Mitra: Mixed synthetic priors for enhancing tabular foundation models
Generating diverse synthetic prior distributions leads to a tabular foundation model that outperforms task-specific baselines.
Machine learning
Xiyuan Zhang Danielle Maddix RobinsonJuly 22, 01:40 PMJuly 22, 01:40 PM
Tabular data powers critical decisions across domains such as healthcare, finance, e-commerce, and the sciences. The machine learning methods traditionally used for tabular data, however such as random forests and XGBoost typically result in models tailored to individual datasets, with limited ability to transfer across different distributions.
Inspired by the success of large language models, tabular foundation models (TFMs) promise to change that: instead of requiring a separately trained model for each task, a single pretrained model can generalize to new tasks simply by conditioning on a moderate number of examples, a technique known as in-context learning (ICL).
As part of the latest release of Amazons automatic-machine-learning framework AutoGluon, we are introducing Mitra, a tabular foundation model trained within this ICL-based paradigm. Much the way large language models (LLMs) are trained on diverse corpora of text, Mitra is pretrained on synthetic datasets generated by a carefully designed mixture of prior distributions (priors).
At first blush, it may seem surprising that we used no real-world data in pretraining Mitra. But real-world tabular data is often limited and heterogeneous, with varying feature types, dependencies, and noise levels. It proves more practical to simulate diverse synthetic datasets that cover a wide range of possible data patterns.
We find that the quality of these synthetic priors plays a critical role in how well the model generalizes. Effective priors tend to (1) yield good performance on real tasks; (2) exhibit diversity, which prevents the overfitting; and (3) offer unique patterns not found in other priors.
Based on these principles, we construct a mixture that includes structural causal models, which combine graphs of the causal dependencies between variables with (probabilistic) equations describing the effects that varying each variables value has on its dependent variables; and popular tree-based methods like gradient boosting, random forests, and decision trees. Together, these priors enable Mitra to learn robust representations and generalize effectively to a wide variety of real-world tabular problems.
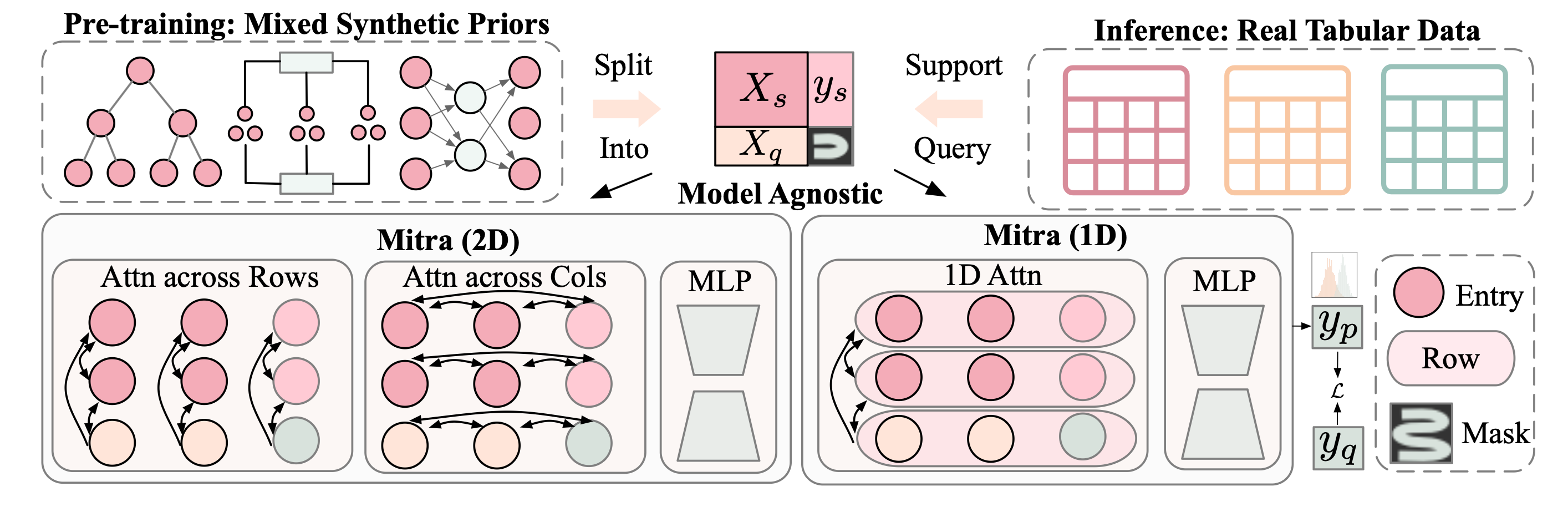
We pretrain Mitra on our selected mixture of priors. Each synthetic task consists of a support set and a query set. The model learns to predict the labels of the query set by attending to the support set; no gradient updates are required. Over millions of such tasks, Mitra learns generalizable patterns of reasoning and adaptation. The architecture is based on 2-D attention across both rows and features, allowing flexible handling of varying table sizes and feature interactions.
We evaluated Mitra on both classification and regression tasks, across major tabular benchmarks such as TabRepo, TabZilla, AMLB, and TabArena. Mitra demonstrated state-of-the-art performance when compared with strong TFMs such as TabPFNv2 and TabICL, as well as with dataset-specific models such as CatBoost, RealMLP, and AutoGluon 1.3 best-quality preset.
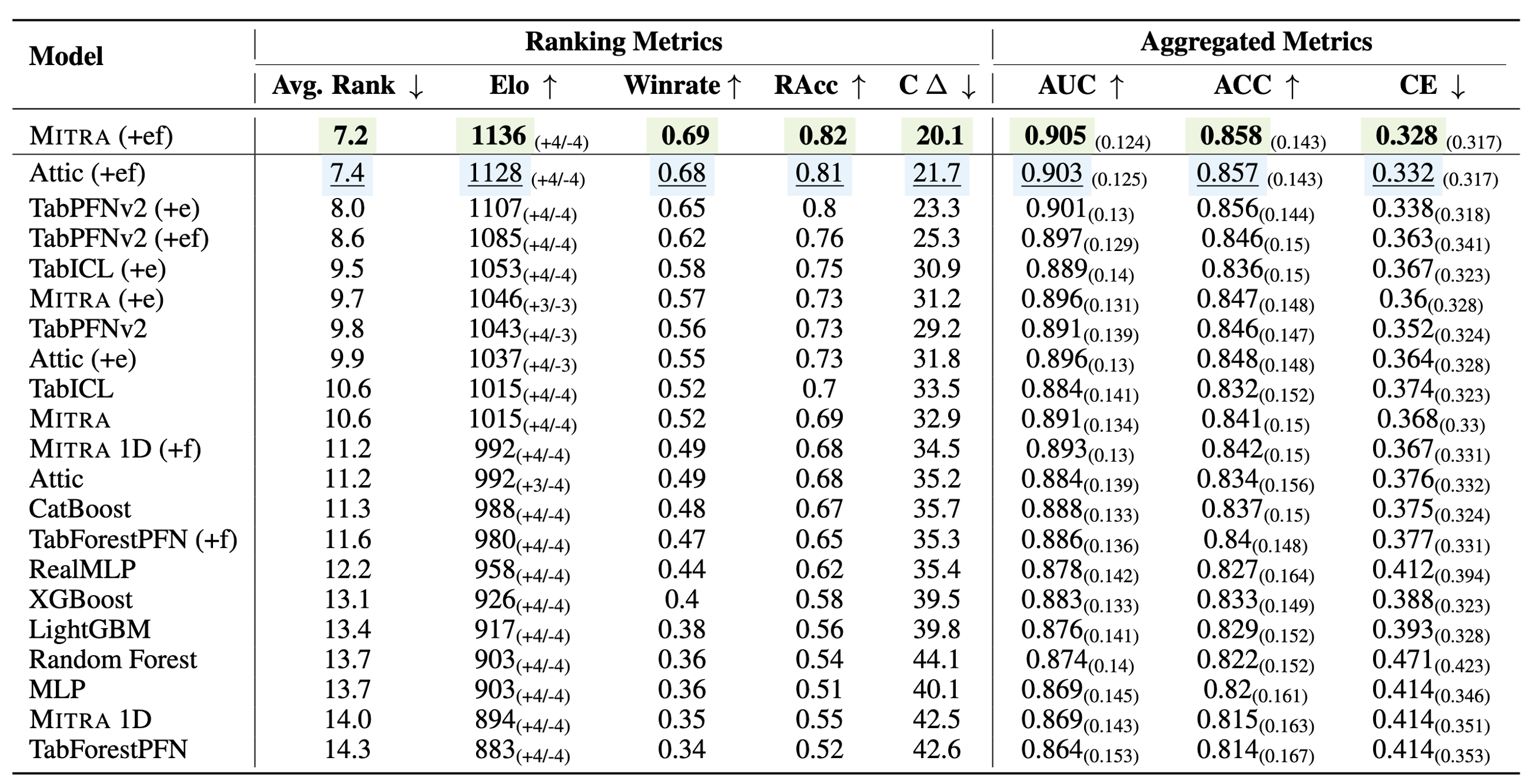
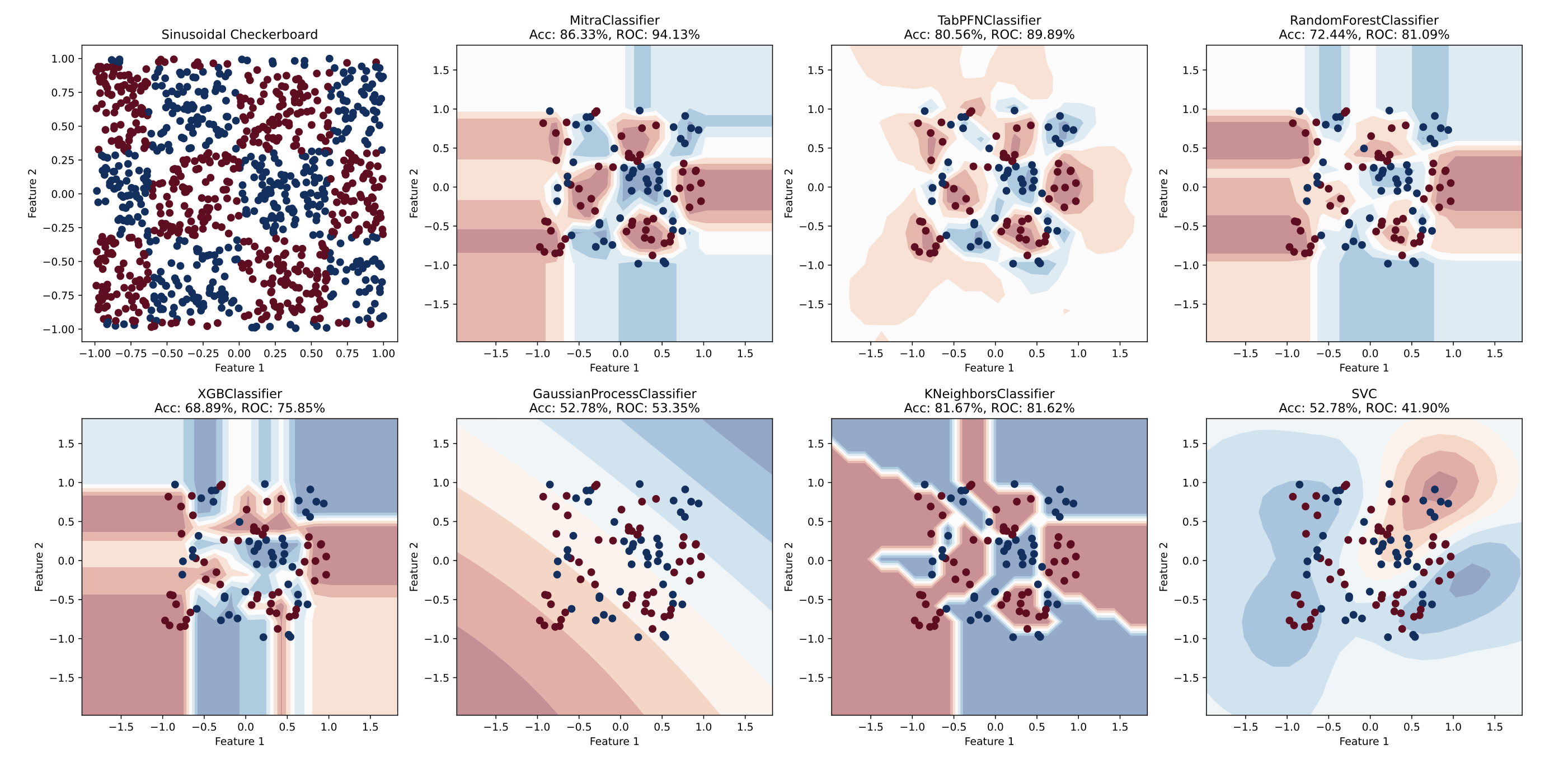
Just as foundation models have reshaped the domains of computer vision and natural-language processing, Mitra offers a more general and effective approach to tabular-data prediction. As the field progresses, we envision even richer prior spaces and adaptive mixture strategies. Mitra is open sourced (links below) in the AutoGluon 1.4 release and ready to use. We invite researchers and practitioners to explore this new foundation for tabular prediction.
Learn more:
Acknowledgments: Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W. Mahoney, Cuixiong Hu, Huzefa Rangwala, George Karypis, Bernie Wang
Research areas: Machine learning
Tags: Tabular data