Posted by Mathieu Guillame-Bert, Sebastian Bruch, Josh Gordon, Jan Pfeifer
We are happy to open source TensorFlow Decision Forests (TF-DF). TF-DF is a collection of production-ready state-of-the-art algorithms for training, serving and interpreting decision forest models (including random forests and gradient boosted trees). You can now use these models for classification, regression and ranking tasks – with the flexibility and composability of the TensorFlow and Keras.
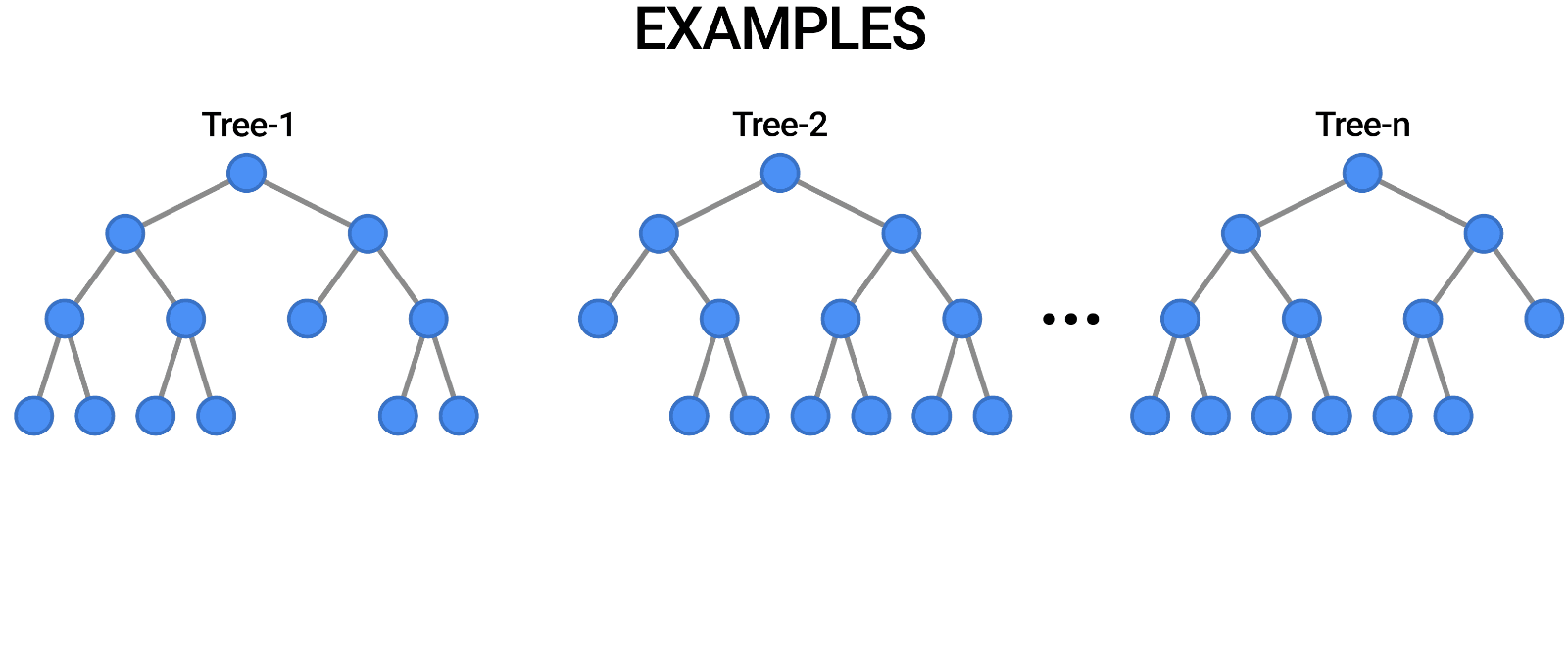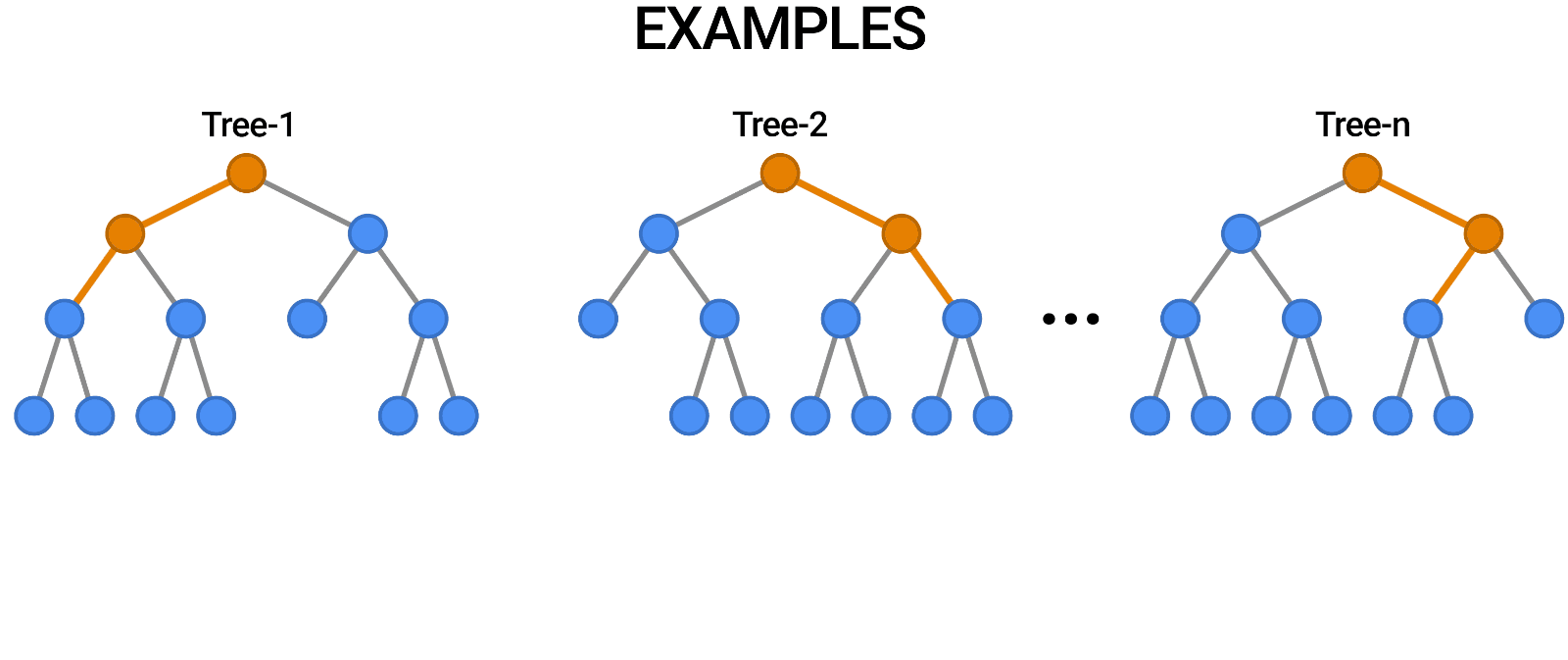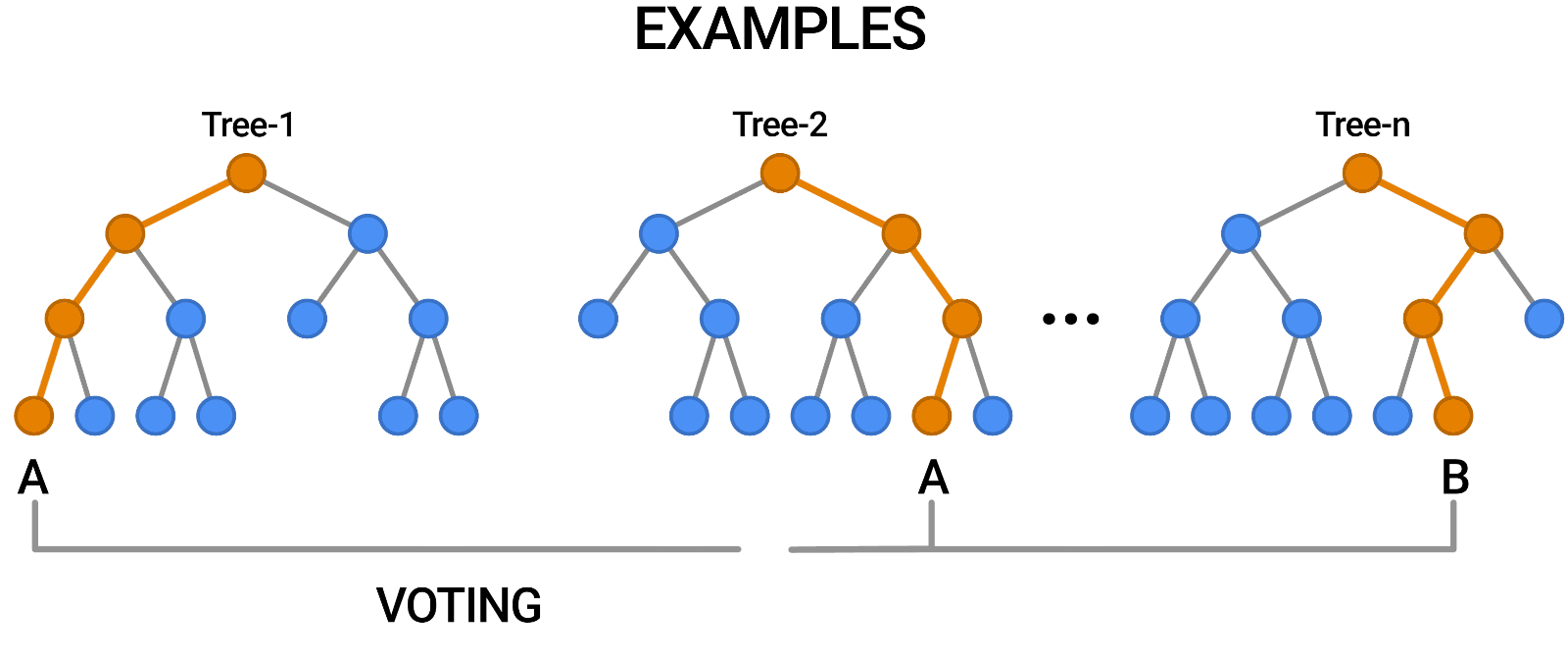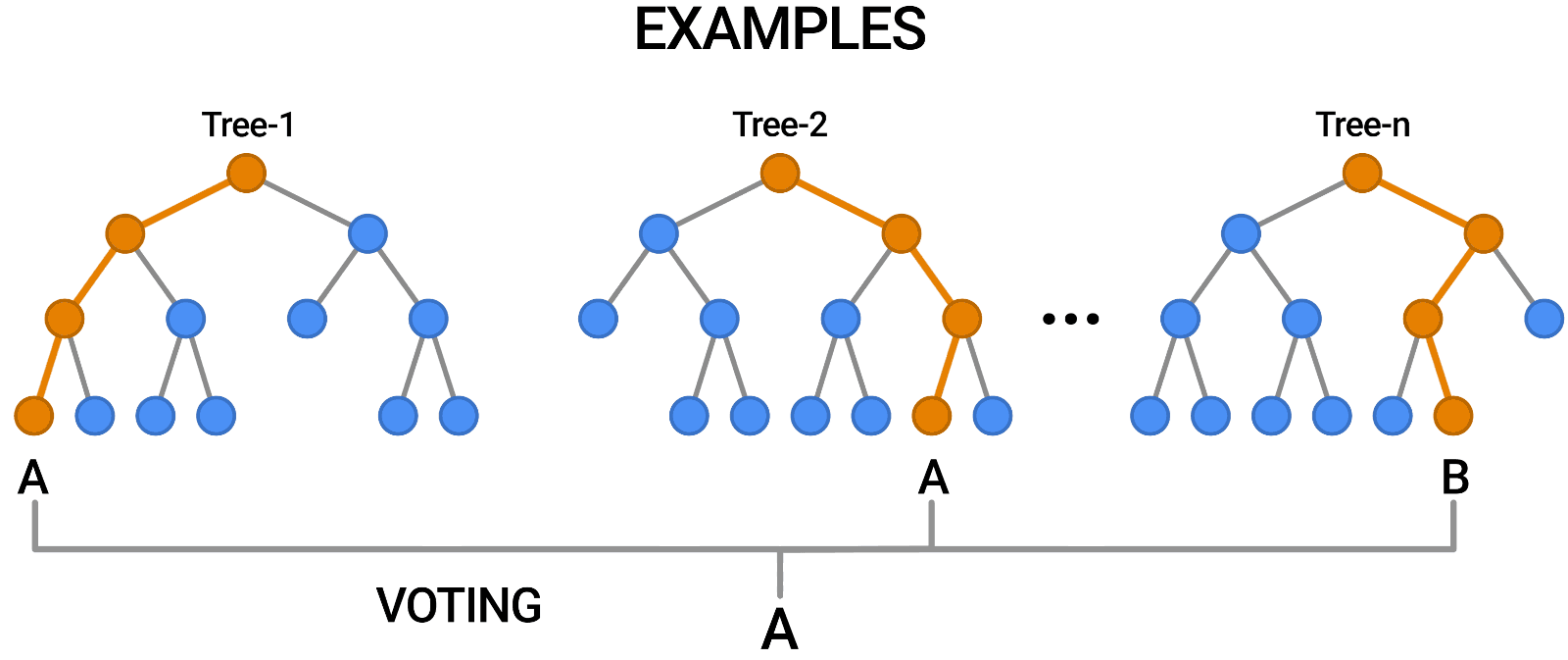 |
| Random Forests are a popular type of decision forest model. Here, you can see a forest of trees classifying an example by voting on the outcome. |
About decision forests
Decision forests are a family of machine learning algorithms with quality and speed competitive with (and often favorable to) neural networks, especially when you’re working with tabular data. They’re built from many decision trees, which makes them easy to use and understand – and you can take advantage of a plethora of interpretability tools and techniques that already exist today.
TF-DF brings this class of models along with a suite of tailored tools to TensorFlow users:
- Beginners will find it easier to develop and explain decision forest models. There is no need to explicitly list or pre-process input features (as decision forests can naturally handle numeric and categorical attributes), specify an architecture (for example, by trying different combinations of layers like you would in a neural network), or worry about models diverging. Once your model is trained, you can plot it directly or analyse it with easy to interpret statistics.
- Advanced users will benefit from models with very fast inference time (sub-microseconds per example in many cases). And, this library offers a great deal of composability for model experimentation and research. In particular, it is easy to combine neural networks and decision forests.
If you’re already using decision forests outside of TensorFlow, here’s a little of what TF-DF offers:
- It provides a slew of state-of-the-art Decision Forest training and serving algorithms such as random forests, gradient-boosted trees, CART, (Lambda)MART, DART, Extra Trees, greedy global growth, oblique trees, one-side-sampling, categorical-set learning, random categorical learning, out-of-bag evaluation and feature importance, and structural feature importance.
- This library can serve as a bridge to the rich TensorFlow ecosystem by making it easier for you to integrate tree-based models with various TensorFlow tools, libraries, and platforms such as TFX.
- And for users new to neural networks, you can use decision forests as an easy way to get started with TensorFlow, and continue to explore neural networks from there.
Code example
A good example is worth a thousand words. So in this blog post, we will show how easy it is to train a model with TensorFlow Decision Forests. More examples are available on the TF-DF website and GitHub page. You may also watch our talk at Google I/O 2021 .
Training a model
Let’s start with a minimal example where we train a random forest model on the tabular Palmer’s Penguins dataset. The objective is to predict the species of an animal from its characteristics. The dataset contains both numerical and categorical features and is stored as a csv file.
 |
| Three examples from the Palmer’s Penguins dataset. |
Let’s train a model:
# Install TensorFlow Decision Forests
!pip install tensorflow_decision_forests
# Load TensorFlow Decision Forests
import tensorflow_decision_forests as tfdf
# Load the training dataset using pandas
import pandas
train_df = pandas.read_csv("penguins_train.csv")
# Convert the pandas dataframe into a TensorFlow dataset
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_df, label="species")
# Train the model
model = tfdf.keras.RandomForestModel()
model.fit(train_ds)Observe that nowhere in the code did we provide input features or hyperparameters. That means, TensorFlow Decision Forests will automatically detect the input features from this dataset and use default values for all hyperparameters.
Evaluating a model
Now, let’s evaluate the quality of our model:
# Load the testing dataset
test_df = pandas.read_csv("penguins_test.csv")
# Convert it to a TensorFlow dataset
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df, label="species")
# Evaluate the model
model.compile(metrics=["accuracy"])
print(model.evaluate(test_ds))
# >> 0.979311
# Note: Cross-validation would be more suited on this small dataset.
# See also the "Out-of-bag evaluation" below.
# Export the model to a TensorFlow SavedModel
model.save("project/my_first_model")Easy, right? And a default RandomForest model with default hyperparameters provides a quick and good baseline for most problems. Decision forests in general will train quickly for small and medium sized problems, require less hyperparameter tuning compared to many other types of models, and will often provide strong results.
Interpreting a model
Now that you have looked at the accuracy of the trained model, let’s consider its interpretability. Interpretability is important if you wish to understand and explain the phenomenon being modeled, debug a model, or begin to trust its decisions. As noted above, we have provided a number of tools to interpret trained models, beginning with plots.
tfdf.model_plotter.plot_model_in_colab(model, tree_idx=0)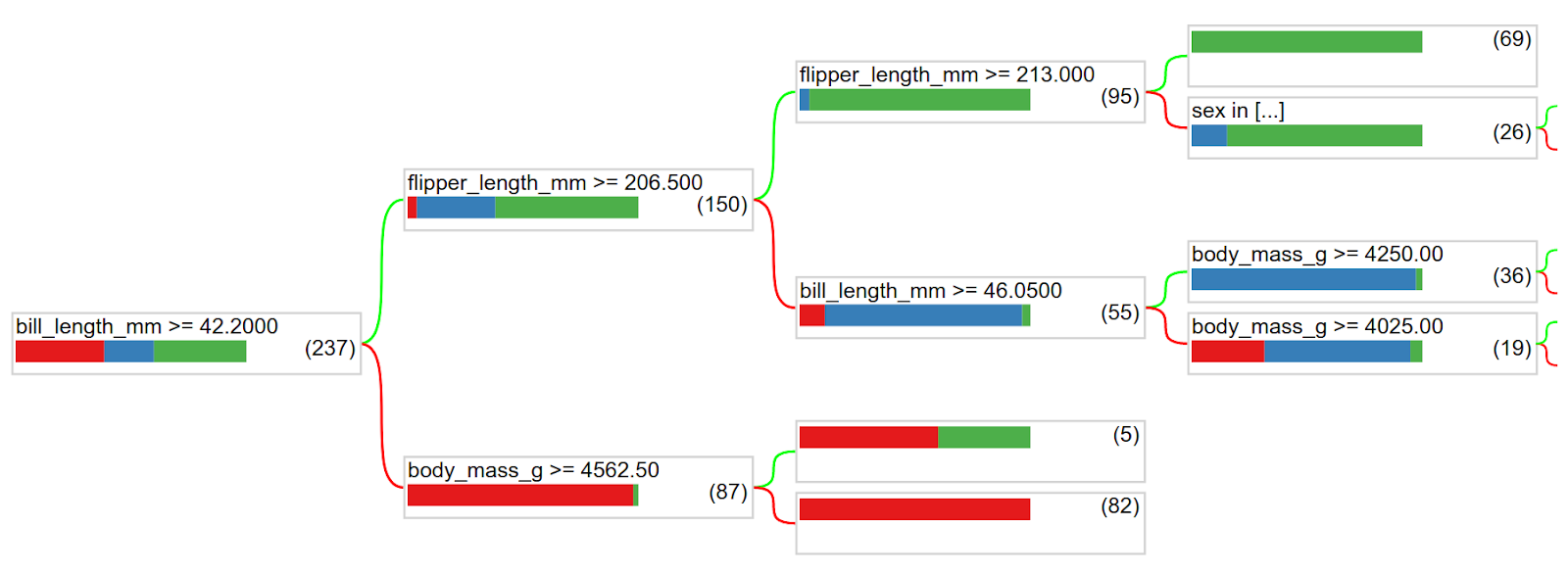
You can visually follow the tree structure. In this tree, the first decision is based on the bill length. Penguins with bills longer than 42.2mm are likely to be the blue (Gentoo) or green (Chinstrap) species, while the ones with shorter bills are likely to be of the red specy (Adelie).
For the first group, the tree then asks about the flipper length. Penguins with flippers longer than 206.5mm are likely to be of the green species (Chinstrap), while the remaining are likely to be of the blue species (Gentoo).
Model statistics are complementary additions to plots. Example statistics include:
- How many times is each feature used?
- How fast did the model train (in number of trees and time)?
- How are the nodes distributed in the tree structure (for example, what is the length of most branches?)
These and answers to more such inquiries are included in the model summary and accessible in the model inspector.
# Print all the available information about the model
model.summary()
>> Input Features (7):
>> bill_depth_mm
>> bill_length_mm
>> body_mass_g
>> ...
>> Variable Importance:
>> 1. "bill_length_mm" 653.000000 ################
>> ...
>> Out-of-bag evaluation: accuracy:0.964602 logloss:0.102378
>> Number of trees: 300
>> Total number of nodes: 4170
>> ...
# Get feature importance as a array
model.make_inspector().variable_importances()["MEAN_DECREASE_IN_ACCURACY"]
>> [("flipper_length_mm", 0.149),
>> ("bill_length_mm", 0.096),
>> ("bill_depth_mm", 0.025),
>> ("body_mass_g", 0.018),
>> ("island", 0.012)]In the example above, the model was trained with default hyperparameter values. This is a good first solution, but “tuning” the hyper-parameters can often further improve the quality of the model. That can be done as in the following:
# List all the other available learning algorithms
tfdf.keras.get_all_models()
>> [tensorflow_decision_forests.keras.RandomForestModel,
>> tensorflow_decision_forests.keras.GradientBoostedTreesModel,
>> tensorflow_decision_forests.keras.CartModel]
# Display the hyper-parameters of the Gradient Boosted Trees model
? tfdf.keras.GradientBoostedTreesModel
>> A GBT (Gradient Boosted [Decision] Tree) is a set of shallow decision trees trained sequentially. Each tree is trained to predict and then "correct" for the errors of the previously trained trees (more precisely each tree predicts the gradient of the loss relative to the model output)..
...
Attributes:
num_trees: num_trees: Maximum number of decision trees. The effective number of trained trees can be smaller if early stopping is enabled. Default: 300.
max_depth: Maximum depth of the tree. `max_depth=1` means that all trees will be roots. Negative values are ignored. Default: 6.
...
# Create another model with specified hyper-parameters
model = tfdf.keras.GradientBoostedTreesModel(
num_trees=500,
growing_strategy="BEST_FIRST_GLOBAL",
max_depth=8,
split_axis="SPARSE_OBLIQUE",
)
# Evaluate the model
model.compile(metrics=["accuracy"])
print(model.evaluate(test_ds))
# >> 0.986851Next steps
We hope you enjoyed reading this short demonstration of TensorFlow Decision Forests, and that you are as excited to use it and contribute to it as we are to develop it.
With TensorFlow Decision Forests, you can now train state-of-the-art Decision Forests models with maximum speed and quality and with minimal effort in TensorFlow. And if you feel adventurous, you can now combine decision forests and neural networks together to create new types of hybrid models.
If you would like to learn more about the TensorFlow Decision Forests library, we have put together a number of resources and recommend the following:
- You can find the complete code from this article in the beginner colab notebook, and also check out this intermediate notebook and this advanced one.
- You can watch this video from Google I/O.
- You can check out and star the TensorFlow Decision Forests project on GitHub.
- Existing TensorFlow users will benefit from reading our migration guide if you’re interested in adding decision forests to your existing workflow.
- Advanced users may want to follow the Yggdrasil Decision ForestsYggdrasil Decision Forest GitHub project, the c++ engine powering TensorFlow Decision Forests, where the algorithms are implemented.
If you have any questions, please ask them on the discuss.tensorflow.org using the tag “TFDF” and we’ll do our best to help. Thanks again.