Sound, smell, taste, touch, and vision – these are the five senses that humans use to perceive and understand the world. We are able to seamlessly combine these different senses when perceiving the world. For example, watching a movie requires constant processing of both visual and auditory information, and we do that effortlessly. As roboticists, we are particularly interested in studying how humans combine our sense of touch and our sense of sight. Vision and touch are especially important when doing manipulation tasks that require contact with the environment, such as closing a water bottle or inserting a dollar bill into a vending machine.
Let’s take closing a water bottle as an example. With our eyes, we can observe the colors, edges, and shapes in the scene, from which we can infer task-relevant information, such as the poses and geometry of the water bottle and the cap. Meanwhile, our sense of touch tells us texture, pressure, and force, which also give us task-relevant information such as the force we are applying to the water bottle and the slippage of the bottle cap in our grasp. Furthermore, humans can infer the same kind of information using either or both types of senses: our tactile senses can also give us pose and geometric information, while our visual senses can predict when we are going to make contact with the environment.
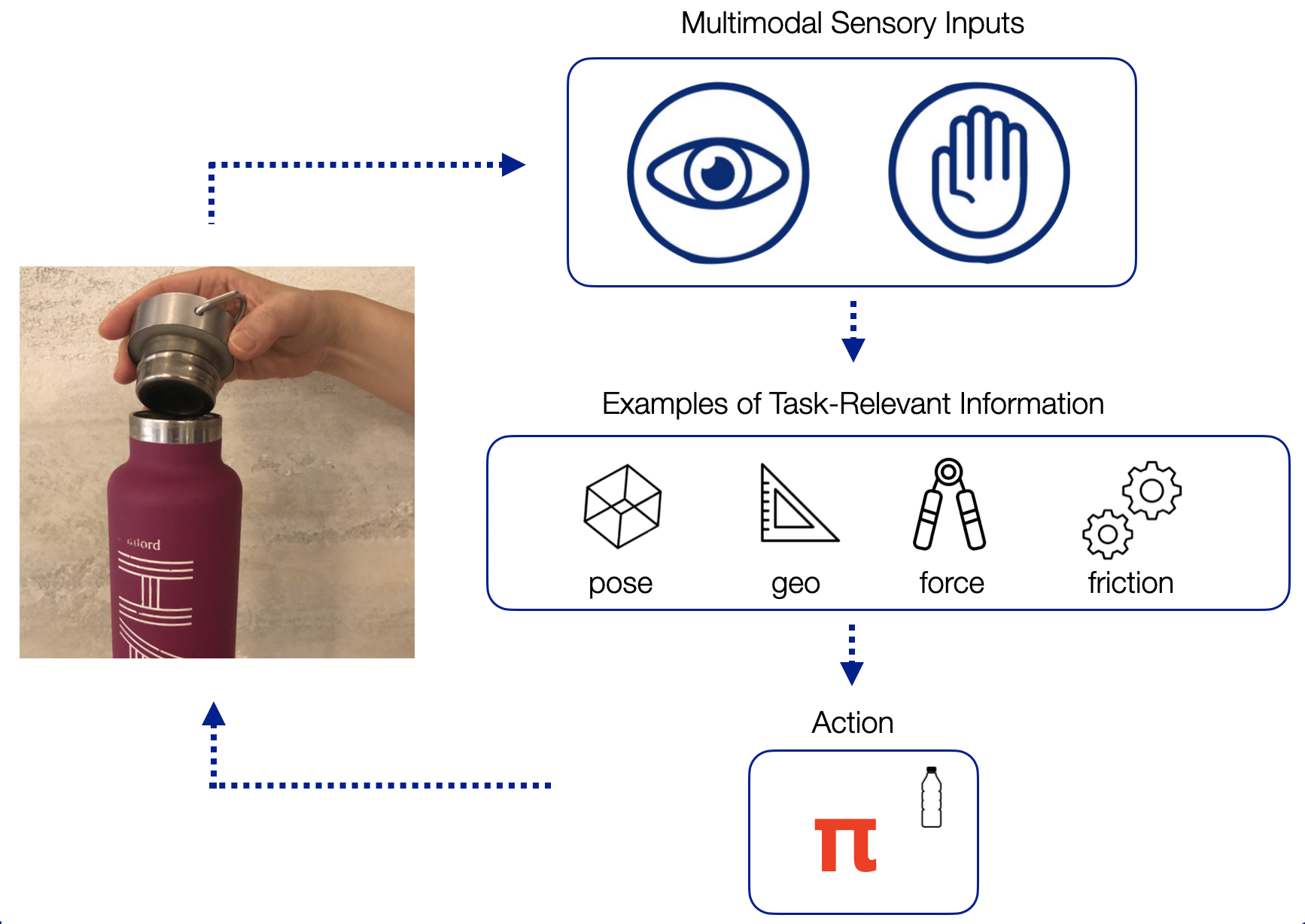
From these multimodal observations and task-relevant features, we come up with appropriate actions for the given observations to successfully close the water bottle. Given a new task, such as inserting a dollar into a vending machine, we might use the same task-relevant information (poses, geometry, forces, etc) to learn a new policy. In other words, there are certain task-relevant multimodal features that generalize across different types of tasks.
Learning features from raw observation inputs (such as RGB images and force/torque data from sensors commonly seen on modern robots) is also known as representation learning. We want to learn a representation for vision and touch, and preferably a representation that can combine the two senses together. We hypothesize that if we can learn a representation that captures task-relevant features, we can use the same representation for similar contact-rich tasks. In other words, learning a rich multimodal representation can help us generalize.
While humans interact with the world in an inherently multimodal manner, it is not clear how to combine very different kinds of data directly from sensors. RGB images from cameras are very high dimensional (often around 640 x 480 x 3 pixels). On the other hand, force/torque sensor readings only have 6 dimensions but also have the complicating quality of sometimes rapidly changing (e.g. when the robot is not touching anything, the sensor registers 0 newtons, but that can quickly jump to 20 newtons once contact is made).
Combining Vision and Touch
How do we combine vision and touch when they have such different characteristics?
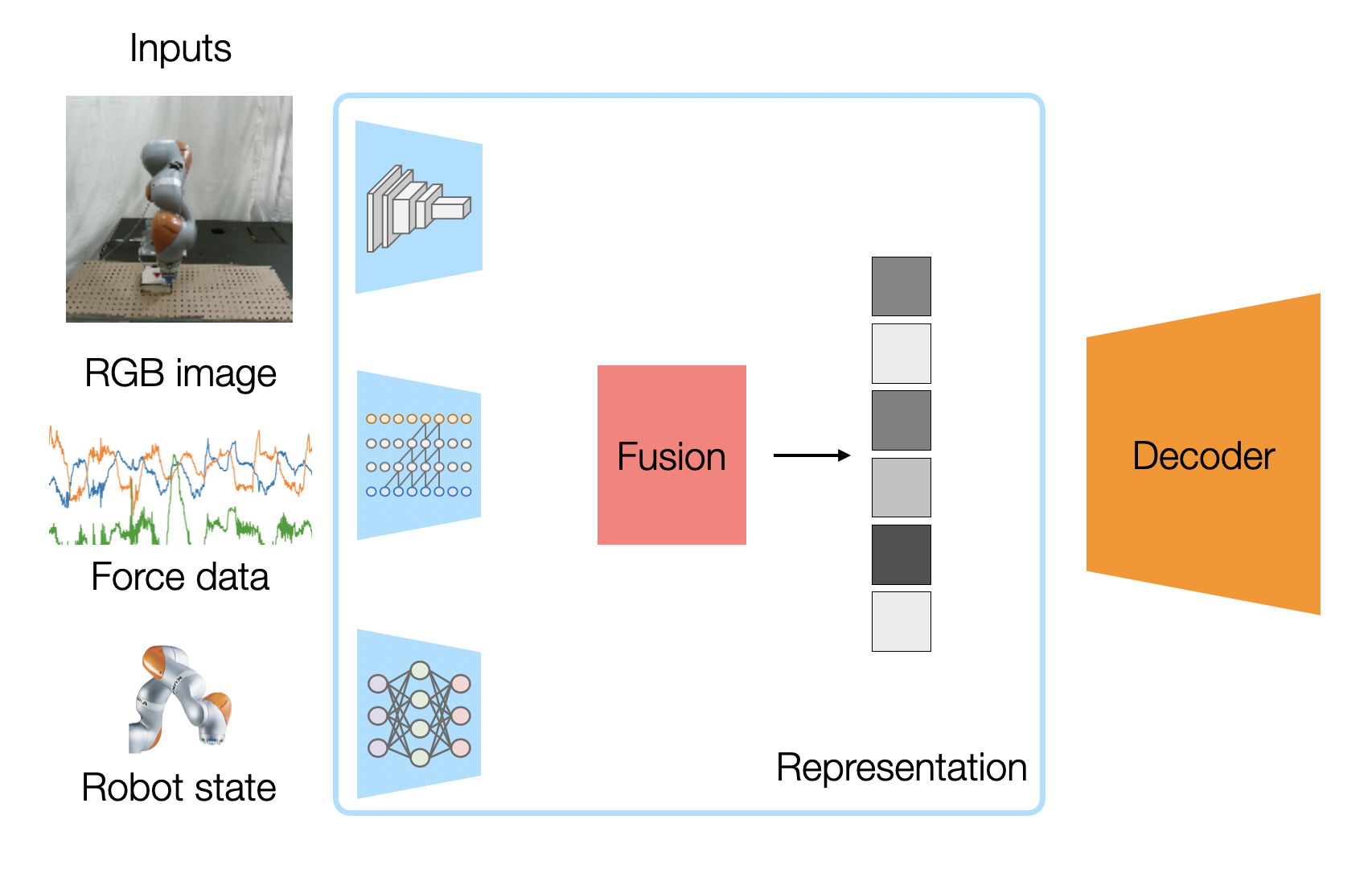
We can leverage a deep neural network to learn features from our high dimensional raw sensor data. The above figure shows our multimodal representation learning neural network architecture, which we train to create a fused vector representation of RGB images, force sensor readings (from a wrist-attached force/torque sensor), and robot states (the position and velocity of the robot wrist from which the peg is attached).
Because our sensor readings have such different characteristics, we use a different network architecture to encode each modality:
-The image encoder is a simplified FlowNet1 network, with a 6-layer convolutional neural network (CNN). This will be helpful for our self-supervised objective.
-Because our force reading is a time series data with temporal correlation, we take the causal convolutions of our force readings. This is similar to the architecture of WaveNet2, which has been shown to work well with time-sequenced audio data.
-For proprioceptive sensor readings (end-effector position and velocity), we encode it with fully connected layers, as this is commonly done in robotics.
Each encoder produces a feature vector. If we want a deterministic representation, we can combine them into one vector by just concatenating them together. If we use a probabilistic representation, where each feature vector actually has a mean vector and a variance vector (assuming Gaussian distributions), we can combine the different modality distributions using the Product of Experts idea of multiplying the densities of the distributions together by weighting each mean with its variance. The resulting combined vector is our multimodal representation.
How do we learn multimodal features without manual labeling?
Our modality encoders have close to half a million learnable parameters, which would require large amounts of labeled data to train with supervised learning. It would be very costly and expensive to manually label our data. However, we can design training objectives whose labels are automatically generated during data collection. In other words, we can train the encoders using self-supervised learning. Imagine trying to annotate 1000 hours of video of a robot doing a task or trying to manually label the poses of the objects. Intuitively, you’d much rather just write down a rule like ‘keep track of the force on the robot arm and label the state and action pair when force readings are too high’, rather than checking each frame one by one for when the robot is touching the box. We do something similar, by algorithmically labeling the data we collect from the robot rollouts.
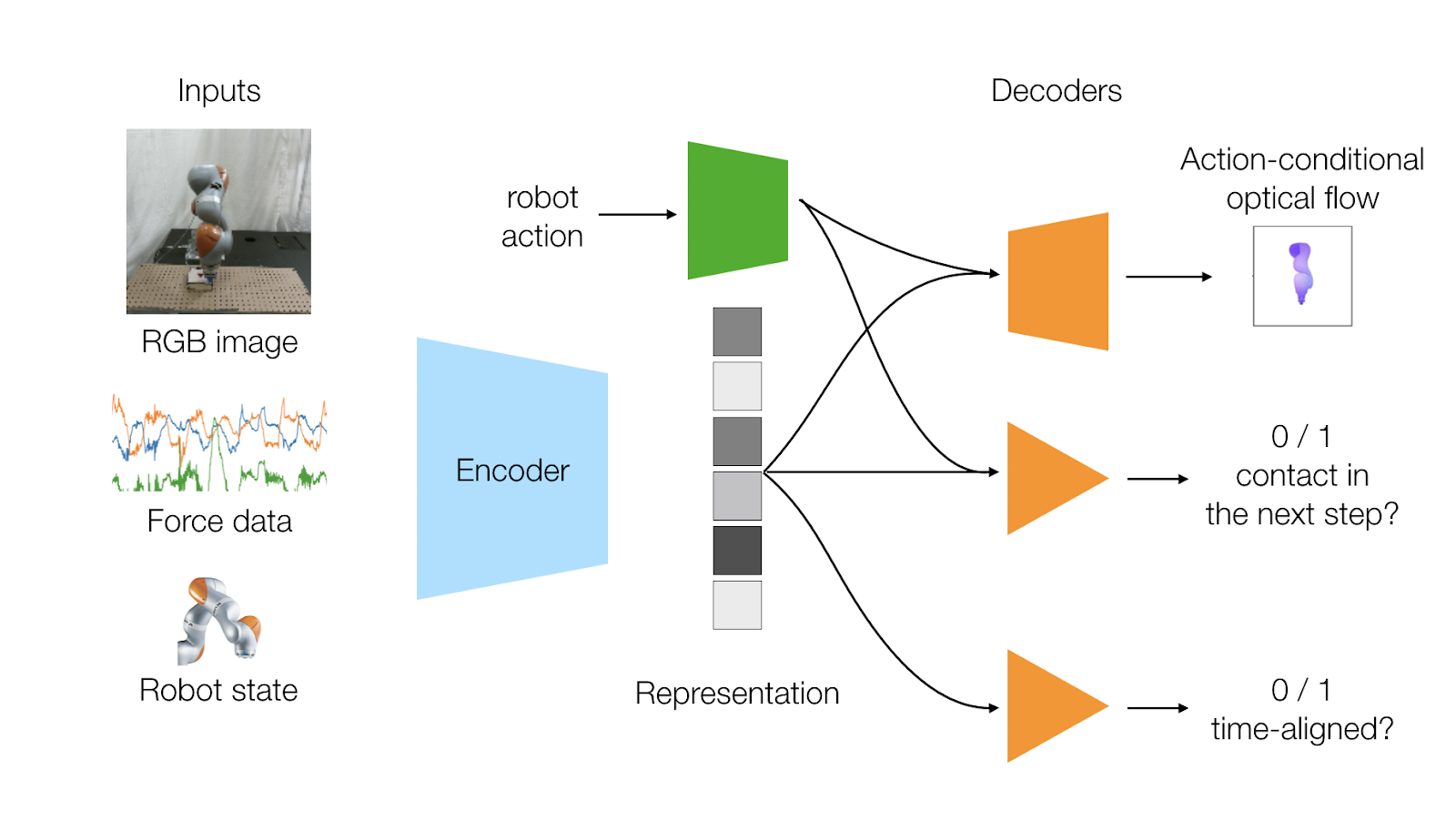
We design two learning objectives that capture the dynamics of the sensor modalities: (i) predicting the optical flow of the robot generated by the action and (ii) predicting whether the robot will make contact with the environment given the action. Since we usually know the geometry, kinematics, and meshes of a robot, ground-truth optical flow annotations can be automatically generated given the joint positions and robot kinematics. Contact prediction can also be automatically generated by looking for spikes in the force sensor data.
Our last self-supervised learning objective attempts to capture the time-locked correlation between the two different sensor modalities of vision and touch, and learn the relationship between them. When a robot touches an environment, a camera captures the interaction and the force sensor captures the contact at the same time. So, this objective predicts whether our input modalities are time aligned. During training, we give our network both time-aligned data and also randomly shifted sensor data. Our network needs to be able to predict from our representation whether the inputs are aligned or not.
To train our model, we collected 100,000 data points in 90 minutes by having the robot perform random actions as well as pre-defined actions that encourage peg insertion and collecting self-supervised labels as described above. Then, we learn our representation via standard stochastic gradient descent, training for 20 epochs.
How do we know if we have a good multimodal representation?
A good representation should:
-
Enable us to learn a policy that is able to accomplish a contact-rich manipulation task (e.g. a peg insertion task) in a sample-efficient manner
-
Generalize across task instances (e.g. different peg geometries for peg insertion)
-
Enable use to learn a policy that is robust to sensor noises, external perturbations, and different goal locations
To study how to learn this multimodal representation, we use a peg insertion task as an experimental setup. Our multimodal inputs are raw RGB image, force readings from a force/torque sensor, and end-effector position and velocity. And unlike classical works on tight tolerance peg insertion that need prior knowledge of peg geometries, we will be learning policies for different geometries directly from raw RGB images and force/torque sensor readings. More importantly, we want to learn a representation from one peg geometry, and see if that representation can generalize to new unseen geometries.
Learning a policy
We want the robot to be able to learn policies directly from its own interactions with the environment. Here, we turn to deep reinforcement learning (RL) algorithms, which enable agents to learn from trial and error and a reward function.
Deep reinforcement learning has shown great advances in playing video games, robotic grasping, and solving Rubik’s cubes. Specifically, we use Trust Region Policy Optimization3, an on-policy RL algorithm, and a dense reward that guides the robot towards the hole for peg insertion.
Once we learn the representation, we feed the representation directly to a RL policy. And we are able to learn a peg insertion task for different peg geometries in about 5 hours from raw sensory inputs.
Here is the robot when it first starts learning the task.

About 100 episodes in (which is 1.5 hours), the robot starts touching the box.
Insert gif episode 100

And in 5 hours, the robot is able to reliably insert the peg for a round peg, triangular peg, and also a semi-circular peg.

Evaluation of our representation
We evaluate how well our representation captures our multimodal sensor inputs by testing how well the representation generalizes to new task instances, how robust our policy is with the representation as state input, and how the different modalities (or lack thereof) affect the representation learning.
Generalization of our representation
We examine the potential of transferring the learned policies and representations to two novel shapes previously unseen in representation and policy training, the hexagonal peg and the square peg. For policy transfer, we take the representation model and the policy trained for the triangular peg, and execute with the new unseen square peg. As you can see in the gif below, when we do policy transfer, our success rate drops from 92% to 62%. This shows that a policy learned for one peg geometry does not necessarily transfer to a new peg geometry.
A better transfer performance can be achieved by taking the representation model trained on the triangular peg, and training a new policy for the new hexagonal peg. As seen in the gif, our peg insertion rate goes up to 92% again when we transfer the multimodal representation. Even though the learned policies do not transfer to new geometries, we show that our multimodal representation from visual and tactile feedback can transfer to new task instances. Our representation generalizes to new unseen peg geometries, and captures task-relevant information across task instances.
![]()
Policy robustness
We showed that our policy is robust to sensor noises for the force/torque sensors and for the camera.
Force Sensor Perturbation: When we tap the force/torque sensor, this sometimes tricks the robot to think it is making contact with the environment. But the policy is still able to recover from these perturbations and noises.

Camera Occlusion: When we intermittently occlude the camera after the robot has already made contact with the environment. The policy is still able to find the hole from the robot states, force readings, and the occluded images.

Goal Target Movement: We can move the box to a new location that has never been seen by the robot during training, and our robot is still able to complete the insertion.

External Forces: We can also perturb the robot and apply external forces directly on it, and is it still able to finish the insertion.

Also notice we run our policies on two different robots, the orange KUKA IIWA robot and the white Franka Panda robot, which shows that our method works on different robots.
Ablation study
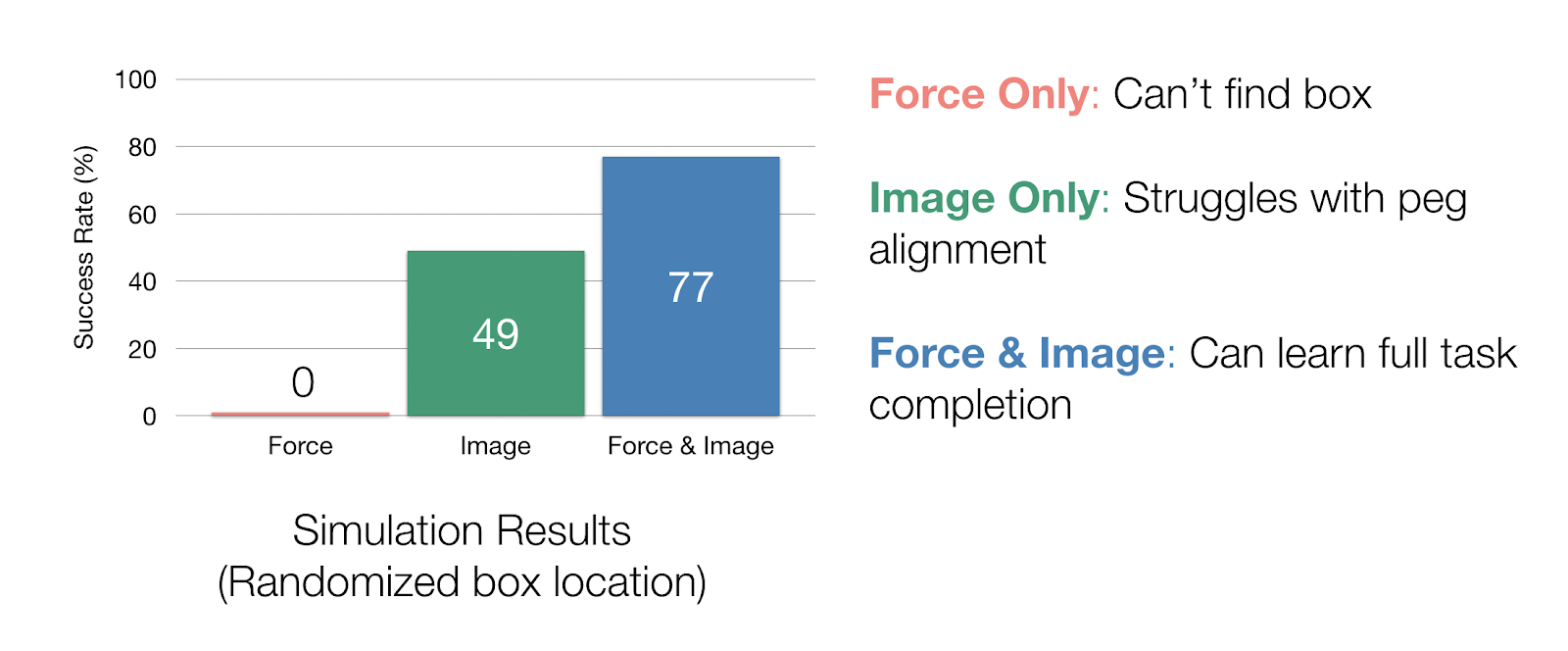
To study the effects of how the different modalities affect the representation, we ran an ablation study in simulation. In our simulation experiments where we randomize the box location, we can study how each sensor is being used by completely taking away a modality during representation and policy training. If we only have force data, our policy is not able to find the box. With only image data, we achieve a 49% task success rate, but our policy really struggles with aligning the peg with the hole, since the camera cannot capture these small precise movements. With both force and image inputs, our task completion rate goes up to 77% in simulation.
The learning curves also demonstrate that the Full Model and the Image Only Model (No Haptics) have similar returns in the beginning of the training. As training goes on and the robot learns to get closer to the box, the returns start to diverge when the Full Model is able to more quickly and robustly learn how to insert the peg with both visual and force feedback.
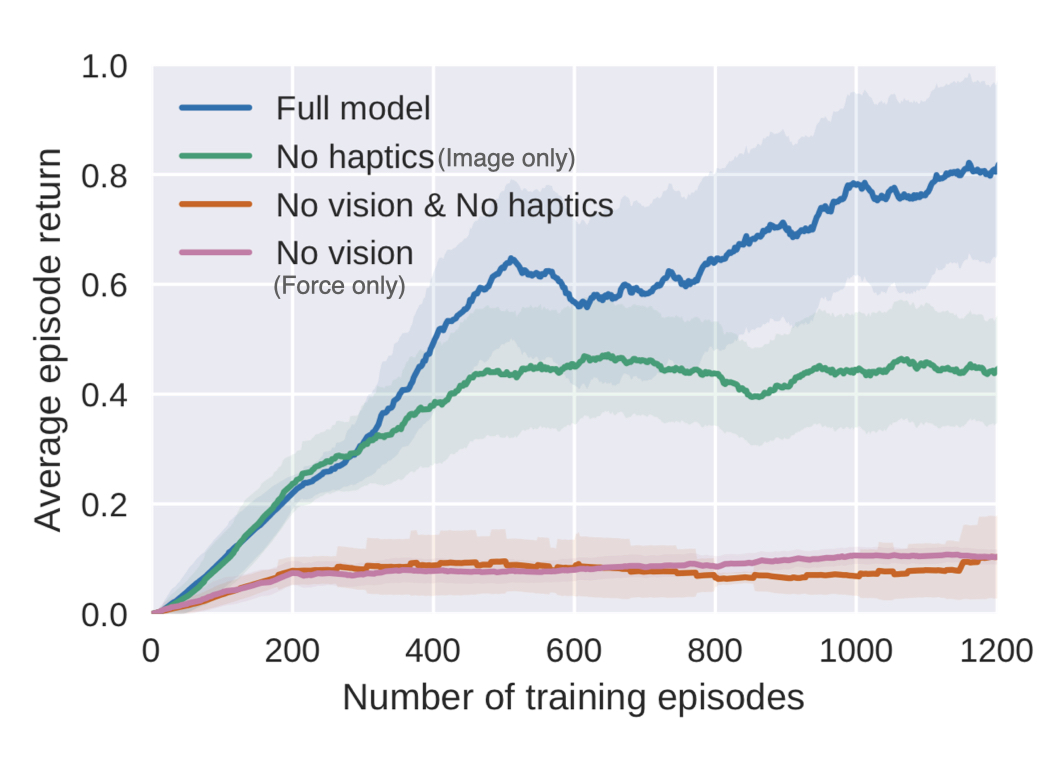
It’s not surprising that learning a representation with more modalities improves policy learning, but our result also shows that our representation and policy are using all the modalities for contact-rich tasks.
Summary
As an overview of our method, we collect self-labeled data through self-supervision, which takes about 90 minutes to collect 100k data points. We can learn a representation from this data, which takes about 24 hours training on a GPU, but is done fully offline. Afterward, you can learn new policies from the same representation, which only takes 5 hours of real robot training. This method can be done on different robots or for different kinds of tasks.
Here are some of the key takeaways from this work. The first is, self-supervision, specifically dynamics and temporal concurrency prediction can give us rich objectives to train a representation model of different modalities.
Second, our representation that captures our modality concurrency and forward dynamics can generalize across task instances (e.g. peg geometries and hole location) and is robust to sensor noise. This suggests that the features from each modality and the relationship between them are useful across different instances of contact rich tasks.
Lastly, our experiments show that learning multimodal representation leads to learning efficiency and policy robustness.
For future work, we want our method to be able to generalize beyond a task family to completely different contact-rich tasks (e.g. chopping vegetables, changing a lightbulb, inserting an electric plug). To do so, we might need to utilize more modalities, such as incorporating temperature, audio, or tactile sensors, and also find algorithms that can give us quick adaptations to new tasks.
This blog post is based on the two following papers:
-
Our ICRA 2019 conference paper: “Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks” by Michelle A. Lee*, Yuke Zhu*, Krishnan Srinivasan, Parth Shah, Silvio Savarese, Li Fei-Fei, Animesh Garg, Jeannette Bohg.4
-
Our Transactions on Robotics journal paper: “Making Sense of Vision and Touch: Learning Multimodal Representations for Contact-Rich Tasks” by Michelle A. Lee, Yuke Zhu, Peter Zachares, Matthew Tan, Krishnan Srinivasan, Silvio Savarese, Li Fei-Fei, Animesh Garg, Jeannette Bohg
For further details on this work, check out our video and our 2020 GTC Talk.
The code and multimodal dataset are available here.
Acknowledgements
Many thanks to Andrey Kurenkov, Yuke Zhu, and Jeannette Bohg for comments and edits on this blog post.