Posted by Andrey Vakunov and Dmitry Lagun, Research Engineers, Google Research
A wide range of real-world applications, including computational photography (e.g., portrait mode and glint reflections) and augmented reality effects (e.g., virtual avatars) rely on estimating eye position by tracking the iris. Once accurate iris tracking is available, we show that it is possible to determine the metric distance from the camera to the user — without the use of a dedicated depth sensor. This, in-turn, can improve a variety of use cases, ranging from computational photography, over virtual try-on of properly sized glasses and hats to usability enhancements that adopt the font size depending on the viewer’s distance.
Iris tracking is a challenging task to solve on mobile devices, due to limited computing resources, variable light conditions and the presence of occlusions, such as hair or people squinting. Often, sophisticated specialized hardware is employed, limiting the range of devices on which the solution could be applied.
 |
| FaceMesh can be adopted to drive virtual avatars (middle). By additionally employing iris tracking (right), the avatar’s liveliness is significantly enhanced. |
 |
| An example of eye re-coloring enabled by MediaPipe Iris. |
Today, we announce the release of MediaPipe Iris, a new machine learning model for accurate iris estimation. Building on our work on MediaPipe Face Mesh, this model is able to track landmarks involving the iris, pupil and the eye contours using a single RGB camera, in real-time, without the need for specialized hardware. Through use of iris landmarks, the model is also able to determine the metric distance between the subject and the camera with relative error less than 10% without the use of depth sensor. Note that iris tracking does not infer the location at which people are looking, nor does it provide any form of identity recognition. Thanks to the fact that this system is implemented in MediaPipe — an open source cross-platform framework for researchers and developers to build world-class ML solutions and applications — it can run on most modern mobile phones, desktops, laptops and even on the web.
 |
| Usability prototype for far-sighted individuals: observed font size remains constant independent of the device distance from the user. |
An ML Pipeline for Iris Tracking
The first step in the pipeline leverages our previous work on 3D Face Meshes, which uses high-fidelity facial landmarks to generate a mesh of the approximate face geometry. From this mesh, we isolate the eye region in the original image for use in the iris tracking model. The problem is then divided into two parts: eye contour estimation and iris location. We designed a multi-task model consisting of a unified encoder with a separate component for each task, which allowed us to use task-specific training data.
 |
| Examples of iris (blue) and eyelid (red) tracking. |
To train the model from the cropped eye region, we manually annotated ~50k images, representing a variety of illumination conditions and head poses from geographically diverse regions, as shown below.
 |
| Eye region annotated with eyelid (red) and iris (blue) contours. |
 |
| Cropped eye regions form the input to the model, which predicts landmarks via separate components. |
Depth-from-Iris: Depth Estimation from a Single Image
Our iris-tracking model is able to determine the metric distance of a subject to the camera with less than 10% error, without requiring any specialized hardware. This is done by relying on the fact that the horizontal iris diameter of the human eye remains roughly constant at 11.7±0.5 mm across a wide population [1, 2, 3, 4], along with some simple geometric arguments. For illustration, consider a pinhole camera model projecting onto a sensor of square pixels. The distance to a subject can be estimated from facial landmarks by using the focal length of the camera, which can be obtained using camera capture APIs or directly from the EXIF metadata of a captured image, along with other camera intrinsic parameters. Given the focal length, the distance from the subject to the camera is directly proportional to the physical size of the subject’s eye, as visualized below.
 |
| The distance of the subject (d) can be computed from the focal length (f) and the size of the iris using similar triangles. |
 |
| Left: MediaPipe Iris predicting metric distance in cm on a Pixel 2 from iris tracking alone, without the use of a depth sensor. Right: Ground-truth depth. |
In order to quantify the accuracy of the method, we compared it to the depth sensor on an iPhone 11 by collecting front-facing, synchronized video and depth images on over 200 participants. We experimentally verified the error of the iPhone 11 depth sensor to be < 2% for distances up to 2 meters, using a laser ranging device. Our evaluation shows that our approach for depth estimation using iris size has a mean relative error of 4.3% and standard deviation of 2.4%. We tested our approach on participants with and without eyeglasses (not accounting for contact lenses on participants) and found that eyeglasses increase the mean relative error slightly to 4.8% (standard deviation 3.1%). We did not test this approach on participants with any eye diseases (like arcus senilis or pannus). Considering MediaPipe Iris requires no specialized hardware, these results suggest it may be possible to obtain metric depth from a single image on devices with a wide range of cost-points.
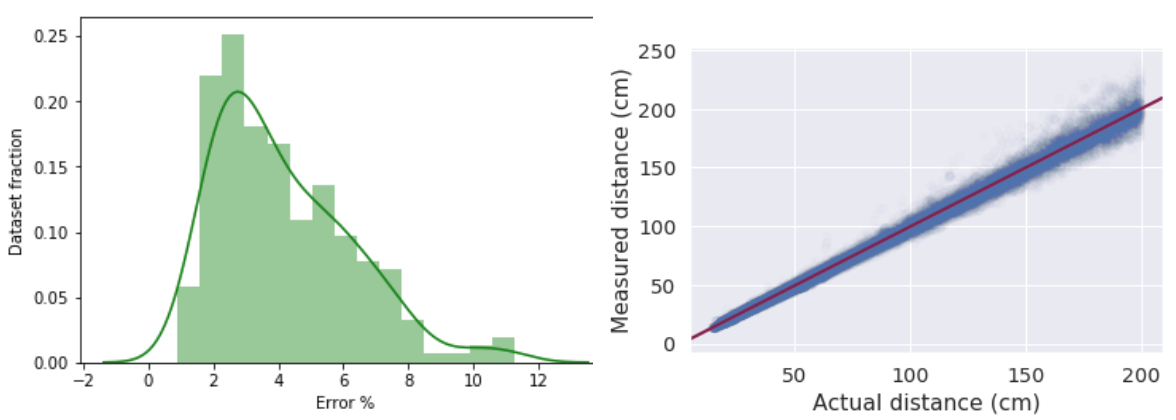 |
| Histogram of estimation errors (left) and comparison of actual to estimated distance by iris (right). |
Release of MediaPipe Iris
We are releasing the iris and depth estimation models as a cross-platform MediaPipe pipeline that can run on desktop, mobile and the web. As described in our recent Google Developer Blog post on MediaPipe on the web, we leverage WebAssembly and XNNPACK to run our Iris ML pipeline locally in the browser, without any data being sent to the cloud.
 |
 |
| Using MediaPipe’s WASM stack, you can run the models locally in your browser! Left: Iris tracking. Right: Depth from Iris computed just from a photo with EXIF data. Iris tracking can be tried out here and iris depth measurements here. |
Future Directions
We plan to extend our MediaPipe Iris model with even more stable tracking for lower error and deploy it for accessibility use cases. We strongly believe in sharing code that enables reproducible research, rapid experimentation, and development of new ideas in different areas. In our documentation and the accompanying Model Card, we detail the intended uses, limitations and model fairness to ensure that use of these models aligns with Google’s AI Principles. Note, that any form of surveillance or identification is explicitly out of scope and not enabled by this technology. We hope that providing this iris perception functionality to the wider research and development community will result in an emergence of creative use cases, stimulating responsible new applications and new research avenues.
For more ML solutions from MediaPipe, please see our solutions page and Google Developer blog for the latest updates.
Acknowledgements
We would like to thank Artsiom Ablavatski, Andrei Tkachenka, Buck Bourdon, Ivan Grishchenko and Gregory Karpiak for support in model evaluation and data collection; Yury Kartynnik, Valentin Bazarevsky, Artsiom Ablavatski for developing the mesh technology; Aliaksandr Shyrokau and the annotation team for their diligence to data preparation; Vidhya Navalpakkam, Tomer, Tomer Shekel, Kai Kohlhoff for their domain expertise, Fan Zhang, Esha Uboweja, Tyler Mullen, Michael Hays and Chuo-Ling Chang for help to integrate the model to MediaPipe; Matthias Grundmann, Florian Schroff and Ming Guang Yong for continuous help for building this technology.
