Imagine you’re a machine learning practitioner and you want to solve some classification problem, like classifying groups of colored squares as being either 1s or 0s. Here’s what you would typically do: collect a large dataset of examples, label the data, and train a classifier:

But humans don’t learn like this. We have a very powerful and intuitive mechanism for communicating information about the world – language!

With just the phrase at least 2 red squares, we’ve summarized the entire dataset presented above in a much more efficient manner.
Language is a crucial medium for human learning: we use it to convey beliefs about the world, teach others, and describe things that are hard to experience directly. Thus, language ought to be a simple and effective way to supervise machine learning models. Yet past approaches to learning from language have struggled to scale up to the general tasks targeted by modern deep learning systems and the freeform language explanations used in these domains. In two short papers presented at ACL 2020 this year, we use deep neural models to learn from language explanations to help tackle a variety of challenging tasks in natural language processing (NLP) and computer vision.
- ExpBERT: Representation Engineering with Natural Language Explanations
- Shaping Visual Representations with Language for Few-shot Classification
What’s the challenge?
Given that language is such an intuitive interface for humans to teach others,
why is it so hard to use language for machine learning?
The principal challenge is the grounding
problem: understanding language
explanations in the context of other inputs. Building models that can
understand rich and ambiguous language is tricky enough, but building models
that can relate language to the surrounding world is even more challenging. For
instance, given the explanation at least two red squares, a model must not
only understand the terms red and square, but also how they refer to
particular parts of (often complex) inputs.
Past work (1,
2,
3) has relied on semantic
parsers which
convert natural language statements (e.g. at least two red squares) to formal
logical representations (e.g. Count(Square AND Red) > 2). If we can easily
check whether explanations apply to our inputs by executing these logical
formulas, we can use our explanations as features to train our model.
However, semantic parsers only work on simple domains
where we can hand-engineer a logical grammar of explanations we might expect to
see. They struggle to handle richer and vaguer language or scale up to more
complex inputs, such as images.
Fortunately, modern deep neural language models such as
BERT are beginning to show promise at
solving many language understanding tasks. Our papers propose to alleviate the
grounding problem by using neural language models that are either trained to
ground language explanations in the domain of interest, or come pre-trained
with general-purpose “knowledge” that can be used to interpret explanations. We
will show that these neural models allow us to learn from richer and more
diverse language for more challenging settings.
Representation Engineering with Natural Language Explanations
In our first paper, we examine how to build text classifiers with language
explanations.
Consider the task of relation extraction, where we are given a
short paragraph and must identify whether two people mentioned in the
paragraph are married. While state-of-the-art NLP models can likely solve
this task from data alone, humans might use language to describe ways to tell
whether two people are married—for example, people who go on honeymoons are
typically married. Can such language explanations be used to train better
classifiers?

In the same way that we might take an input , and extract features (e.g.
the presence of certain words) to train a model, we can use explanations to
provide additional features. For example, knowing that honeymoons are relevant
for this task, if we can create a honeymoon feature that reliably activates
whenever the two people in a paragraph are described as going on a honeymoon,
this should be useful signal for training a better model.
But creating such features requires some sort of explanation interpretation
mechanism that tells us whether an explanation is true for an input. Semantic
parsers are one such tool: given and went on honeymoon, we could
parse this explanation into a logical form which, when run on an input,
produces 1 if the word honeymoon appears between and . But what about
a vaguer explanation like and are in love? How can we parse this?
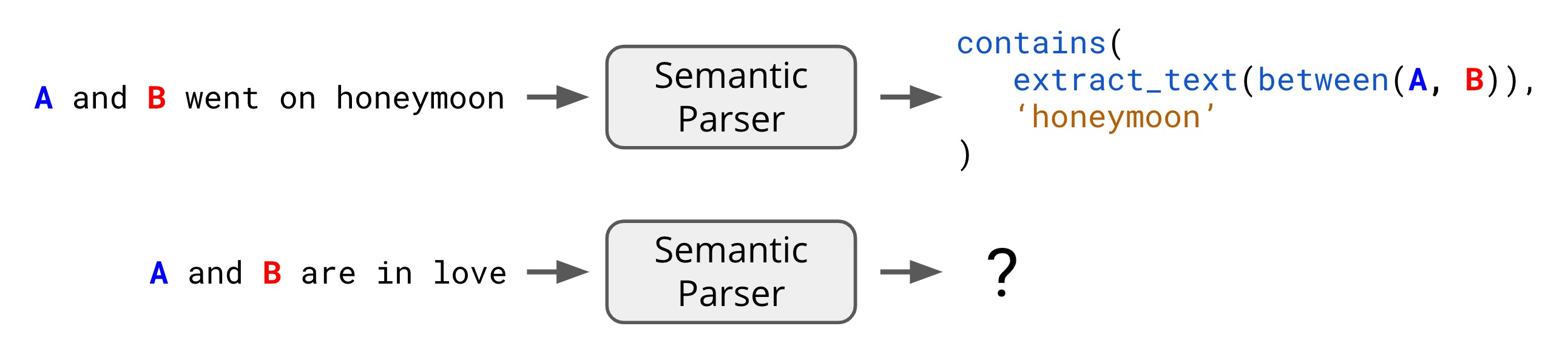
While semantic parsing is efficient and accurate in small domains, it can be
overly brittle, as it can only interpret explanations which adhere to a fixed
set of grammatical rules and functions that we must specify in advance (e.g.
contains and extract_text).
Instead, we turn to the soft reasoning
capabilities of BERT, a neural language model. BERT is particularly effective
at the task of textual entailment: determining whether a sentence implies or
contradicts another sentence (e.g. does She ate pizza imply that She ate
food? Yes!). In our proposed ExpBERT model, we take a BERT model
trained for textual entailment, and instead ask it to identify whether a
paragraph in our task entails an explanation. The features produced by BERT
during this process replace the indicator features produced by the semantic
parser above.
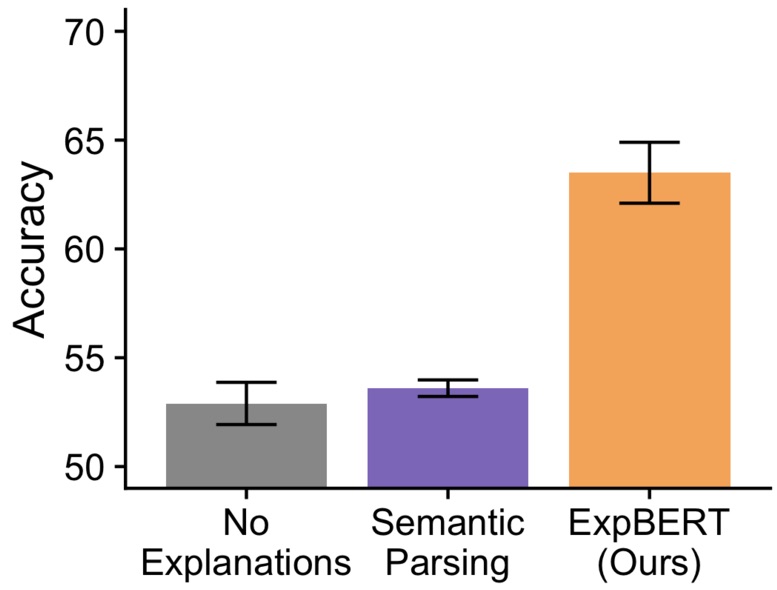
Does the soft reasoning power of BERT improve over semantic parsing? On the
marriage identification task, we find that ExpBERT leads to substantial
improvements over a classifier that is trained on the input features only (No
Explanations). Importantly, using a semantic parser to try to parse
explanations doesn’t help much, since there are general explanations (in
love) that are difficult to convert to logical forms.
In the full paper, we compare to more baselines, explore larger relation
extraction tasks (e.g. TACRED),
conduct ablation studies to understand what kinds of explanations are
important, and examine how much more efficient explanations are compared to
additional data.
Shaping Visual Representations with Language
The work we’ve just described uses natural language explanations for a single
task like marriage identification. However, work in cognitive
science suggests that
language also equips us with the right features and abstractions that help us
solve future tasks.
For example, explanations that indicate whether person is married to
also highlight other concepts that are crucial to human relationships:
children, daughters, honeymoons, and more. Knowing these additional
concepts are not just useful for identifying married people; they are also
important if we would later like to identify other relationships
(e.g. siblings, mother, father).
In machine learning, we might ask: how can language point out the right
features for challenging and underspecified domains, if we
ultimately wish to solve new tasks where no language is available? In our
second paper, we explore this setting,
additionally increasing the challenge by seeing whether language can improve
the learning of representations across modalities—here, vision.
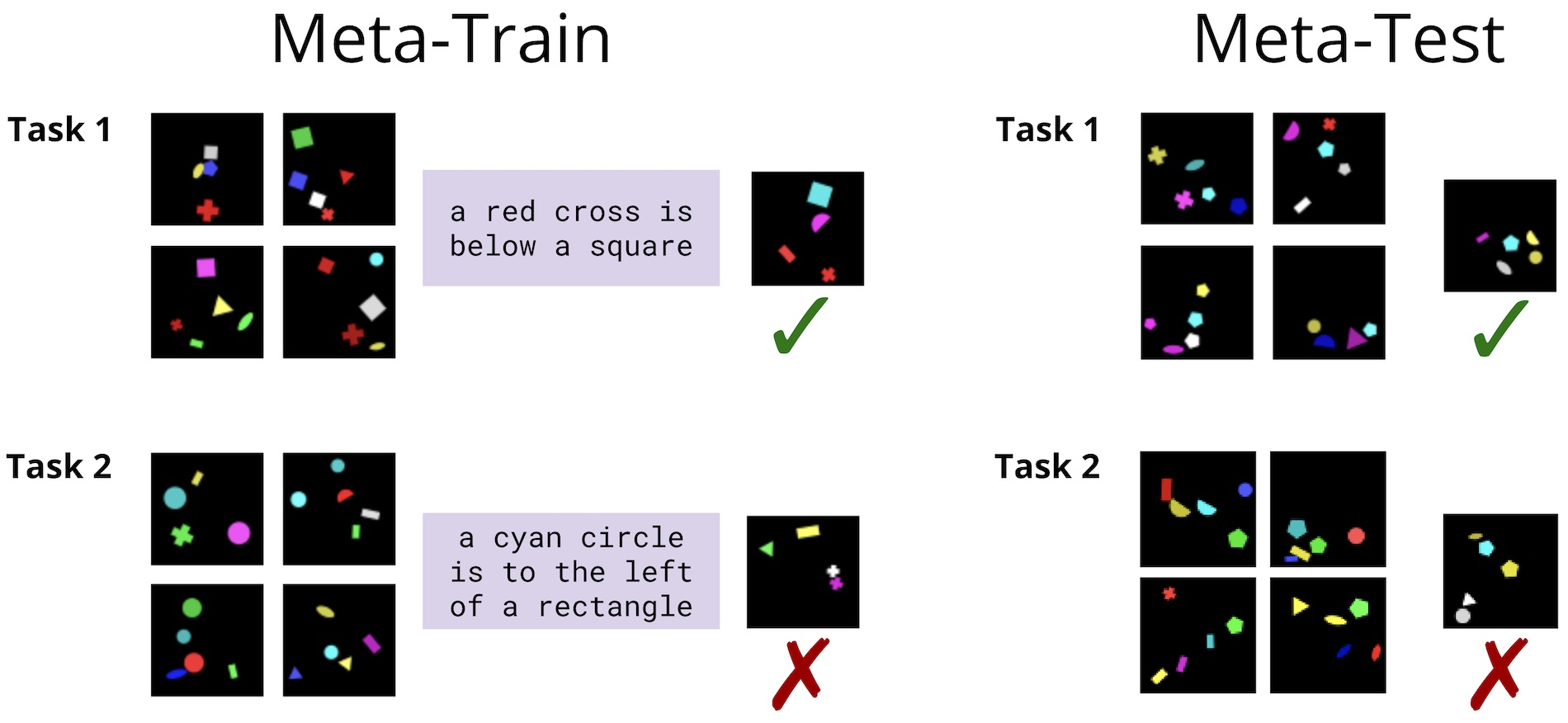
We’re specifically interested in few-shot visual reasoning tasks like the following (here, from the ShapeWorld dataset):
Given a small training set of examples of a visual concept, the task is to
determine whether a held-out test image expresses the same concept. Now, what
if we assume access to language explanations of the relevant visual concepts at
training time? Can we use these to learn a better model, even if no language
is available at test time?
We frame this as a meta-learning task:
instead of training and testing a model on a single task, we
train a model on a set of tasks, each with a small training set and
an accompanying language description (the meta-train set). We then test
generalization to a meta-test set of unseen tasks, for which no language is
available:
First, let’s look at how we might solve this task without language. One typical
approach is Prototype Networks, where we learn some model
(here, a deep convolutional neural network)
that embeds the training images, averages them, and compares to an embedding of
the test image:
To use language, we propose a simple approach called Language Shaped Learning
(LSL): if we have access to explanations at training time, we encourage the
model to learn representations that are not only helpful for classification,
but are predictive of the language explanations. We do this by introducing an
auxiliary training objective (i.e. it is not related to the ultimate task of
interest), where we simultaneously train a recurrent neural network (RNN)
decoder to predict the explanation(s) from the representation of the
input images. Crucially, training this decoder depends on the
parameters of our image model , so this process should encourage
to better encode the features and abstractions exposed in
language.
In effect, we are training the model to “think out loud” when representing
concepts at training time. At test time, we simply discard the RNN decoder, and
do classification as normal with the “language-shaped” image embeddings.
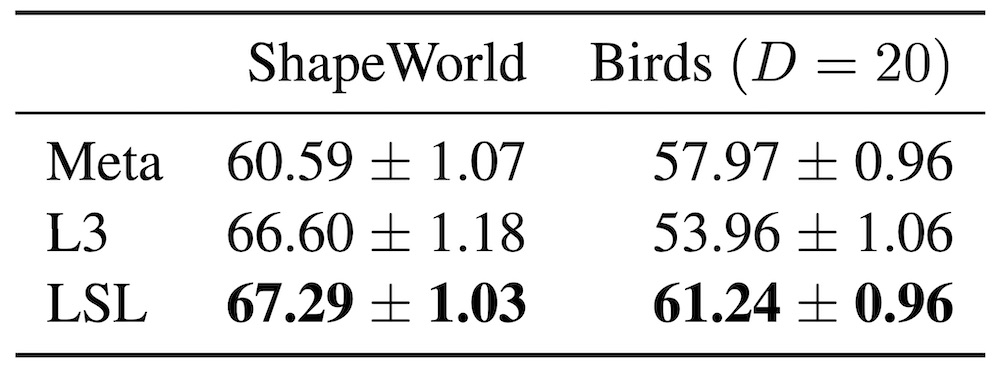
We apply this model to both the ShapeWorld dataset described above, and a more
realistic Birds
dataset, with real images and human language:

In both cases, this auxiliary training objective improves performance over a
no-explanation baseline (Meta), and Learning with Latent
Language (L3), a similar model proposed
for this setting that uses language as a discrete bottleneck (see the paper for
details):
In the full paper, we also explore which parts of language are most important
(spoiler: a little bit of everything), and how much language is needed for
LSL to improve over models that don’t use language (spoiler: surprisingly little!)
Moving Forward
As NLP systems grow in their ability to understand and produce language, so too
grows the potential for machine learning systems to learn from language to
solve other challenging tasks. In the papers above, we’ve shown that deep
neural language models can be used to successfully learn from language
explanations to improve generalization across a variety of tasks in vision and
NLP.
We think this is an exciting new avenue for training machine learning models,
and similar ideas are already being explored in areas such as reinforcement
learning (4,
5). We envision a future where in order to
solve a machine learning task, we no longer have to collect a large labeled
dataset, but instead interact naturally and expressively with a model in the
same way that humans have interacted with each other for millennia—through
language.
Acknowledgments
Thanks to our coauthors (Pang Wei Koh, Percy Liang, and Noah Goodman), and to
Nelson Liu, Pang Wei Koh, and the rest of the SAIL blog team for reviewing and
publishing this blog post. This research was supported in part by the Facebook
Fellowship (to Pang Wei Koh), the NSF Graduate Research Fellowship (to Jesse Mu), Toyota Research
Institute, and the Office of Naval Research.