A guest post by James Bartlett and Zain Asgar of Pixie.
At Pixie, our goal is to enable developers to quickly understand and debug production systems. We achieve this by providing developers easy access to an assortment of metric and log data from their production system. For example, we collect structured information about CPU and memory usage for each process in their system, as well as many types of unstructured data (for example, the body of an HTTP request, or the error message from a program).
These are just two examples, we collect many other types of data, as well. For this blog post, we will focus on the vast amounts of unstructured data we collect in Pixie such as HTTP request/response bodies. We foresee a future where this unstructured machine data can be queried as easily and efficiently as the structured data. To achieve this, we leverage state-of-the-art NLP techniques to learn the structure of the data.
In this article, we’d like to share our experience and efforts here, in the hopes they are useful to inform your thinking on similar problems.
HTTP clustering
Suppose a developer using Pixie wanted to get an idea of which types of HTTP requests are particularly slow. Instead of forcing the developer to sift through many individual HTTP requests by hand, we can instead cluster the HTTP requests semantically and then show them a timeseries of latencies for each type of semantically clustered request. To demonstrate this, let’s walk through the end result and then we’ll come back to how we got to this point. We will use Pixie to explore a demo application called Online Boutique. Once we have Pixie deployed to a kubernetes cluster running Online Boutique, we can start to explore. For example, we can look at a graph of the network connections within the Online Boutique application:
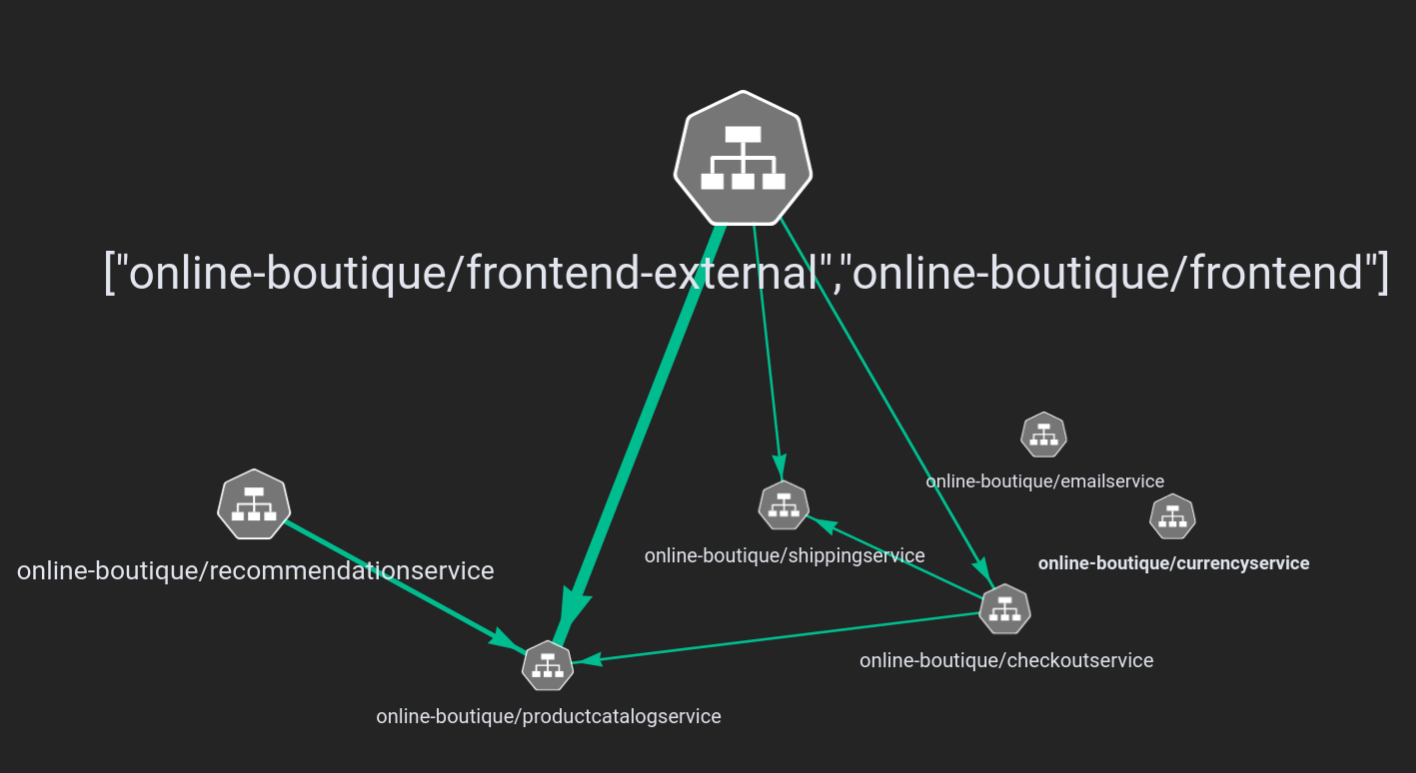
As you can see in the service graph, there’s a frontend service that handles incoming requests and sends them to their respective microservices. So let’s delve into the HTTP requests sent to the frontend service and their corresponding latencies.
|
HTTP Request Body |
Latency (ms) |
|
“product_id=L9ECAV7KIM&quantity=3 |
3.325302 |
|
“email=someone%40example.com&street_address=1600+Amphitheatr… |
102.625462 |
|
“product_id=OLJCESPC7Z&quantity=3” |
3.4530790000000002 |
|
“product_id=L9ECAV7KIM&quantity=5” |
4.828718 |
|
“product_id=0PUK6V6EV0&quantity=2” |
5.319163 |
|
“email=someone%40example.com&street_address=1600+Amphitheatr |
107.361424 |
|
“product_id=0PUK6V6EV0&quantity=4” |
3.81733 |
|
“currency_code=EUR” |
0.203676 |
|
“currency_code=USD” |
0.220932 |
|
“product_id=0PUK6V6EV0&quantity=4” |
4.538055 |
From this small sample of requests, it’s not immediately clear what’s going on. It looks like the requests with `email=…?address=…` are much slower than the others, but we can’t be sure these examples weren’t just outliers. Instead of looking at more data, let’s use our soon-to-be-explained unstructured text clustering techniques, to cluster the HTTP requests semantically by the contents of their bodies.
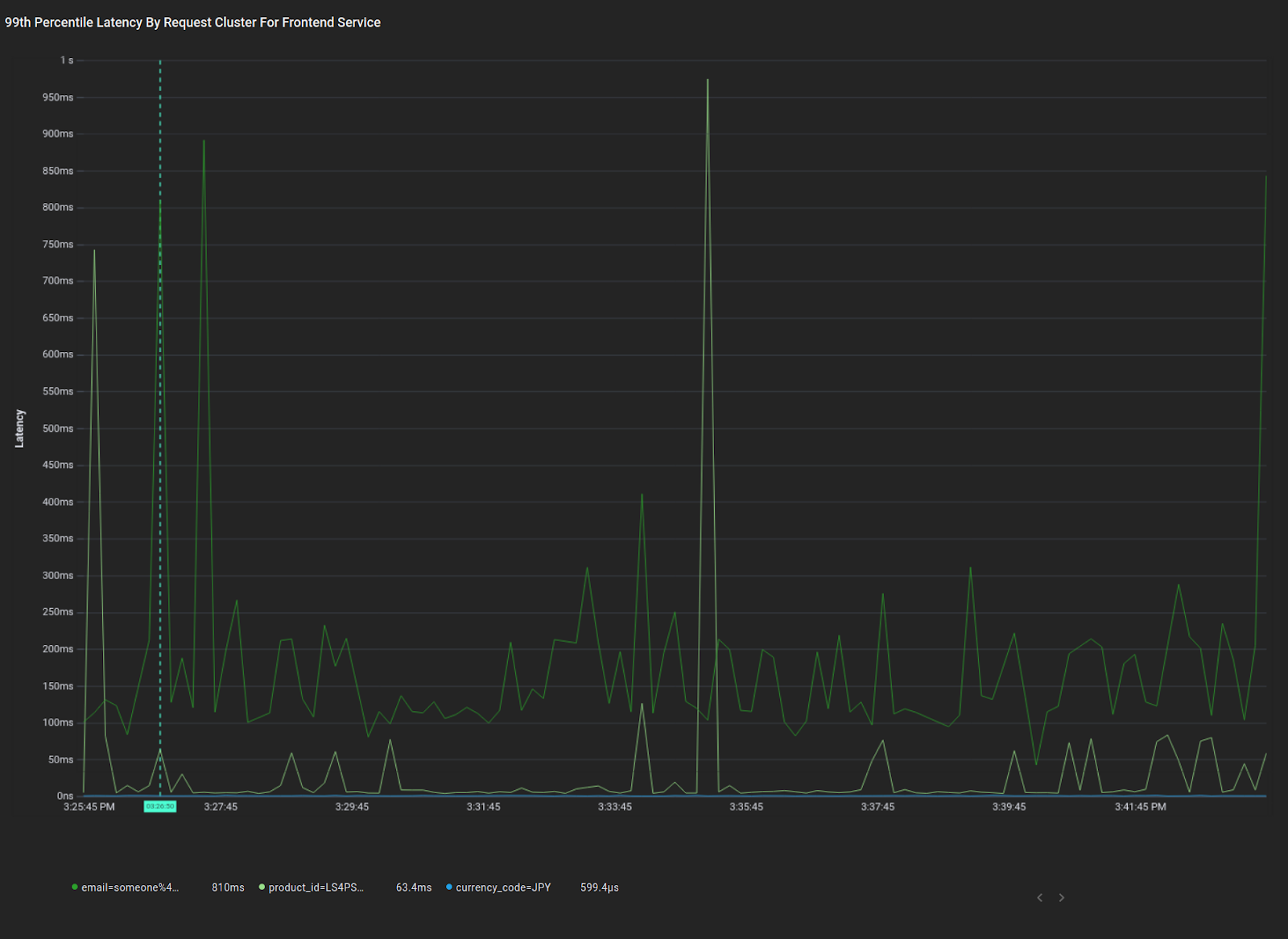
Here you can see a plot of the average 99th percentile response latency for requests for each semantic cluster. Using this view, you can quickly determine the three broad categories of requests coming into the frontend service, as well as the latency profiles of those requests. Immediately, we see that the “email” cluster of requests has significantly higher average p99 latency than the other clusters, and we see that the “product” cluster has occasional latency spikes. Both of these are actionable insights we can debug further. Now let’s dive in and discuss how we got to this point.
Model Development Details
Requirements
Since our models will be deployed on customers’ production clusters, they must be lightweight and performant; ideally fast enough to handle data at line rate with minimal CPU overhead. Any training on customer data must occur on the customer cluster to maintain data isolation guarantees. Furthermore, since the data plane is entirely contained on customer clusters, we have strict storage limitations for data, so we must leverage ML techniques to intelligently sample the data we collect.
Dataset
Due to our stringent data isolation requirements we’re using the loghub dataset to bootstrap our model training. This dataset is a collection of log messages from various contexts (Android sys logs, Apache Server logs, supercomputer/HPC logs, etc). To test the models generalization to unseen log formats, we reserved the Android log data for testing, and trained on the remainder of the log data.
We use Google’s SentencePiece to tokenize the log messages. In particular, we use their implementation of unigram language model based subword tokenization with a vocab size of 16k. The following image shows a word cloud of all 16k vocabulary subword pieces that are generated by our tokenization. The size of the words indicate the frequency in the dataset.
|
| Word cloud showing vocabulary subword pieces from Logpai Loghub machine log dataset tokenization. |
This word cloud provides insight into the biases of our dataset. For example, about 30% of the data is Windows logs, as you can see by the high frequency of the token “windows”, and “microsoft”. Also, if you have a keen eye, you might think we have a lot of frowny faces in our data set, but in fact “):” is almost always preceded by an opening parenthesis, as in the following examples:
[Thu Jan 26 12:23:07 2006] [error] config.update(): Can't create vm
[Fri Jan 27 11:55:16 2006] [error] [client 202.143.128.18] client sent HTTP/1.1 request without hostname (see RFC2616 section 14.23): /Model Architecture
Using this tokenized dataset, we train a self-attention based model using left-to-right next word prediction (à la OpenAI’s GPT models). Left-to-right next word prediction is the task of trying to predict the next token given a sequence of prior context tokens. The left-to-right part distinguishes it from BERT style models that use bidirectional context (we will try bidirectional models in the future). This TensorFlow tutorial demonstrates training of a similar architecture, the only difference being we drop the encoder side of the architecture in the tutorial.
The architecture we use is displayed in the figure below. We have 6 decoder blocks, each with a self-attention layer and a feed-forward layer. Note that, for simplicity, the diagram leaves out the skip connections over the self-attention and feed-forward layers, as well as the layer normalizations that go with those skip connections.
 |
| GPT-style language model architecture |
All in all, this architecture has 6.47M parameters, making it quite small in comparison to state-of-the-art language models. DistillBERT, for instance, has 66M parameters. On the other hand, the largest version of GPT-3 has 175B parameters.
We trained this architecture for 10 epochs with roughly 100 million unique log messages per epoch. After each epoch, we ran the model on a validation set and the model from the epoch with the highest validation accuracy was used as the final model. We achieved a test accuracy of 63.13% for next word prediction on the holdout Android log data. Given that we haven’t yet explored hyperparameter tuning, or other optimizations, this level of accuracy is a promising starting point.
We now have a way to predict future tokens in machine log data from context, with somewhat decent accuracy. However, this doesn’t immediately help us with our original goal of extracting structured features from the data. To further this goal, we will explore the feature space generated by the language model, rather than the predictions of the language model.
The goal is to transform our complicated data space into a fixed-dimensional feature space which we can then use for subsequent tasks. In order to do this we need to transform the outputs of the language model into a fixed-dimensional vector, which we will call the feature vector. One way to do this comes from BERT style models.
With BERT style models the way to extend the pre-trained language model to supervised tasks is to add a fully connected network on the output of the <CLS> (or <s>) token of the sentence, and then fine-tune the model with the fully-connected network on some classification task (this is illustrated in the figure below). This leads to a natural feature vector as the output prior to the softmax layer.
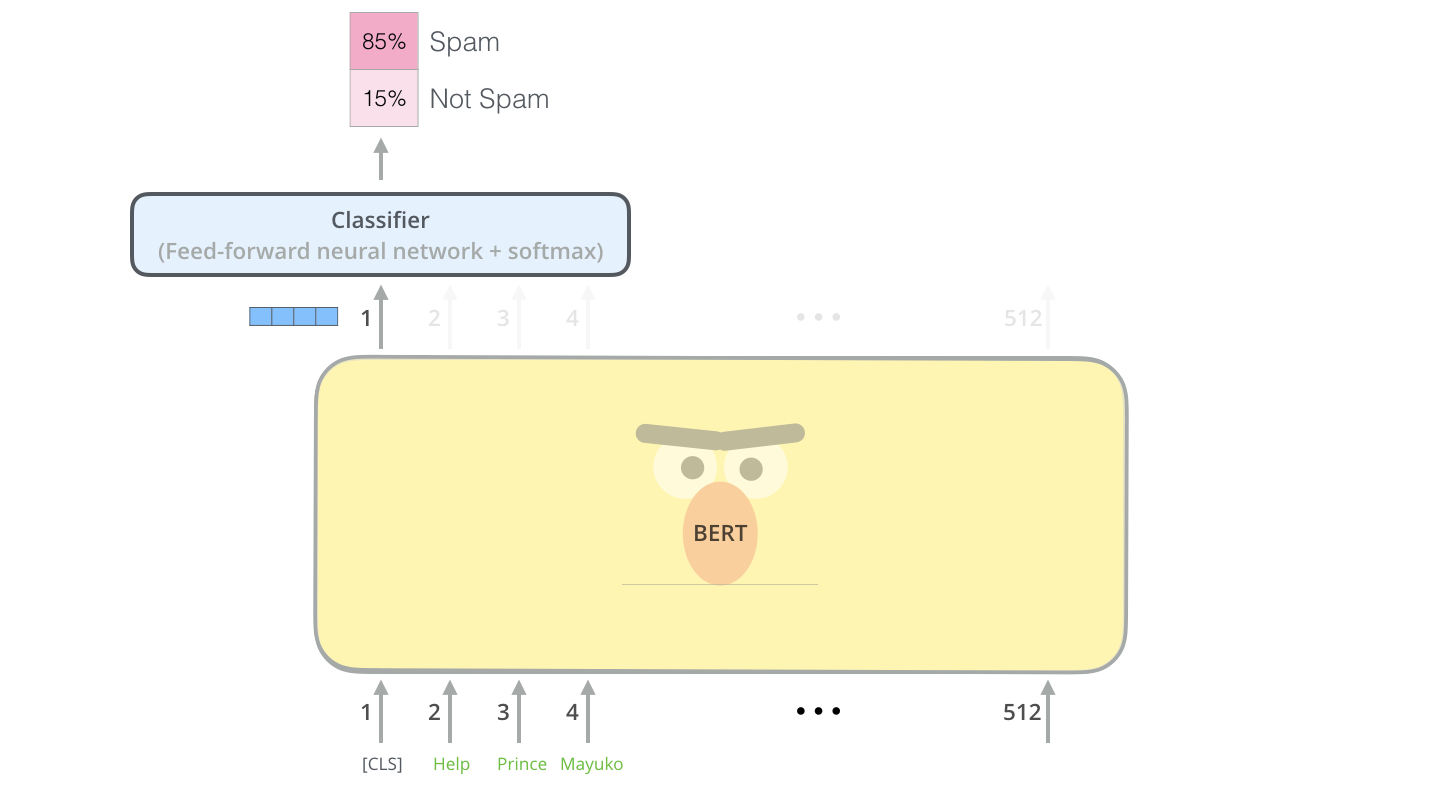 |
| Alammar, J (2018). The Illustrated Transformer [Blog post]. Retrieved from https://jalammar.github.io/illustrated-transformer/ |
We plan to explore this method in the future, however for now we would like to see what results we can get without adding any extra supervision. This requires a heuristic approach to turn our sequence of outputs into a fixed-length vector. One way to do this is to use a max-pooling operator on the sequence dimension of the output. Suppose our language model outputs a sequence of 256-dimensional vectors, then a max-pooling on the sequence dimension will output a single 256-dimensional vector, where each dimension is the maximum value of that dimension across all outputs in the sequence. The idea behind this approach is that neurons that have stronger responses are more important to include in the final representation.
Results
We can test how well this method works for clustering on a subset of the loghub data that I’ve hand labeled into semantic clusters. Below are three of the log messages in the hand labelled test data set. The first two are labelled to be in the same semantic cluster, since both relate to failures to find files, the last is from a different cluster, since it’s an unrelated message about flushing data.
[Wed Nov 09 22:30:05 2005] [error] [client 216.138.114.25] script not found or unable to stat: /var/www/cgi-bin/awstats.p
[Sat Jan 28 19:29:29 2006] [error] [client 211.154.174.50] File does not exist: /var/www/html/modules
20171230-12:25:37:318|Step_StandStepCounter|30002312|flush sensor data
Using the hand-labelled test set, we can measure how well the model separates the different clusters. To do this, we use the KMeans algorithm to generate a clustering based on the output of the model, and then compare this clustering to the hand-labelled clustering. On this test set, the model’s adjusted rand score, a metric where 0.0 is random labelling and 1.0 is perfect labelling, was 0.53. As with next word prediction accuracy, the performance isn’t great but a good starting point.
We can also view a low-dimensional representation of the feature space for the model, using PCA to reduce the dimensionality to two. The figures below show the first two PCA dimensions of the embeddings for each point in the test data set. The colors represent the semantic cluster the point belongs to. Note that since these are plots in a two-dimensional subspace of the embedding space, the absolute position of points carries little meaning, more meaning is derived from the tightness of each of the clusters. In the figure below, we can see that the model separates some of the classes reasonably well, but fails on others.
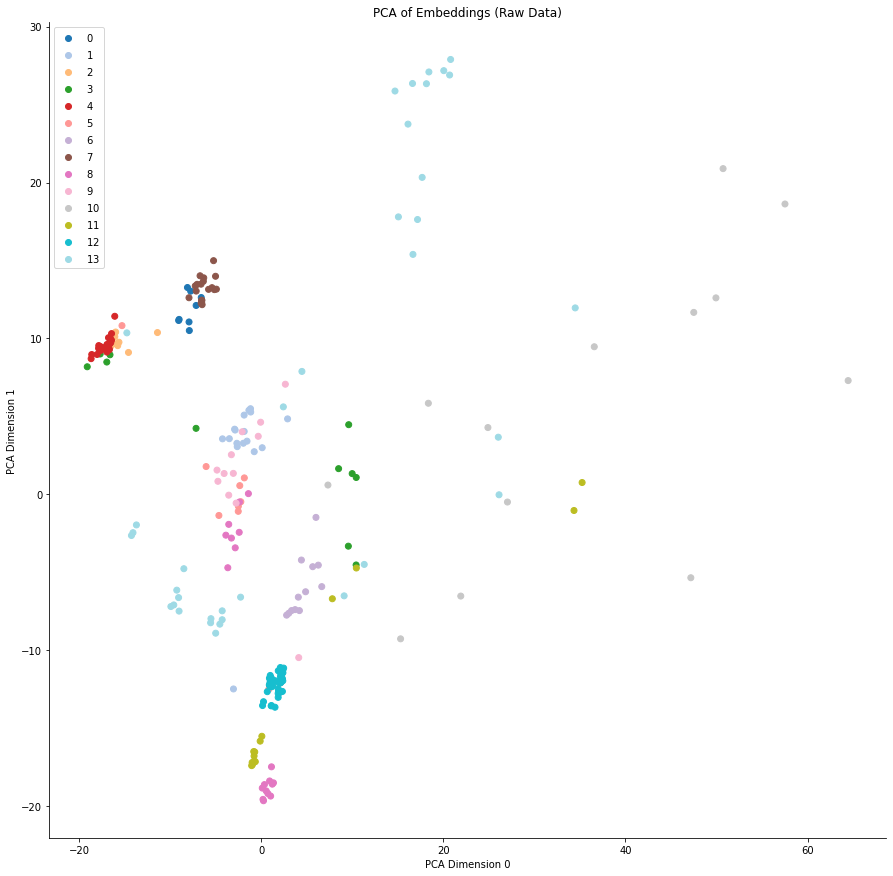 |
| 2-dimensional representation of the feature space of the model. |
Using this method, we should be able to cluster unstructured data in Pixie, and tag it with its semantic cluster ID, hence extracting a structured feature from our unstructured data. This particular feature is, as yet, not very human-interpretable, but we will get to that later.
Inference
So let’s try to implement this method within the Pixie system. In order to do that we first need to convert our model into TensorFlow Lite and then load it into the Pixie execution engine. We decided to use TensorFlow Lite because we need to minimize overhead as much as possible, and in the future we would like the flexibility to deploy to heterogeneous edge devices including Raspberry PI’s and ARM microcontrollers.
Converting to TensorFlow Lite is pretty simple. We create a TF function for our model and call the builtin converter to generate a tensorflow lite model protobuf file:
model = tf.keras.models.load_model(model_path)
@tf.function(input_signature=[tf.TensorSpec([1, max_length], dtype=tf.int32)
def pred_fn(encoded_text):
# Create a mask that masks out 0 tokens, and future tokens for next word prediction.
mask = create_padded_lookahead_mask(max_length)
# Our saved model outputs both its next word predictions, and the activations of its final layer. We only use the activations of the final layer for clustering purposes.
model_preds, last_layer_output = model([encoded_text, mask], training=False)
# Max pool over the seq dimension.
return tf.reduce_max(last_layer_output, axis=1)
converter = tf.lite.TFLiteConverter.from_concrete_functions([fn.get_concrete_function()])
tflite_model = converter.convert()Pixie’s query engine allows querying and manipulating data collected by Pixie. This engine already has a KMeans operator, so all we need to do is load our tflite model into the engine, and then write a custom PxL script (a script in Pixie’s scripting language based on Python/Pandas) to cluster our data. We are working on a public API to load in custom ML models into the engine, but for now we will use some internal features to do that. Once the model is loaded in, we can use it on any unstructured data in the Pixie Platform.
Some of the areas we are currently exploring include our vision of federated differentially-private training of models, bidirectional language models ala BERT, compression schemes for unstructured data based on learned structural representations of the data, and anomaly detection on unstructured data
Our goal on the Pixie ML team is to harness ML to simplify developers’ access to monitoring data, while operating in heterogeneous edge environments. If any of this interests you, or you have other questions feel free to join our slack group.
Pixie is an open-source project that gives you instant visibility into your application. It provides access to metrics, events, traces and logs without changing code. Pixie is in the process of being contributed to the CNCF (Cloud Native Compute Foundation). Pixie was originally created at Pixie Labs, Inc., but contributed to open source by New Relic, Inc.
James is a software engineer at the New Relic on the Pixie Team. He was a founding engineer at Pixie Labs.
Zain is the GM/GVP of Pixie and Open Source at New Relic. He is also an Adjunct Professor of Computer Science at Stanford University. He was the Co-founder/CEO of Pixie Labs.