchmarked to decide whether to invoke oneDNN or FBGEMM performance library to execute the convolution or matrix multiplication operations. The rules are a combination of operation kinds, shapes, CPU architecture information, etc. Detailed logic is available here. For more design and technical discussion, please refer to the Request for Comments.
Next Steps With a New Quantization Path PyTorch 2.0 Export
Although still far from finalized, a new quantization path, PyTorch 2.0 Export (PT2E), is in early design and PoC stage. The new approach is slated to replace the FX quantization path in the future. It is built upon the capabilities of TorchDynamo Export, a feature introduced in the PyTorch 2.0 release for FX graph capturing. This graph is then quantized and lowered to different backends. TorchInductor, the new DL compiler of PyTorch, has shown promising results in terms of FP32 inference speedup on x86 CPU. We are working actively to enable it as one of the quantization backends of PT2E. We believe the new path will lead to further improvements in INT8 inference performance due to more flexibility of fusion at different levels.
Conclusion
The x86 backend introduced in PyTorch 2.0 release has demonstrated a remarkable improvement in INT8 inference speed on x86 CPU platforms. It offers a 1.43X speedup compared to the original FBGEMM backend while maintaining backward compatibility. This enhancement can benefit end users with minimal or no modifications to their programs. Furthermore, a new quantization path, PT2E, is currently in development and is expected to provide even more possibilities in the future.
Acknowledgement
Special thanks to Nikita Shulga, Vasiliy Kuznetsov, Supriya Rao, and Jongsoo Park. Together, we made one more step forward on the path of improving the PyTorch CPU ecosystem.
Configuration
1 AWS EC2 r7iz.metal-16xl instance (Intel(R) Xeon(R) Gold 6455B, 32-core/64-thread, Turbo Boost On, Hyper-Threading On, Memory: 8x64GB, Storage: 192GB); OS: Ubuntu 22.04.1 LTS; Kernel: 5.15.0-1028-aws; Batch Size: 1; Core per Instance: 4; PyTorch 2.0 RC3; TorchVision 0.15.0+cpu, test by Intel on 3/77/2023. May not reflect all publicly available security updates.