Amazon SageMaker Autopilot, a low-code machine learning (ML) service that automatically builds, trains, and tunes the best ML models based on tabular data, is now integrated with Amazon SageMaker Pipelines, the first purpose-built continuous integration and continuous delivery (CI/CD) service for ML. This enables the automation of an end-to-end flow of building ML models using Autopilot and integrating models into subsequent CI/CD steps.
So far, to launch an Autopilot experiment within Pipelines, you have to build a model-building workflow by writing custom integration code with Pipelines Lambda or Processing steps. For more information, see Move Amazon SageMaker Autopilot ML models from experimentation to production using Amazon SageMaker Pipelines.
With the support for Autopilot as a native step within Pipelines, you can now add an automated training step (AutoMLStep) in Pipelines and invoke an Autopilot experiment with Ensembling training mode. For example, if you’re building a training and evaluation ML workflow for a fraud detection use case with Pipelines, you can now launch an Autopilot experiment using the AutoML step, which automatically runs multiple trials to find the best model on a given input dataset. After the best model is created using the Model step, its performance can be evaluated on test data using the Transform step and a Processing Step for a custom evaluation script within Pipelines. Eventually, the model can be registered into the SageMaker model registry using the Model step in combination with a Condition step.
In this post, we show how to create an end-to-end ML workflow to train and evaluate a SageMaker generated ML model using the newly launched AutoML step in Pipelines and register it with the SageMaker model registry. The ML model with the best performance can be deployed to a SageMaker endpoint.
Dataset overview
We use the publicly available UCI Adult 1994 Census Income dataset to predict if a person has an annual income of greater than $50,000 per year. This is a binary classification problem; the options for the income target variable are either <=50K or >50K.
The dataset contains 32,561 rows for training and validation and 16,281 rows for testing with 15 columns each. This includes demographic information about individuals and class as the target column indicating the income class.
| Column Name | Description |
| age | Continuous |
| workclass | Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked |
| fnlwgt | Continuous |
| education | Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool |
| education-num | Continuous |
| marital-status | Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse |
| occupation | Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces |
| relationship | Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried |
| race | White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black |
| sex | Female, Male |
| capital-gain | Continuous |
| capital-loss | Continuous |
| hours-per-week | Continuous |
| native-country | United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holand-Netherlands |
| class | Income class, either <=50K or >50K |
Solution overview
We use Pipelines to orchestrate different pipeline steps required to train an Autopilot model. We create and run an Autopilot experiment as part of an AutoML step as described in this tutorial.
The following steps are required for this end-to-end Autopilot training process:
- Create and monitor an Autopilot training job using the
AutoMLStep. - Create a SageMaker model using
ModelStep. This step fetches the best model’s metadata and artifacts rendered by Autopilot in the previous step. - Evaluate the trained Autopilot model on a test dataset using
TransformStep. - Compare the output from the previously run
TransformStepwith the actual target labels usingProcessingStep. - Register the ML model to the SageMaker model registry using
ModelStep, if the previously obtained evaluation metric exceeds a predefined threshold inConditionStep. - Deploy the ML model as a SageMaker endpoint for testing purposes.
Architecture
The architecture diagram below illustrates the different pipeline steps necessary to package all the steps in a reproducible, automated, and scalable SageMaker Autopilot training pipeline. The data files are read from the S3 bucket and the pipeline steps are called sequentially.

Walkthrough
This post provides a detailed explanation of the pipeline steps. We review the code and discuss the components of each step. To deploy the solution, refer to the example notebook, which provides step-by-step instructions for implementing an Autopilot MLOps workflow using Pipelines.
Prerequisites
Complete the following prerequisites:
- Set up an AWS account.
- Create an Amazon SageMaker Studio environment.
- Create an AWS Identity and Access Management (IAM) role. For instructions, refer to Creating a role to delegate permissions to an IAM user. Specifically, you create a SageMaker execution role. You may attach the AmazonSageMakerFullAccess managed IAM policy to it for a working demo. However, this should be scoped down further for improved security.
- Navigate to Studio and upload the files from the notebook example directory on GitHub.
- Open the SageMaker notebook
sagemaker_autopilot_pipelines_native_auto_ml_step.ipynband run the cells in sequential order. Follow the instructions on how to initialize the notebook and get a sample dataset.
When the dataset is ready to use, we need to set up Pipelines to establish a repeatable process to automatically build and train ML models using Autopilot. We use the SageMaker SDK to programmatically define, run, and track an end-to-end ML training pipeline.
Pipeline Steps
In the following sections, we go through the different steps in the SageMaker pipeline, including AutoML training, model creation, batch inference, evaluation, and conditional registration of the best model. The following diagram illustrates the entire pipeline flow.

AutoML training step
An AutoML object is used to define the Autopilot training job run and can be added to the SageMaker pipeline by using the AutoMLStep class, as shown in the following code. The ensembling training mode needs to be specified, but other parameters can be adjusted as needed. For example, instead of letting the AutoML job automatically infer the ML problem type and objective metric, these could be hardcoded by specifying the problem_type and job_objective parameters passed to the AutoML object.
Model creation step
The AutoML step takes care of generating various ML model candidates, combining them, and obtaining the best ML model. Model artifacts and metadata are automatically stored and can be obtained by calling the get_best_auto_ml_model() method on the AutoML training step. These can then be used to create a SageMaker model as part of the Model step:
Batch transform and evaluation steps
We use the Transformer object for batch inference on the test dataset, which can then be used for evaluation purposes. The output predictions are compared to the actual or ground truth labels using a Scikit-learn metrics function. We evaluate our results based on the F1 score. The performance metrics are saved to a JSON file, which is referenced when registering the model in the subsequent step.
Conditional registration steps
In this step, we register our new Autopilot model to the SageMaker model registry, if it exceeds the predefined evaluation metric threshold.
Create and run the pipeline
After we define the steps, we combine them into a SageMaker pipeline:
The steps are run in sequential order. The pipeline runs all the steps for an AutoML job using Autopilot and Pipelines for training, model evaluation, and model registration.
You can view the new model by navigating to the model registry on the Studio console and opening AutoMLModelPackageGroup. Choose any version of a training job to view the objective metrics on the Model quality tab.

You can view the explainability report on the Explainability tab to understand your model’s predictions.

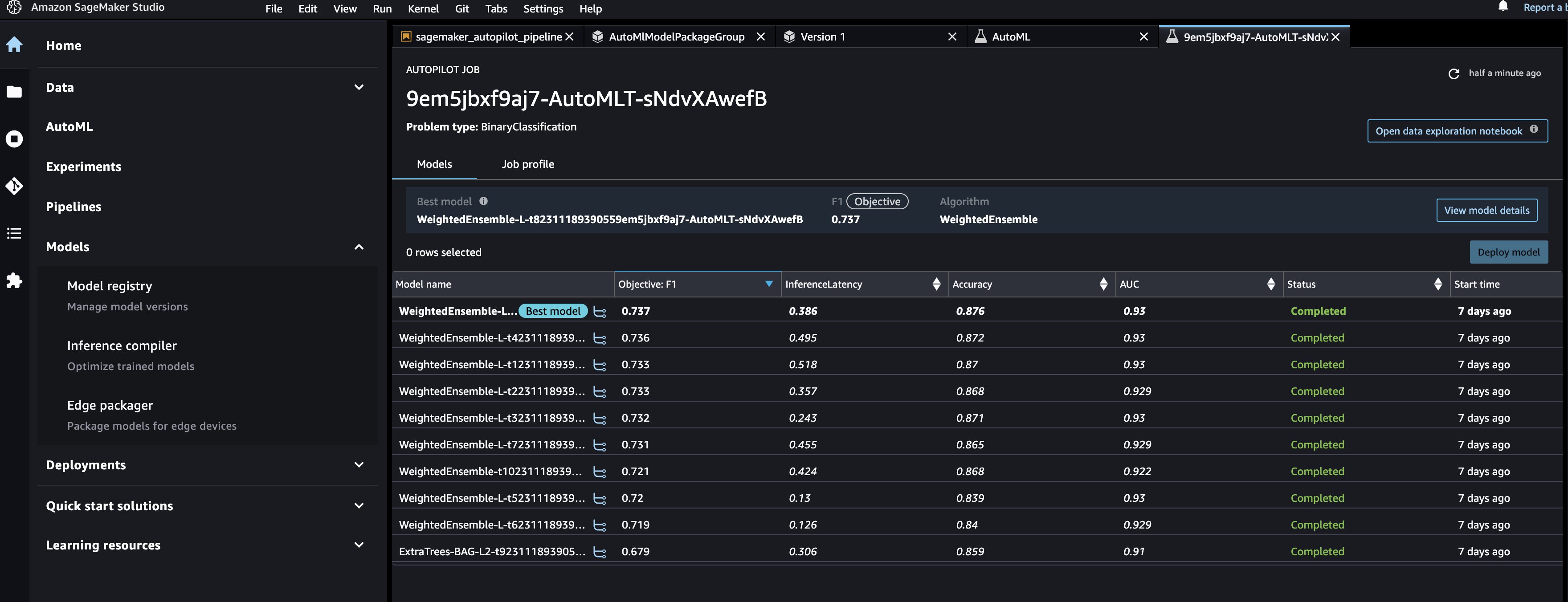
To view the underlying Autopilot experiment for all the models created in AutoMLStep, navigate to the AutoML page and choose the job name.
Deploy the model
After we have manually reviewed the ML model’s performance, we can deploy our newly created model to a SageMaker endpoint. For this, we can run the cells in the notebook that create the model endpoint using the model configuration saved in the SageMaker model registry.
Note that this script is shared for demonstration purposes, but it’s recommended to follow a more robust CI/CD pipeline for production deployment for ML inference. For more information, refer to Building, automating, managing, and scaling ML workflows using Amazon SageMaker Pipelines.
Summary
This post describes an easy-to-use ML pipeline approach to automatically train tabular ML models (AutoML) using Autopilot, Pipelines, and Studio. AutoML improves ML practitioners’ efficiency, accelerating the path from ML experimentation to production without the need for extensive ML expertise. We outline the respective pipeline steps needed for ML model creation, evaluation, and registration. Get started by trying the example notebook to train and deploy your own custom AutoML models.
For more information on Autopilot and Pipelines, refer to Automate model development with Amazon SageMaker Autopilot and Amazon SageMaker Pipelines.
Special thanks to everyone who contributed to the launch: Shenghua Yue, John He, Ao Guo, Xinlu Tu, Tian Qin, Yanda Hu, Zhankui Lu, and Dewen Qi.
About the Authors
 Janisha Anand is a Senior Product Manager in the SageMaker Low/No Code ML team, which includes SageMaker Autopilot. She enjoys coffee, staying active, and spending time with her family.
Janisha Anand is a Senior Product Manager in the SageMaker Low/No Code ML team, which includes SageMaker Autopilot. She enjoys coffee, staying active, and spending time with her family.
 Marcelo Aberle is an ML Engineer at AWS AI. He helps Amazon ML Solutions Lab customers build scalable ML(-Ops) systems and frameworks. In his spare time, he enjoys hiking and cycling in the San Francisco Bay Area.
Marcelo Aberle is an ML Engineer at AWS AI. He helps Amazon ML Solutions Lab customers build scalable ML(-Ops) systems and frameworks. In his spare time, he enjoys hiking and cycling in the San Francisco Bay Area.
 Geremy Cohen is a Solutions Architect with AWS where he helps customers build cutting-edge, cloud-based solutions. In his spare time, he enjoys short walks on the beach, exploring the bay area with his family, fixing things around the house, breaking things around the house, and BBQing.
Geremy Cohen is a Solutions Architect with AWS where he helps customers build cutting-edge, cloud-based solutions. In his spare time, he enjoys short walks on the beach, exploring the bay area with his family, fixing things around the house, breaking things around the house, and BBQing.
 Shenghua Yue is a Software Development Engineer at Amazon SageMaker. She focuses on building ML tools and products for customers. Outside of work, she enjoys the outdoors, yoga, and hiking.
Shenghua Yue is a Software Development Engineer at Amazon SageMaker. She focuses on building ML tools and products for customers. Outside of work, she enjoys the outdoors, yoga, and hiking.