
Posted by Jonathan Dekhtiar (NVIDIA), Bixia Zheng (Google), Shashank Verma (NVIDIA), Chetan Tekur (NVIDIA)
TensorFlow-TensorRT (TF-TRT) is an integration of TensorFlow and TensorRT that leverages inference optimization on NVIDIA GPUs within the TensorFlow ecosystem. It provides a simple API that delivers substantial performance gains on NVIDIA GPUs with minimal effort. The integration allows for leveraging of the optimizations that are possible in TensorRT while providing a fallback to native TensorFlow when it encounters segments of the model that are not supported by TensorRT.
In our previous blog on TF-TRT integration, we covered the workflow for TensorFlow 1.13 and earlier releases. This blog will introduce TensorRT integration in TensorFlow 2.x, and demonstrate a sample workflow with the latest API. Even if you are new to this integration, this blog contains all the information you need to get started. Using the TensorRT integration has shown to improve performance by 2.4X compared to native TensorFlow inference on Nvidia T4 GPUs.
TF-TRT Integration
When TF-TRT is enabled, in the first step, the trained model is parsed in order to partition the graph into TensorRT-supported subgraphs and unsupported subgraphs. Then each TensorRT-supported subgraph is wrapped in a single special TensorFlow operation (TRTEngineOp). In the second step, for each TRTEngineOp node, an optimized TensorRT engine is built. The TensorRT-unsupported subgraphs remain untouched and are handled by the TensorFlow runtime. This is illustrated in Figure 1.
TF-TRT allows for leveraging TensorFlow’s flexibility while also taking advantage of the optimizations that can be applied to the TensorRT supported subgraphs. Only portions of the graph are optimized and executed with TensorRT, and TensorFlow executes the remaining graph.
In the inference example shown in Figure 1, TensorFlow executes the Reshape Op and the Cast Op. Then TensorFlow passes the execution of the TRTEngineOp_0, the pre-built TensorRT engine, to TensorRT runtime.
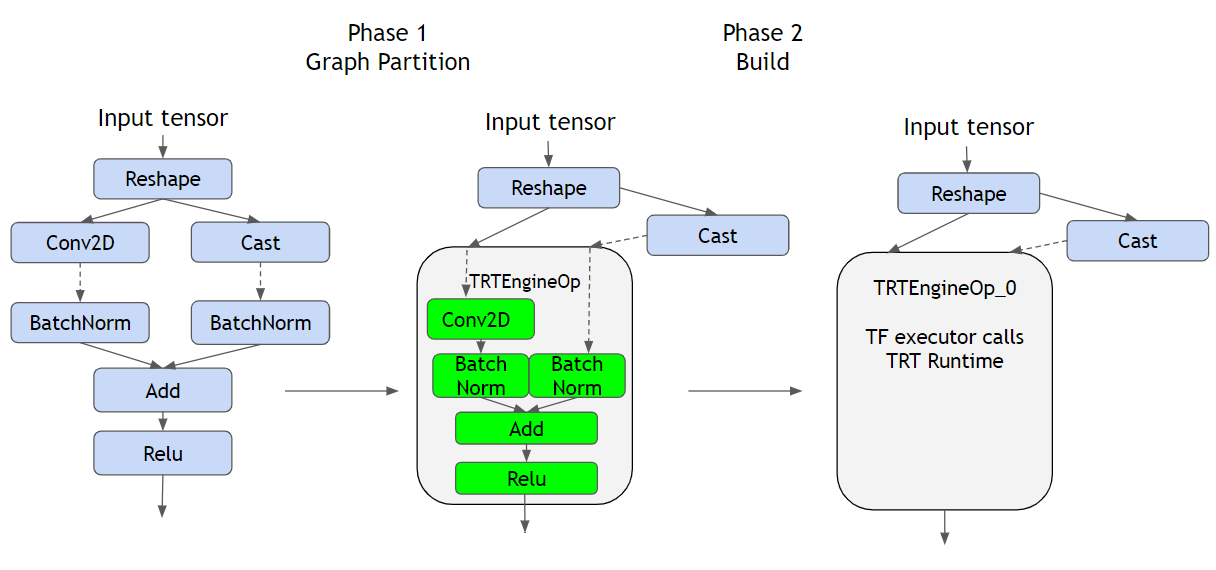 |
| Figure 1: An example of graph partitioning and building TRT engine in TF-TRT |
Workflow
In this section, we will take a look at the typical TF-TRT workflow using an example.
 |
| Figure 2: Workflow diagram when performing inference in TensorFlow only, and in TensorFlow-TensorRT using a converted SavedModel |
Figure 2 shows a standard inference workflow in native TensorFlow and contrasts it with the TF-TRT workflow. The SavedModel format contains all the information required to share or deploy a trained model. In native TensorFlow, the workflow typically involves loading the saved model and running inference using TensorFlow runtime. In TF-TRT, there are a few additional steps involved, including applying TensorRT optimizations to the TensorRT supported subgraphs of the model, and optionally pre-building the TensorRT engines.
First, we create an object to hold the conversion parameters, including a precision mode. The precision mode is used to indicate the minimum precision (for example FP32, FP16 or INT8) that TF-TRT can use to implement the TensorFlow operations. Then we create a converter object which takes the conversion parameters and input from a saved model. Note that in TensorFlow 2.x, TF-TRT only supports models saved in the TensorFlow SavedModel format.
Next, when we call the converter convert() method, TF-TRT will convert the graph by replacing TensorRT compatible portions of the graph with TRTEngineOps. For better performance at runtime, the converter build() method can be used for creating the TensorRT execution engine ahead of time. The build() method requires the input data shapes to be known before the optimized TensorRT execution engines are built. If input data shapes are not known then TensorRT execution engine can be built at runtime when the input data is available. The TensorRT execution engine should be built on a GPU of the same device type as the one on which inference will be executed as the building process is GPU specific. For example, an execution engine built for a Nvidia A100 GPU will not work on a Nvidia T4 GPU.
Finally, the TF-TRT converted model can be saved to disk by calling the save method. The code corresponding to the workflow steps mentioned in this section are shown in the codeblock below:
from tensorflow.python.compiler.tensorrt import trt_convert as trt
# Conversion Parameters
conversion_params = trt.TrtConversionParams(
precision_mode=trt.TrtPrecisionMode.<FP32 or FP16>)
converter = trt.TrtGraphConverterV2(
input_saved_model_dir=input_saved_model_dir,
conversion_params=conversion_params)
# Converter method used to partition and optimize TensorRT compatible segments
converter.convert()
# Optionally, build TensorRT engines before deployment to save time at runtime
# Note that this is GPU specific, and as a rule of thumb, we recommend building at runtime
converter.build(input_fn=my_input_fn)
# Save the model to the disk
converter.save(output_saved_model_dir)As can be seen from the code example above, the build() method requires an input function corresponding to the shape of the input data. An example of an input function is shown below:
# input_fn: a generator function that yields input data as a list or tuple,
# which will be used to execute the converted signature to generate TensorRT
# engines. Example:
def my_input_fn():
# Let's assume a network with 2 input tensors. We generate 3 sets
# of dummy input data:
input_shapes = [[(1, 16), (2, 16)], # min and max range for 1st input list
[(2, 32), (4, 32)], # min and max range for 2nd list of two tensors
[(4, 32), (8, 32)]] # 3rd input list
for shapes in input_shapes:
# return a list of input tensors
yield [np.zeros(x).astype(np.float32) for x in shapes]Support for INT8
Compared to FP32 and FP16, INT8 requires additional calibration data to determine the best quantization thresholds. When the precision mode in the conversion parameter is INT8, we need to provide an input function to the convert() method call. This input function is similar to the input function provided to the build() method. In addition, the calibration data generated by the input function passed to the convert() method should generate data that are statistically similar to the actual data seen during inference.
from tensorflow.python.compiler.tensorrt import trt_convert as trt
conversion_params = trt.TrtConversionParams(
precision_mode=trt.TrtPrecisionMode.INT8)
converter = trt.TrtGraphConverterV2(
input_saved_model_dir=input_saved_model_dir,
conversion_params=conversion_params)
# requires some data for calibration
converter.convert(calibration_input_fn=my_input_fn)
# Optionally build TensorRT engines before deployment.
# Note that this is GPU specific, and as a rule of thumb we recommend building at runtime
converter.build(input_fn=my_input_fn)
converter.save(output_saved_model_dir)Example: ResNet-50
The rest of this blog will show the workflow of taking a TensorFlow 2.x ResNet-50 model, training it, saving it, optimizing it with TF-TRT and finally deploying it for inference. We will also compare inference throughputs using TensorFlow native vs TF-TRT in three precision modes, FP32, FP16, and INT8.
Prerequisites for the example :
- Ubuntu OS
- Docker: https://docs.docker.com/get-docker/
- The latest available TensorFlow 2.x Container:
- docker pull tensorflow/tensorflow:latest-gpu
- NVIDIA Container Toolkit: https://github.com/NVIDIA/NVIDIA-docker. This allows you to use NVIDIA GPUs in a docker container.
- NVIDIA Driver >= 450 installed on the host machine (at the time of writing, check the requirements of the latest tensorflow container). You can check which version is currently installed on your machine by running: nvidia-smi | grep “Driver Version:”
Training ResNet-50 using the TensorFlow 2.x container:
First, the latest release of the ResNet-50 model needs to be downloaded from the TensorFlow github repository:
# Adding the git remote and fetch the existing branches
$ git clone --depth 1 https://github.com/tensorflow/models.git .
# List the files and directories present in our working directory
$ ls -al
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:05 2020 ./
rwxrwxr-x user user 4 KiB Wed Sep 30 15:30:45 2020 ../
rw-rw-r-- user user 337 B Wed Sep 30 15:31:05 2020 AUTHORS
rw-rw-r-- user user 1015 B Wed Sep 30 15:31:05 2020 CODEOWNERS
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:05 2020 community/
rw-rw-r-- user user 390 B Wed Sep 30 15:31:05 2020 CONTRIBUTING.md
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:15 2020 .git/
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:05 2020 .github/
rw-rw-r-- user user 1 KiB Wed Sep 30 15:31:05 2020 .gitignore
rw-rw-r-- user user 1 KiB Wed Sep 30 15:31:05 2020 ISSUES.md
rw-rw-r-- user user 11 KiB Wed Sep 30 15:31:05 2020 LICENSE
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:05 2020 official/
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:05 2020 orbit/
rw-rw-r-- user user 3 KiB Wed Sep 30 15:31:05 2020 README.md
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:06 2020 research/As noted in the earlier section, for this example we will be using the latest TensorFlow container available in the Docker repository. The user does not need any additional installation steps as TensorRT integration is already included in the container. The steps to pull the container and launch it are as follows:
$ docker pull tensorflow/tensorflow:latest-gpu
# Please ensure that the Nvidia Container Toolkit is installed before running the following command
$ docker run -it --rm
--gpus="all"
--shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864
--workdir /workspace/
-v "$(pwd):/workspace/"
-v "</path/to/save/data/>:/data/" # This is the path that will hold the training data
tensorflow/tensorflow:latest-gpuFrom inside the container, we can then verify that we have access to the relevant files and the Nvidia GPU we would like to target:
# Let's first test that we can access the ResNet-50 code that we previously downloaded
$ ls -al
drwxrwxr-x 8 1000 1000 4096 Sep 30 22:31 .git
drwxrwxr-x 3 1000 1000 4096 Sep 30 22:31 .github
-rw-rw-r-- 1 1000 1000 1104 Sep 30 22:31 .gitignore
-rw-rw-r-- 1 1000 1000 337 Sep 30 22:31 AUTHORS
-rw-rw-r-- 1 1000 1000 1015 Sep 30 22:31 CODEOWNERS
-rw-rw-r-- 1 1000 1000 390 Sep 30 22:31 CONTRIBUTING.md
-rw-rw-r-- 1 1000 1000 1115 Sep 30 22:31 ISSUES.md
-rw-rw-r-- 1 1000 1000 11405 Sep 30 22:31 LICENSE
-rw-rw-r-- 1 1000 1000 3668 Sep 30 22:31 README.md
drwxrwxr-x 2 1000 1000 4096 Sep 30 22:31 community
drwxrwxr-x 12 1000 1000 4096 Sep 30 22:31 official
drwxrwxr-x 3 1000 1000 4096 Sep 30 22:31 orbit
drwxrwxr-x 23 1000 1000 4096 Sep 30 22:31 research
# Let's verify we can see our GPUs:
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.XX.XX Driver Version: 450.XX.XX CUDA Version: 11.X |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:1A:00.0 Off | Off |
| 38% 52C P8 14W / 70W | 1MiB / 16127MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
We can now start training ResNet-50. To avoid spending hours training a deep learning model, this article will use the smaller MNIST dataset. However, the workflow will not change with a more state-of-the-art dataset like ImageNet.
# Install dependencies
$ pip install tensorflow_datasets tensorflow_model_optimization
# Download MNIST data and Train
$ python -m "official.vision.image_classification.mnist_main"
--model_dir=./checkpoints
--data_dir=/data
--train_epochs=10
--distribution_strategy=one_device
--num_gpus=1
--download
# Let’s verify that we have the trained model saved on our machine.
$ ls -al checkpoints/
-rw-r--r-- 1 root root 87 Sep 30 22:34 checkpoint
-rw-r--r-- 1 root root 6574829 Sep 30 22:34 model.ckpt-0001.data-00000-of-00001
-rw-r--r-- 1 root root 819 Sep 30 22:34 model.ckpt-0001.index
[...]
-rw-r--r-- 1 root root 6574829 Sep 30 22:34 model.ckpt-0010.data-00000-of-00001
-rw-r--r-- 1 root root 819 Sep 30 22:34 model.ckpt-0010.index
drwxr-xr-x 4 root root 4096 Sep 30 22:34 saved_model
drwxr-xr-x 3 root root 4096 Sep 30 22:34 train
drwxr-xr-x 2 root root 4096 Sep 30 22:34 validationObtaining a SavedModel to be used by TF-TRT
After training, Google’s ResNet-50 code exports the model in the SavedModel format at the following path: checkpoints/saved_model/.
The following sample code can be used as a reference in order to export your own trained model as a TensorFlow SavedModel.
import numpy as np
import tensorflow as tf
from tensorflow import keras
def get_model():
# Create a simple model.
inputs = keras.Input(shape=(32,))
outputs = keras.layers.Dense(1)(inputs)
model = keras.Model(inputs, outputs)
model.compile(optimizer="adam", loss="mean_squared_error")
return model
model = get_model()
# Train the model.
test_input = np.random.random((128, 32))
test_target = np.random.random((128, 1))
model.fit(test_input, test_target)
# Calling `save('my_model')` creates a SavedModel folder `my_model`.
model.save("my_model")We can verify that the SavedModel generated by Google’s ResNet-50 script is readable and correct:
$ ls -al checkpoints/saved_model
drwxr-xr-x 2 root root 4096 Sep 30 22:49 assets
-rw-r--r-- 1 root root 118217 Sep 30 22:49 saved_model.pb
drwxr-xr-x 2 root root 4096 Sep 30 22:49 variables
$ saved_model_cli show --dir checkpoints/saved_model/ --tag_set serve --signature_def serving_default
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
The given SavedModel SignatureDef contains the following input(s):
inputs['input_1'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 28, 28, 1)
name: serving_default_input_1:0
The given SavedModel SignatureDef contains the following output(s):
outputs['dense_1'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 10)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predictNow that we have verified that our SavedModel has been properly saved, we can proceed with loading it with TF-TRT for inference.
Inference
ResNet-50 Inference using TF-TRT
In this section, we will go over the steps for deploying the saved ResNet-50 model on the NVIDIA GPU using TF-TRT. As previously described, we first convert a SavedModel into a TF-TRT model using the convert method and then load the model.
# Convert the SavedModel
converter = trt.TrtGraphConverterV2(input_saved_model_dir=path)
converter.convert()
# Save the converted model
converter.save(converted_model_path)
# Load converted model and infer
model = tf.saved_model.load(converted_model_path)
func = root.signatures['serving_default']
output = func(input_tensor)For simplicity, we will use a script to perform inference (tf2_inference.py). We will download the script from github.com and put it in the working directory “/workspace/” of the same docker container as before. After this, we can execute the script:
$ wget https://raw.githubusercontent.com/tensorflow/tensorrt/master/tftrt/blog_posts/Leveraging%20TensorFlow-TensorRT%20integration%20for%20Low%20latency%20Inference/tf2_inference.py
$ ls
AUTHORS CONTRIBUTING.md LICENSE checkpoints data orbit tf2_inference.py
CODEOWNERS ISSUES.md README.md community official research
$ python tf2_inference.py --use_tftrt_model --precision fp16
=========================================
Inference using: TF-TRT …
Batch size: 512
Precision: fp16
=========================================
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
TrtConversionParams(rewriter_config_template=None, max_workspace_size_bytes=8589934592, precision_mode='FP16', minimum_segment_size=3, is_dynamic_op=True, maximum_cached_engines=100, use_calibration=True, max_batch_size=512, allow_build_at_runtime=True)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Processing step: 0100 ...
Processing step: 0200 ...
[...]
Processing step: 9900 ...
Processing step: 10000 ...
Average step time: 2.1 msec
Average throughput: 244248 samples/secSimilarly, we can run inference for INT8, and FP32
$ python tf2_inference.py --use_tftrt_model --precision int8
$ python tf2_inference.py --use_tftrt_model --precision fp32Inference using native TensorFlow (GPU) FP32
You can also run the unmodified SavedModel without any TF-TRT acceleration.
$ python tf2_inference.py --use_native_tensorflow
=========================================
Inference using: Native TensorFlow …
Batch size: 512
=========================================
Processing step: 0100 ...
Processing step: 0200 ...
[...]
Processing step: 9900 ...
Processing step: 10000 ...
Average step time: 4.1 msec
Average throughput: 126328 samples/secThis run was executed with a NVIDIA T4 GPU. The same workflow will work on any NVIDIA GPU.
Comparing Native Tensorflow 2.x performance vs TF-TRT for Inference
Making minimal code changes to take advantage of TF-TRT can result in a significant performance boost. For example, using the inference script in this blog, with a batch-size of 512 on an NVIDIA T4 GPU, we observe almost 2x speedup with TF-TRT FP16, and a 2.4x speedup with TF-TRT INT8 over native TensorFlow. The amount of speedup obtained may differ depending on various factors like the model used, the batch size, the size and format of images in the dataset, and any CPU bottlenecks.
In conclusion, in this blog we show the acceleration provided by TF-TRT. Additionally, with TF-TRT we can use the full TensorFlow Python API and interactive environments like Jupyter Notebooks or Google Colab.
Supported Operators
The TF-TRT user guide lists operators that are supported in TensorRT-compatible subgraphs. Operators outside this list will be executed by the native TensorFlow runtime.
We encourage you to try it yourself and if you encounter problems, please open an issue here.