nvFuser is a Deep Learning Compiler for NVIDIA GPUs that automatically just-in-time compiles fast and flexible kernels to reliably accelerate users’ networks. It provides significant speedups for deep learning networks running on Volta and later CUDA accelerators by generating fast custom “fusion” kernels at runtime. nvFuser is specifically designed to meet the unique requirements of the PyTorch community, and it supports diverse network architectures and programs with dynamic inputs of varying shapes and strides.
In this blog post we’ll describe nvFuser and how it’s used today, show the significant performance improvements it can obtain on models from HuggingFace and TIMM, and look ahead to nvFuser in PyTorch 1.13 and beyond. If you would like to know more about how and why fusion improves the speed of training for Deep Learning networks, please see our previous talks on nvFuser from GTC 2022 and GTC 2021.
nvFuser relies on a graph representation of PyTorch operations to optimize and accelerate. Since PyTorch has an eager execution model, the PyTorch operations users are running are not directly accessible as a whole program that can be optimized by a system like nvFuser. Therefore users must utilize systems built on top of nvFuser which are capable of capturing users programs and translating them into a form that is optimizable by nvFuser. These higher level systems then pass these captured operations to nvFuser, so that nvFuser can optimize the execution of the user’s script for NVIDIA GPUs. There are three systems that capture, translate, and pass user programs to nvFuser for optimization:
-
TorchScript jit.script
- This system directly parses sections of an annotated python script to translate into its own representation what the user is doing. This system then applies its own version of auto differentiation to the graph, and passes sections of the subsequent forward and backwards graphs to nvFuser for optimization.
-
FuncTorch
- This system doesn’t directly look at the user python script, instead inserting a mechanism that captures PyTorch operations as they’re being run. We refer to this type of capture system as “trace program acquisition”, since we’re tracing what has been performed. FuncTorch doesn’t perform its own auto differentiation – it simply traces PyTorch’s autograd directly to get backward graphs.
-
TorchDynamo
- TorchDynamo is another program acquisition mechanism built on top of FuncTorch. TorchDynamo parses the Python bytecode produced from the user script in order to select portions to trace with FuncTorch. The benefit of TorchDynamo is that it’s able to apply decorators to a user’s script, effectively isolating what should be sent to FuncTorch, making it easier for FuncTorch to successfully trace complex Python scripts.
These systems are available for users to interact with directly while nvFuser automatically and seamlessly optimizes performance critical regions of the user’s code. These systems automatically send parsed user programs to nvFuser so nvFuser can:
- Analyze the operations being run on GPUs
- Plan parallelization and optimization strategies for those operations
- Apply those strategies in generated GPU code
- Runtime-compile the generated optimized GPU functions
- Execute those CUDA kernels on subsequent iterations
It is important to note nvFuser does not yet support all PyTorch operations, and there are still some scenarios that are actively being improved in nvFuser that are discussed herein. However, nvFuser does support many DL performance critical operations today, and the number of supported operations will grow in subsequent PyTorch releases. nvFuser is capable of generating highly specialized and optimized GPU functions for the operations it does have support for. This means nvFuser is able to power new PyTorch systems like TorchDynamo and FuncTorch to combine the flexibility PyTorch is known for with unbeatable performance.
nvFuser Performance
Before getting into how to use nvFuser, in this section we’ll show the improvements in training speed nvFuser provides for a variety of models from the HuggingFace Transformers and PyTorch Image Models (TIMM) repositories and we will discuss current gaps in nvFuser performance that are under development today. All performance numbers in this section were taken using an NVIDIA A100 40GB GPU, and used either FuncTorch alone or Functorch with TorchDynamo.
HuggingFace Transformer Benchmarks
nvFuser can dramatically accelerate training of HuggingFace Transformers when combined with another important optimization (more on that in a moment). Performance improvements can be seen in Figure 1 to range between 1.12x and 1.50x across a subset of popular HuggingFace Transformer networks.
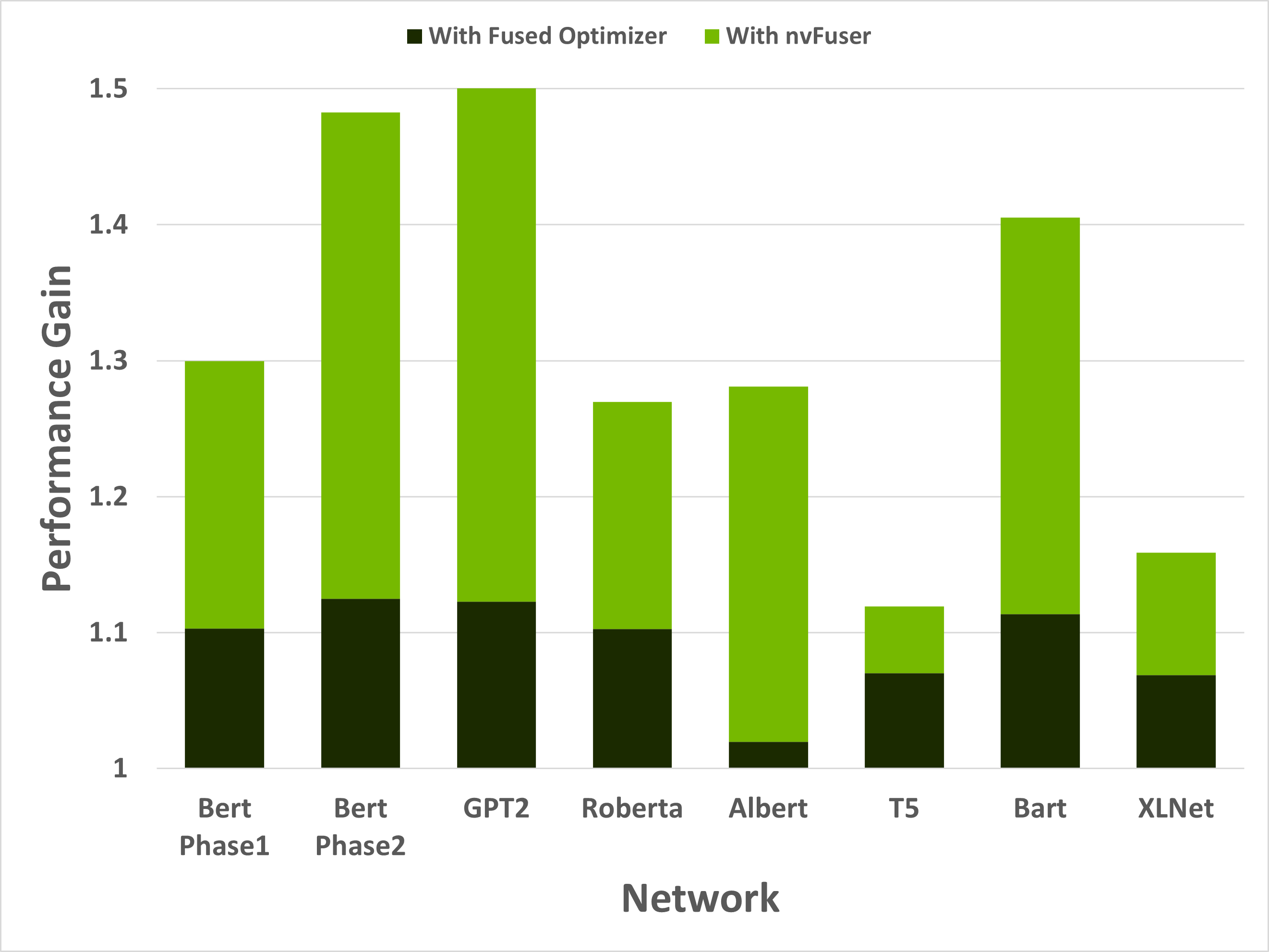
Figure 1: Performance gains of 8 training scenarios from HuggingFace’s Transformer repository. First performance boost in the dark green is due to replacing the optimizer with an NVIDIA Apex fused AdamW optimizer. The light green is due to adding nvFuser. Models were run with batch size and sequence lengths of [64, 128], [8, 512], [2, 1024], [64, 128], [8, 512], [8, src_seql=512, tgt_seql=128], [8, src_seql=1024, tgt_seql=128], and [8, 512] respectively. All networks were run with Automatic Mixed Precision (AMP) enabled with dtype=float16.
While these speedups are significant, it’s important to understand that nvFuser doesn’t (yet) automate everything about running networks quickly. For HuggingFace Transformers, for example, it was important to use the AdamW fused optimizer from NVIDIA’s Apex repository as the optimizer otherwise consumed a large portion of runtime. Using the fused AdamW optimizer to make the network faster exposes the next major performance bottleneck — memory bound operations. These operations are optimized by nvFuser, providing another large performance boost. With the fused optimizer and nvFuser enabled, the training speed of these networks improved between 1.12x to 1.5x.
HuggingFace Transformer models were run with the torch.amp module. (“amp” stands for Automated Mixed Precision, see the “What Every User Should Know about Mixed Precision in PyTorch” blog post for details.) An option to use nvFuser was added to HuggingFace’sTrainer. If you have TorchDynamo installed you can activate it to enable nvFuser in HuggingFace by passing torchdynamo = ‘nvfuser’ to the Trainer class.
nvFuser has great support for normalization kernels and related fusions frequently found in Natural Language Processing (NLP) models, and it is recommended users try nvFuser in their NLP workloads.
PyTorch Image Models (TIMM) Benchmarks
nvFuser, can also significantly reduce the training time of TIMM networks, up to over 1.3x vs. eager PyTorch, and up to 1.44x vs. eager PyTorch when combined with the torch.amp module. Figure 1 shows nvFuser’s speedup without torch.amp, and when torch.amp is used with the NHWC (“channels last”) and NCHW (“channels first”) formats. nvFuser is integrated in TIMM through FuncTorch tracing directly (without TorchDynamo) and can be used by adding the –aot-autograd command line argument when running the TIMM benchmark or training script.
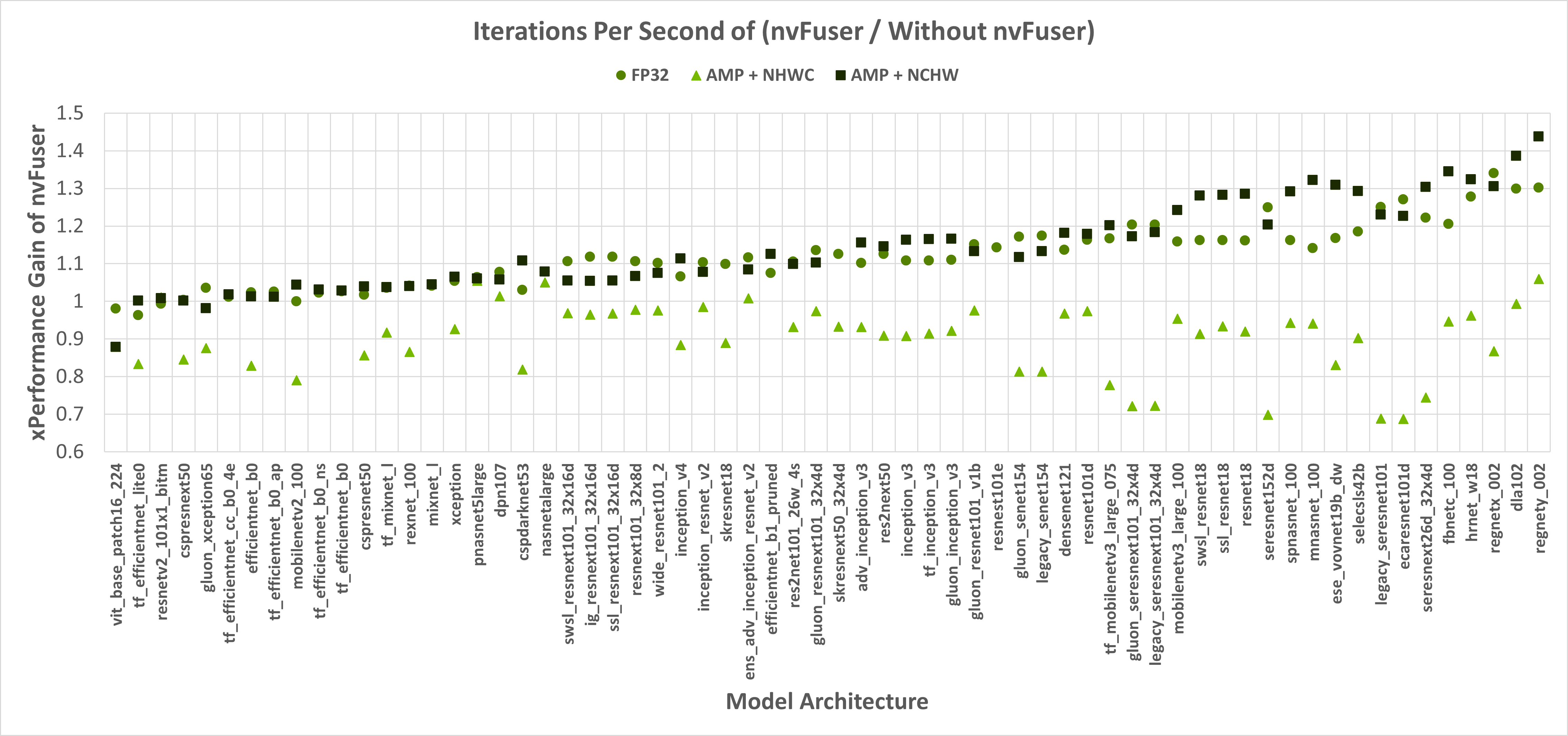
Figure 1: The Y-axis is the performance gain nvFuser provides over not using nvFuser. A value of 1.0 means no change in perf, 2.0 would mean nvFuser is twice as fast, 0.5 would mean nvFuser takes twice the time to run. Square markers are with float16 Automatic Mixed Precision (AMP) and channels first contiguous inputs, circle markers are float32 inputs, and triangles are with float16 AMP and channels last contiguous inputs. Missing data points are due to an error being encountered when tracing.
When running with float32 precision nvFuser provides a 1.12x geometric mean (“geomean”) speedup on TIMM networks, and when running with torch.amp and “channels first” it provides a 1.14x geomean speedup. However, nvFuser currently doesn’t speedup torch.amp and “channels last” training (a .9x geomean regression), so we recommend not using it in those cases. We are actively working on improving “channels last” performance now, and soon we will have two additional optimization strategies (grid persistent optimizations for channels-last normalizations and fast transposes) which we expect will provide speedups comparable to “channels first” in PyTorch version 1.13 and later. Many of nvFuser’s optimizations can also help in inference cases. However, in PyTorch when running inference on small batch sizes, the performance is typically limited by CPU overhead, which nvFuser can’t completely remove or fix. Therefore, typically the most important optimization for inference is to enable CUDA Graphs when possible. Once CUDA Graphs is enabled, then it can also be beneficial to also enable fusion through nvFuser. Performance of inference is shown in Figure 2 and Figure 3. Inference is only run with float16 AMP as it is uncommon to run inference workloads in full float32 precision.
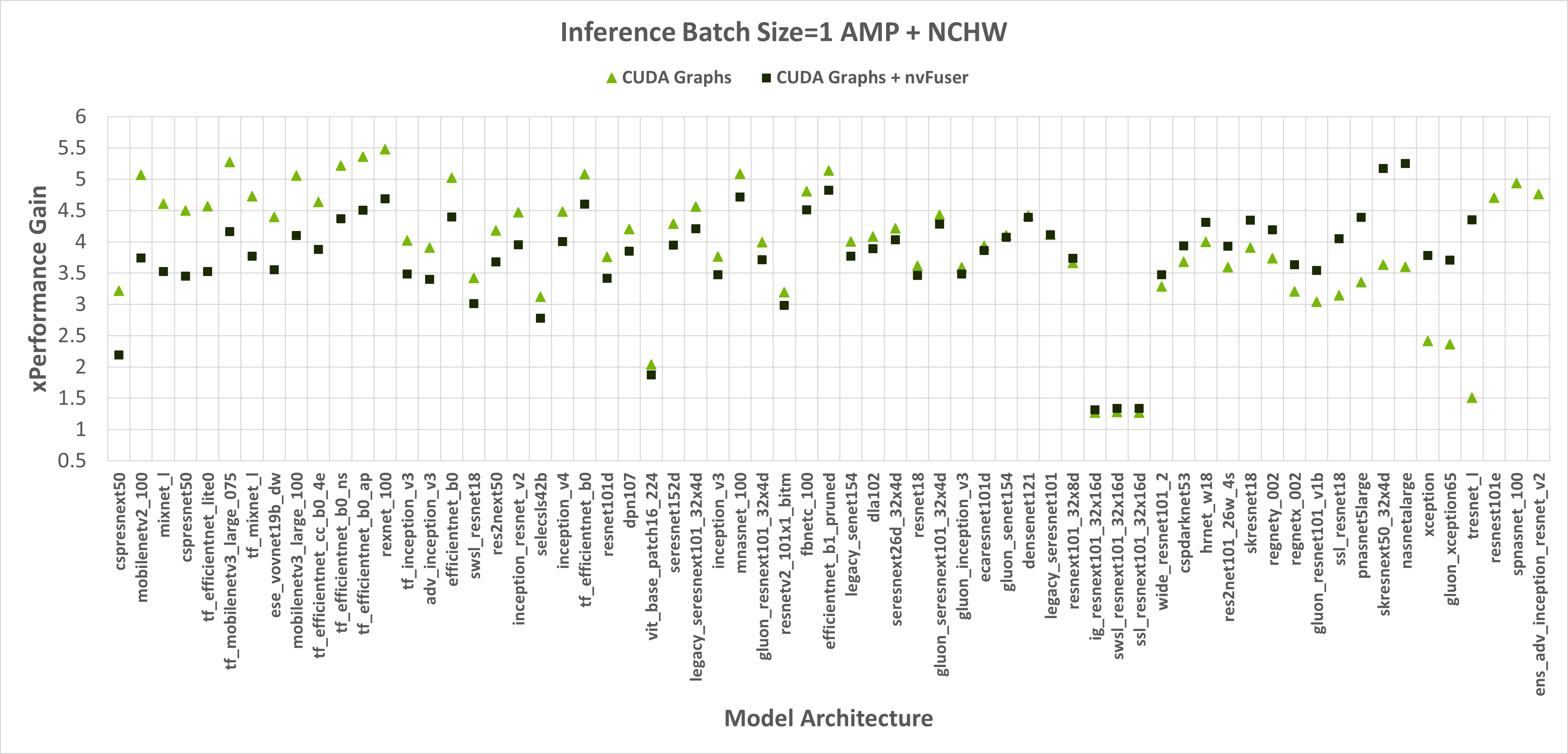
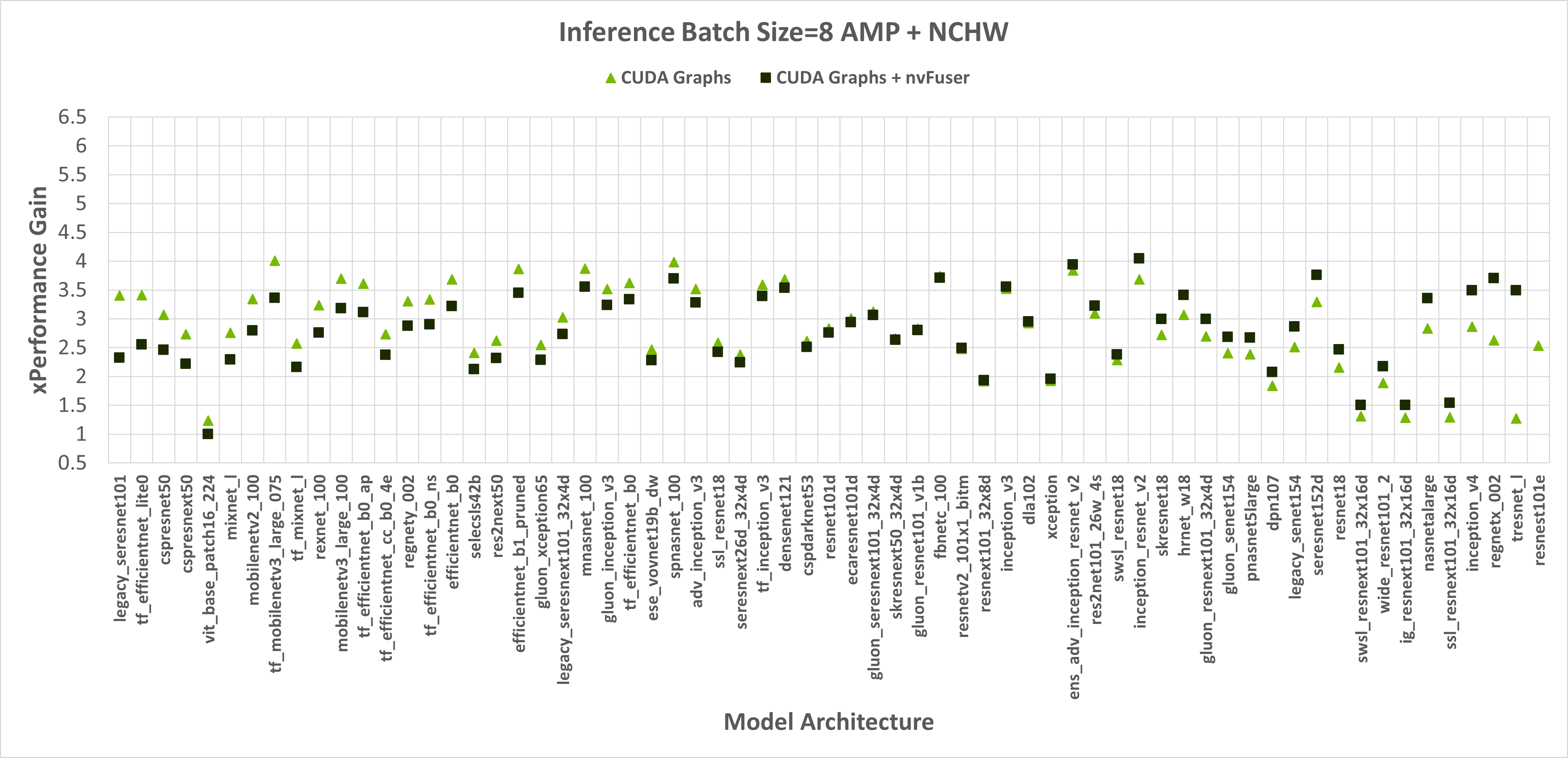
Figure 2: Performance gains of enabling CUDA Graphs, and CUDA Graphs with nvFuser compared to the performance of native PyTorch without CUDA Graphs and nvFuser across TIMM models with float16 AMP, channels first inputs, and a batch size of 1 and 8 respectively. There is a geomean speedup of 2.74x with CUDA Graphs and 2.71x with CUDA Graphs + nvFuser respectively. nvFuser provides a maximum regression of 0.68x and a maximum performance gain of 2.74x (relative to CUDA Graphs without nvFuser). Performance gain is measured relative to the average time per iteration PyTorch takes without CUDA Graphs and without nvFuser. Models are sorted by how much additional performance nvFuser is providing.
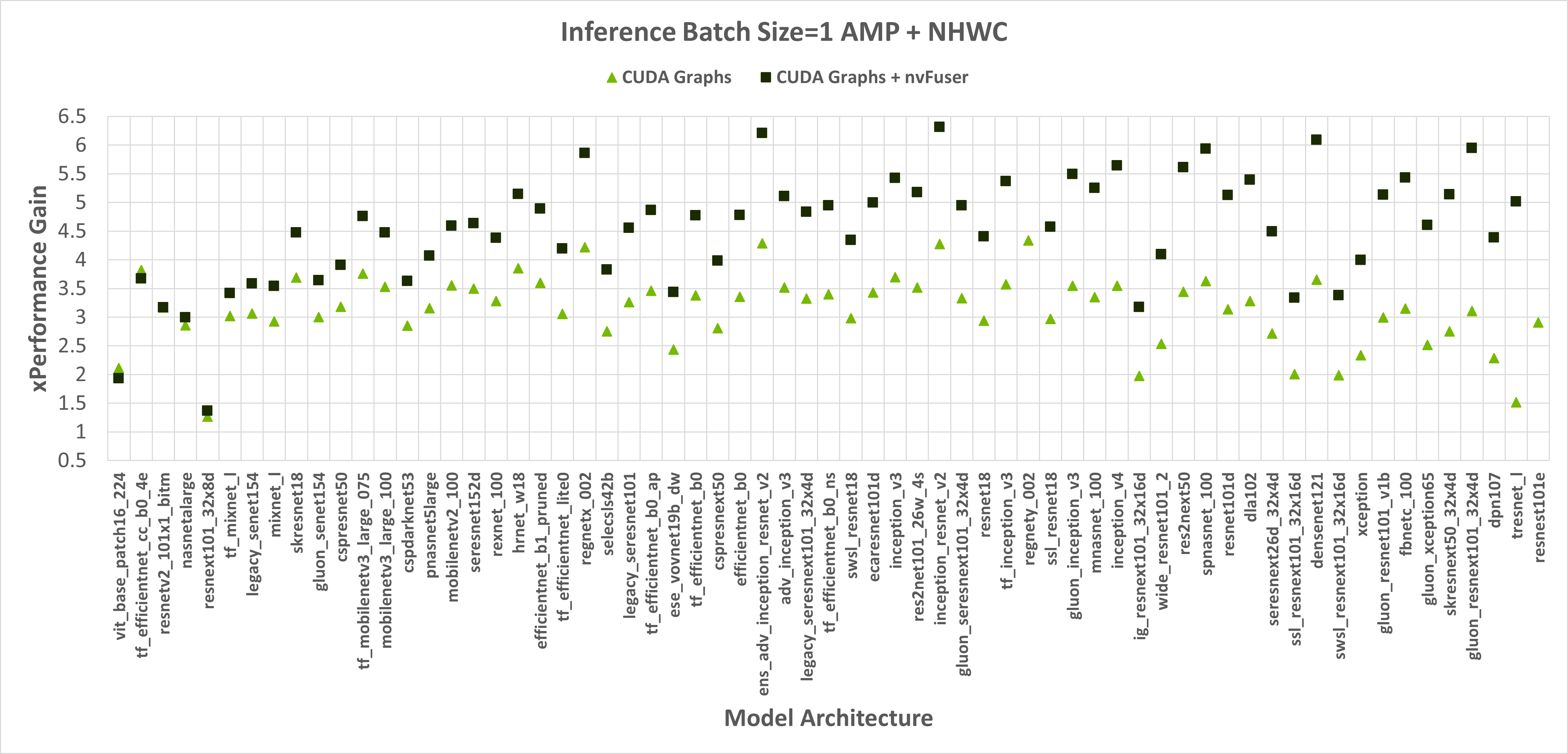
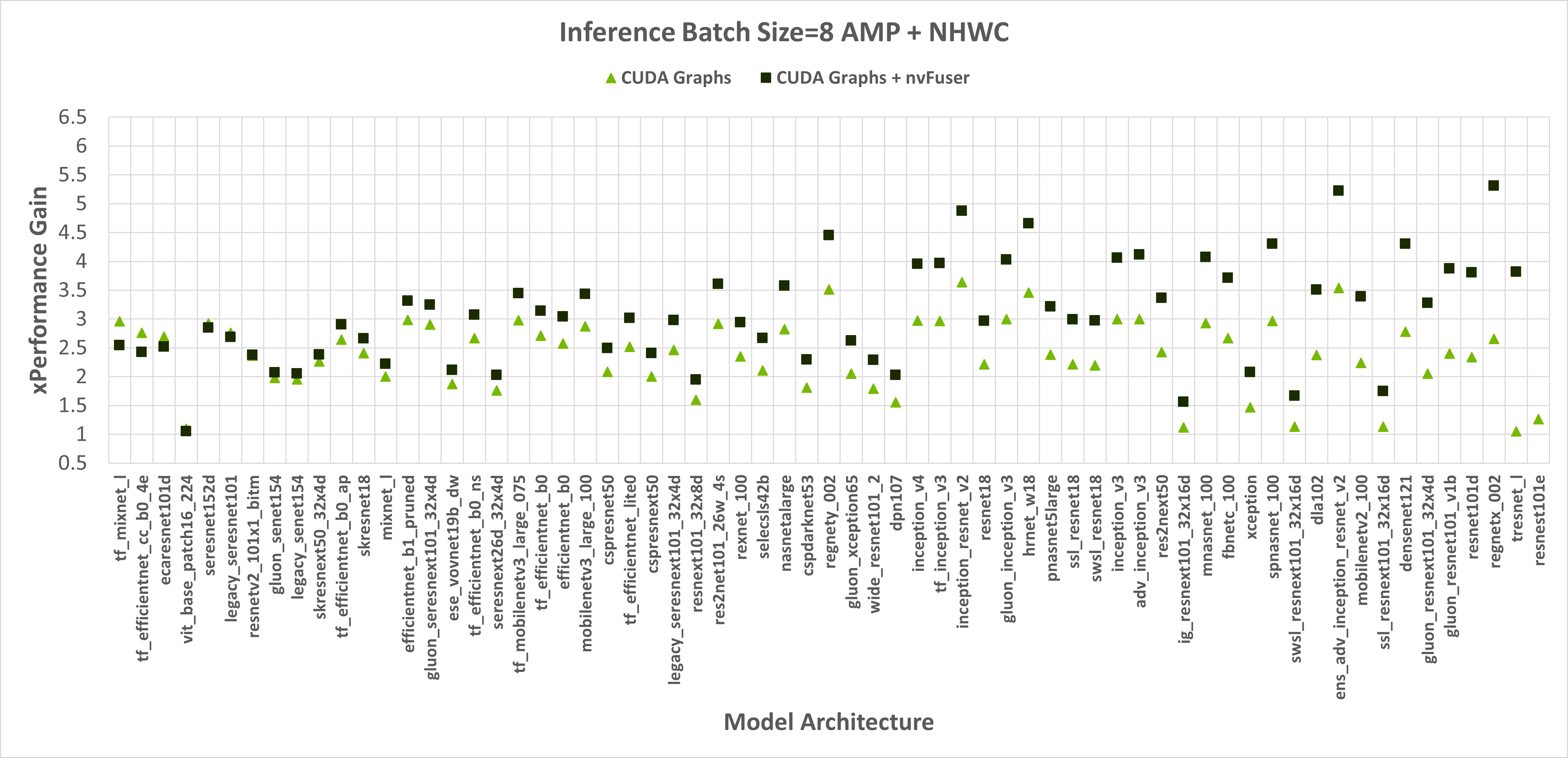
Figure 3: Performance gains of enabling CUDA Graphs, and CUDA Graphs with nvFuser compared to the performance of native PyTorch without CUDA Graphs and nvFuser across TIMM models with AMP, channels last inputs, and a batch size of 1 and 8 respectively. There is a geomean speedup of 2.29x with CUDA Graphs and 2.95x with CUDA Graphs + nvFuser respectively. nvFuser provides a maximum regression of 0.86x and a maximum performance gain of 3.82x (relative to CUDA Graphs without nvFuser). Performance gain is measured relative to the average time per iteration PyTorch takes without CUDA Graphs and without nvFuser. Models are sorted by how much additional performance nvFuser is providing.
So far nvFuser performance has not been tuned for inference workloads so its performance benefit is not consistent across all cases. However, there are still many models that benefit significantly from nvFuser during inference and we encourage users to try nvFuser in inference workloads to see if you would benefit today. Performance of nvFuser in inference workloads will improve in the future and if you’re interested in nvFuser in inference workloads please reach out to us on the PyTorch forums.
Getting Started – Accelerate Your Scripts with nvFuser
We’ve created a tutorial demonstrating how to take advantage of nvFuser to accelerate part of a standard transformer block, and how nvFuser can be used to define fast and novel operations. There are still some rough edges in nvFuser that we’re working hard on improving as we’ve outlined in this blog post. However we’ve also demonstrated some great improvements for training speed on multiple networks in HuggingFace and TIMM and we expect there are opportunities in your networks where nvFuser can help today, and many more opportunities it will help in the future.
If you would like to learn more about nvFuser we recommend watching our presentations from NVIDIA’s GTC conference GTC 2022 and GTC 2021.