We are bringing a number of improvements to the current PyTorch libraries, alongside the PyTorch 1.12 release. These updates demonstrate our focus on developing common and extensible APIs across all domains to make it easier for our community to build ecosystem projects on PyTorch.
Summary:
- TorchVision – Added multi-weight support API, new architectures, model variants, and pretrained weight. See the release notes here.
- TorchAudio – Introduced beta features including a streaming API, a CTC beam search decoder, and new beamforming modules and methods. See the release notes here.
- TorchText – Extended support for scriptable BERT tokenizer and added datasets for GLUE benchmark. See the release notes here.
- TorchRec – Added EmbeddingModule benchmarks, examples for TwoTower Retrieval, inference and sequential embeddings, metrics, improved planner and demonstrated integration with production components. See the release notes here.
- TorchX – Launch PyTorch trainers developed on local workspaces onto five different types of schedulers. See the release notes here.
- FBGemm – Added and improved kernels for Recommendation Systems inference workloads, including table batched embedding bag, jagged tensor operations, and other special-case optimizations.
TorchVision v0.13
Multi-weight support API
TorchVision v0.13 offers a new Multi-weight support API for loading different weights to the existing model builder methods:
from torchvision.models import *
# Old weights with accuracy 76.130%
resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
# New weights with accuracy 80.858%
resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
# Best available weights (currently alias for IMAGENET1K_V2)
# Note that these weights may change across versions
resnet50(weights=ResNet50_Weights.DEFAULT)
# Strings are also supported
resnet50(weights="IMAGENET1K_V2")
# No weights - random initialization
resnet50(weights=None)
The new API bundles along with the weights important details such as the preprocessing transforms and meta-data such as labels. Here is how to make the most out of it:
from torchvision.io import read_image
from torchvision.models import resnet50, ResNet50_Weights
img = read_image("test/assets/encode_jpeg/grace_hopper_517x606.jpg")
# Step 1: Initialize model with the best available weights
weights = ResNet50_Weights.DEFAULT
model = resnet50(weights=weights)
model.eval()
# Step 2: Initialize the inference transforms
preprocess = weights.transforms()
# Step 3: Apply inference preprocessing transforms
batch = preprocess(img).unsqueeze(0)
# Step 4: Use the model and print the predicted category
prediction = model(batch).squeeze(0).softmax(0)
class_id = prediction.argmax().item()
score = prediction[class_id].item()
category_name = weights.meta["categories"][class_id]
print(f"{category_name}: {100 * score:.1f}%")
You can read more about the new API in the docs. To provide your feedback, please use this dedicated Github issue.
New architectures and model variants
Classification
The Swin Transformer and EfficienetNetV2 are two popular classification models which are often used for downstream vision tasks. This release includes 6 pre-trained weights for their classification variants. Here is how to use the new models:
import torch
from torchvision.models import *
image = torch.rand(1, 3, 224, 224)
model = swin_t(weights="DEFAULT").eval()
prediction = model(image)
image = torch.rand(1, 3, 384, 384)
model = efficientnet_v2_s(weights="DEFAULT").eval()
prediction = model(image)
In addition to the above, we also provide new variants for existing architectures such as ShuffleNetV2, ResNeXt and MNASNet. The accuracies of all the new pre-trained models obtained on ImageNet-1K are seen below:
| Model | Acc@1 | Acc@5 |
|---|---|---|
| swin_t | 81.474 | 95.776 |
| swin_s | 83.196 | 96.36 |
| swin_b | 83.582 | 96.64 |
| efficientnet_v2_s | 84.228 | 96.878 |
| efficientnet_v2_m | 85.112 | 97.156 |
| efficientnet_v2_l | 85.808 | 97.788 |
| resnext101_64x4d | 83.246 | 96.454 |
| resnext101_64x4d (quantized) | 82.898 | 96.326 |
| shufflenet_v2_x1_5 | 72.996 | 91.086 |
| shufflenet_v2_x1_5 (quantized) | 72.052 | 0.700 |
| shufflenet_v2_x2_0 | 76.230 | 93.006 |
| shufflenet_v2_x2_0 (quantized) | 75.354 | 92.488 |
| mnasnet0_75 | 71.180 | 90.496 |
| mnas1_3 | 76.506 | 93.522 |
We would like to thank Hu Ye for contributing to TorchVision the Swin Transformer implementation.
(BETA) Object Detection and Instance Segmentation
We have introduced 3 new model variants for RetinaNet, FasterRCNN and MaskRCNN that include several post-paper architectural optimizations and improved training recipes. All models can be used similarly:
import torch
from torchvision.models.detection import *
images = [torch.rand(3, 800, 600)]
model = retinanet_resnet50_fpn_v2(weights="DEFAULT")
# model = fasterrcnn_resnet50_fpn_v2(weights="DEFAULT")
# model = maskrcnn_resnet50_fpn_v2(weights="DEFAULT")
model.eval()
prediction = model(images)
Below we present the metrics of the new variants on COCO val2017. In parenthesis we denote the improvement over the old variants:
| Model | Box mAP | Mask mAP |
|---|---|---|
| retinanet_resnet50_fpn_v2 | 41.5 (+5.1) | – |
| fasterrcnn_resnet50_fpn_v2 | 46.7 (+9.7) | – |
| maskrcnn_resnet50_fpn_v2 | 47.4 (+9.5) | 41.8 (+7.2) |
We would like to thank Ross Girshick, Piotr Dollar, Vaibhav Aggarwal, Francisco Massa and Hu Ye for their past research and contributions to this work.
New pre-trained weights
SWAG weights
The ViT and RegNet model variants offer new pre-trained SWAG (Supervised Weakly from hashtAGs) weights. One of the biggest of these models achieves a whopping 88.6% accuracy on ImageNet-1K. We currently offer two versions of the weights: 1) fine-tuned end-to-end weights on ImageNet-1K (highest accuracy) and 2) frozen trunk weights with a linear classifier fit on ImageNet-1K (great for transfer learning). Below we see the detailed accuracies of each model variant:
| Model Weights | Acc@1 | Acc@5 |
|---|---|---|
| RegNet_Y_16GF_Weights.IMAGENET1K_SWAG_E2E_V1 | 86.012 | 98.054 |
| RegNet_Y_16GF_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 83.976 | 97.244 |
| RegNet_Y_32GF_Weights.IMAGENET1K_SWAG_E2E_V1 | 86.838 | 98.362 |
| RegNet_Y_32GF_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 84.622 | 97.48 |
| RegNet_Y_128GF_Weights.IMAGENET1K_SWAG_E2E_V1 | 88.228 | 98.682 |
| RegNet_Y_128GF_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 86.068 | 97.844 |
| ViT_B_16_Weights.IMAGENET1K_SWAG_E2E_V1 | 85.304 | 97.65 |
| ViT_B_16_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 81.886 | 96.18 |
| ViT_L_16_Weights.IMAGENET1K_SWAG_E2E_V1 | 88.064 | 98.512 |
| ViT_L_16_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 85.146 | 97.422 |
| ViT_H_14_Weights.IMAGENET1K_SWAG_E2E_V1 | 88.552 | 98.694 |
| ViT_H_14_Weights.IMAGENET1K_SWAG_LINEAR_V1 | 85.708 | 97.73 |
The SWAG weights are released under the Attribution-NonCommercial 4.0 International license. We would like to thank Laura Gustafson, Mannat Singh and Aaron Adcock for their work and support in making the weights available to TorchVision.
Model Refresh
The release of the Multi-weight support API enabled us to refresh the most popular models and offer more accurate weights. We improved on average each model by ~3 points. The new recipe used was learned on top of ResNet50 and its details were covered on a previous blog post.
| Model | Old weights | New weights |
|---|---|---|
| efficientnet_b1 | 78.642 | 79.838 |
| mobilenet_v2 | 71.878 | 72.154 |
| mobilenet_v3_large | 74.042 | 75.274 |
| regnet_y_400mf | 74.046 | 75.804 |
| regnet_y_800mf | 76.42 | 78.828 |
| regnet_y_1_6gf | 77.95 | 80.876 |
| regnet_y_3_2gf | 78.948 | 81.982 |
| regnet_y_8gf | 80.032 | 82.828 |
| regnet_y_16gf | 80.424 | 82.886 |
| regnet_y_32gf | 80.878 | 83.368 |
| regnet_x_400mf | 72.834 | 74.864 |
| regnet_x_800mf | 75.212 | 77.522 |
| regnet_x_1_6gf | 77.04 | 79.668 |
| regnet_x_3_2gf | 78.364 | 81.196 |
| regnet_x_8gf | 79.344 | 81.682 |
| regnet_x_16gf | 80.058 | 82.716 |
| regnet_x_32gf | 80.622 | 83.014 |
| resnet50 | 76.13 | 80.858 |
| resnet50 (quantized) | 75.92 | 80.282 |
| resnet101 | 77.374 | 81.886 |
| resnet152 | 78.312 | 82.284 |
| resnext50_32x4d | 77.618 | 81.198 |
| resnext101_32x8d | 79.312 | 82.834 |
| resnext101_32x8d (quantized) | 78.986 | 82.574 |
| wide_resnet50_2 | 78.468 | 81.602 |
| wide_resnet101_2 | 78.848 | 82.51 |
We would like to thank Piotr Dollar, Mannat Singh and Hugo Touvron for their past research and contributions to this work.
New Augmentations, Layers and Losses
This release brings a bunch of new primitives which can be used to produce SOTA models. Some highlights include the addition of AugMix data-augmentation method, the DropBlock layer, the cIoU/dIoU loss and many more. We would like to thank Aditya Oke, Abhijit Deo, Yassine Alouini and Hu Ye for contributing to the project and for helping us maintain TorchVision relevant and fresh.
Documentation
We completely revamped our models documentation to make them easier to browse, and added various key information such as supported image sizes, or image pre-processing steps of pre-trained weights. We now have a main model page with various summary tables of available weights, and each model has a dedicated page. Each model builder is also documented in their own page, with more details about the available weights, including accuracy, minimal image size, link to training recipes, and other valuable info. For comparison, our previous models docs are here. To provide feedback on the new documentation, please use the dedicated Github issue.
TorchAudio v0.12
(BETA) Streaming API


StreamReader is TorchAudio’s new I/O API. It is backed by FFmpeg†, and allows users to:
- Decode audio and video formats, including MP4 and AAC
- Handle input forms, such as local files, network protocols, microphones, webcams, screen captures and file-like objects
- Iterate over and decode chunk-by-chunk, while changing the sample rate or frame rate
- Apply audio and video filters, such as low-pass filter and image scaling
- Decode video with Nvidia’s hardware-based decoder (NVDEC)
For usage details, please check out the documentation and tutorials:
- Media Stream API – Pt.1
- Media Stream API – Pt.2
- Online ASR with Emformer RNN-T
- Device ASR with Emformer RNN-T
- Accelerated Video Decoding with NVDEC
† To use StreamReader, FFmpeg libraries are required. Please install FFmpeg. The coverage of codecs depends on how these libraries are configured. TorchAudio official binaries are compiled to work with FFmpeg 4 libraries; FFmpeg 5 can be used if TorchAudio is built from source.
(BETA) CTC Beam Search Decoder
TorchAudio integrates the wav2letter CTC beam search decoder from Flashlight (GitHub). The addition of this inference time decoder enables running end-to-end CTC ASR evaluation using TorchAudio utils.
Customizable lexicon and lexicon-free decoders are supported, and both are compatible with KenLM n-gram language models or without using a language model. TorchAudio additionally supports downloading token, lexicon, and pretrained KenLM files for the LibriSpeech dataset.
For usage details, please check out the documentation and ASR inference tutorial.
(BETA) New Beamforming Modules and Methods
To improve flexibility in usage, the release adds two new beamforming modules under torchaudio.transforms: SoudenMVDR and RTFMVDR. The main differences from MVDR are:
- Use power spectral density (PSD) and relative transfer function (RTF) matrices as inputs instead of time-frequency masks. The module can be integrated with neural networks that directly predict complex-valued STFT coefficients of speech and noise
- Add ‘reference_channel’ as an input argument in the forward method, to allow users to select the reference channel in model training or dynamically change the reference channel in inference
Besides the two modules, new function-level beamforming methods are added under torchaudio.functional. These include:
For usage details, please check out the documentation at torchaudio.transforms and torchaudio.functional and the Speech Enhancement with MVDR Beamforming tutorial.
TorchText v0.13
Glue Datasets
We increased the number of datasets in TorchText from 22 to 30 by adding the remaining 8 datasets from the GLUE benchmark (SST-2 was already supported). The complete list of GLUE datasets is as follows:
- CoLA (paper): Single sentence binary classification acceptability task
- SST-2 (paper): Single sentence binary classification sentiment task
- MRPC (paper): Dual sentence binary classification paraphrase task
- QQP: Dual sentence binary classification paraphrase task
- STS-B (paper): Single sentence to float regression sentence similarity task
- MNLI (paper): Sentence ternary classification NLI task
- QNLI (paper): Sentence binary classification QA and NLI tasks
- RTE (paper): Dual sentence binary classification NLI task
- WNLI (paper): Dual sentence binary classification coreference and NLI tasks
Scriptable BERT Tokenizer
TorchText has extended support for scriptable tokenizer by adding the WordPiece tokenizer used in BERT. It is one of the commonly used algorithms for splitting input text into sub-words units and was introduced in Japanese and Korean Voice Search (Schuster et al., 2012).
TorchScriptabilty support would allow users to embed the BERT text-preprocessing natively in C++ without needing the support of python runtime. As TorchText now supports the CMAKE build system to natively link torchtext binaries with application code, users can easily integrate BERT tokenizers for deployment needs.
For usage details, please refer to the corresponding documentation.
TorchRec v0.2.0
EmbeddingModule + DLRM benchmarks
A set of benchmarking tests, showing performance characteristics of TorchRec’s base modules and research models built out of TorchRec.
TwoTower Retrieval Example, with FAISS
We provide an example demonstrating training a distributed TwoTower (i.e. User-Item) Retrieval model that is sharded using TorchRec. The projected item embeddings are added to an IVFPQ FAISS index for candidate generation. The retrieval model and KNN lookup are bundled in a Pytorch model for efficient end-to-end retrieval.
Integrations
We demonstrate that TorchRec works out of the box with many components commonly used alongside PyTorch models in production like systems, such as
- Training a TorchRec model on Ray Clusters utilizing the Torchx Ray scheduler
- Preprocessing and DataLoading with NVTabular on DLRM
- Training a TorchRec model with on-the-fly preprocessing with TorchArrow showcasing RecSys domain UDFs
Sequential Embeddings Example: Bert4Rec
We provide an example, using TorchRec, that reimplements the BERT4REC paper, showcasing EmbeddingCollection for non-pooled embeddings. Using DistributedModelParallel we see a 35% QPS gain over conventional data parallelism.
(Beta) Planner
The TorchRec library includes a built-in planner that selects near optimal sharding plan for a given model. The planner attempts to identify the best sharding plan by evaluating a series of proposals which are statically analyzed and fed into an integer partitioner. The planner is able to automatically adjust plans for a wide range of hardware setups, allowing users to scale performance seamlessly from local development environment to large scale production hardware. See this notebook for a more detailed tutorial.
(Beta) Inference
TorchRec Inference is a C++ library that supports multi-gpu inference. The TorchRec library is used to shard models written and packaged in Python via torch.package (an alternative to TorchScript). The torch.deploy library is used to serve inference from C++ by launching multiple Python interpreters carrying the packaged model, thus subverting the GIL. Two models are provided as examples: DLRM multi-GPU (sharded via TorchRec) and DLRM single-GPU.
(Beta) RecMetrics
RecMetrics is a metrics library that collects common utilities and optimizations for Recommendation models. It extends torchmetrics.
- A centralized metrics module that allows users to add new metrics
- Commonly used metrics, including AUC, Calibration, CTR, MSE/RMSE, NE & Throughput
- Optimization for metrics related operations to reduce the overhead of metric computation
- Checkpointing
(Prototype) Single process Batched + Fused Embeddings
Previously TorchRec’s abstractions (EmbeddingBagCollection/EmbeddingCollection) over FBGEMM kernels, which provide benefits such as table batching, optimizer fusion, and UVM placement, could only be used in conjunction with DistributedModelParallel. We’ve decoupled these notions from sharding, and introduced the FusedEmbeddingBagCollection, which can be used as a standalone module, with all of the above features, and can also be sharded.
TorchX v0.2.0
TorchX is a job launcher that makes it easier to run PyTorch in distributed training clusters with many scheduler integrations including Kubernetes and Slurm. We’re excited to release TorchX 0.2.0 with a number of improvements. TorchX is currently being used in production in both on-premise and cloud environments.
Check out the quickstart to start launching local and remote jobs.
Workspaces
TorchX now supports workspaces which allows users to easily launch training jobs using their local workspace. TorchX can automatically build a patch with your local training code on top of a base image to minimize iteration time and time to training.
.torchxconfig
Specifying options in .torchxconfig saves you from having to type long CLI commands each time you launch a job. You can also define project level generic configs and drop a config file in your home directory for user-level overrides.
Expanded Scheduler Support
TorchX now supports AWS Batch and Ray (experimental) schedulers in addition to our existing integrations.
Distributed Training On All Schedulers
The TorchX dist.ddp component now works on all schedulers without any configuration. Distributed training workers will automatically discover each other when using torchelastic via the builtin dist.ddp component.
Hyper Parameter Optimization
TorchX integrates with Ax to let you scale hyper-parameter optimizations (HPO) by launching the search trials onto remote clusters.
File and Device Mounts
TorchX now supports remote filesystem mounts and custom devices. This enables your PyTorch jobs to efficiently access cloud storage such as NFS or Lustre. The device mounts enables usage of network accelerators like Infiniband and custom inference/training accelerators.
FBGemm v0.2.0
The FBGEMM library contains optimized kernels meant to improve the performance of PyTorch workloads. We’ve added a number of new features and optimizations over the last few months that we are excited to report.
Inference Table Batched Embedding (TBE)
The table batched embedding bag (TBE) operator is an important base operation for embedding lookup for recommendation system inference on GPU. We added the following enhancements for performance and flexibility:
Alignment restriction removed
- Embedding dimension * data type size had to be multiple of 4B before and now, it is 1B.
Unified Virtual Memory (UVM) caching kernel optimizations
- UVM caching kernels now scale linearly with # of tables using UVM caching. Previously, it was having similar overhead as all tables using UVM caching
- UVM caching kernel overhead is much smaller than before
Inference FP8 Table Batched Embedding (TBE)
The table batched embedding bag (TBE) previously supported FP32, FP16, INT8, INT4, and INT2 embedding weight types. While these weight types work well in many models, we integrate FP8 weight types (in both GPU and CPU operations) to allow for numerical and performance evaluations of FP8 in our models. Compared to INT8, FP8 does not require the additional bias and scale storage and calculations. Additionally, the next generation of H100 GPUs has the FP8 support on Tensor Core (mainly matmul ops).
Jagged Tensor Kernels
We added optimized kernels to speed up TorchRec JaggedTensor. The purpose of JaggedTensor is to handle the case where one dimension of the input data is “jagged”, meaning that each consecutive row in a given dimension may be a different length, which is often the case with sparse feature inputs in recommendation systems. The internal representation is shown below:
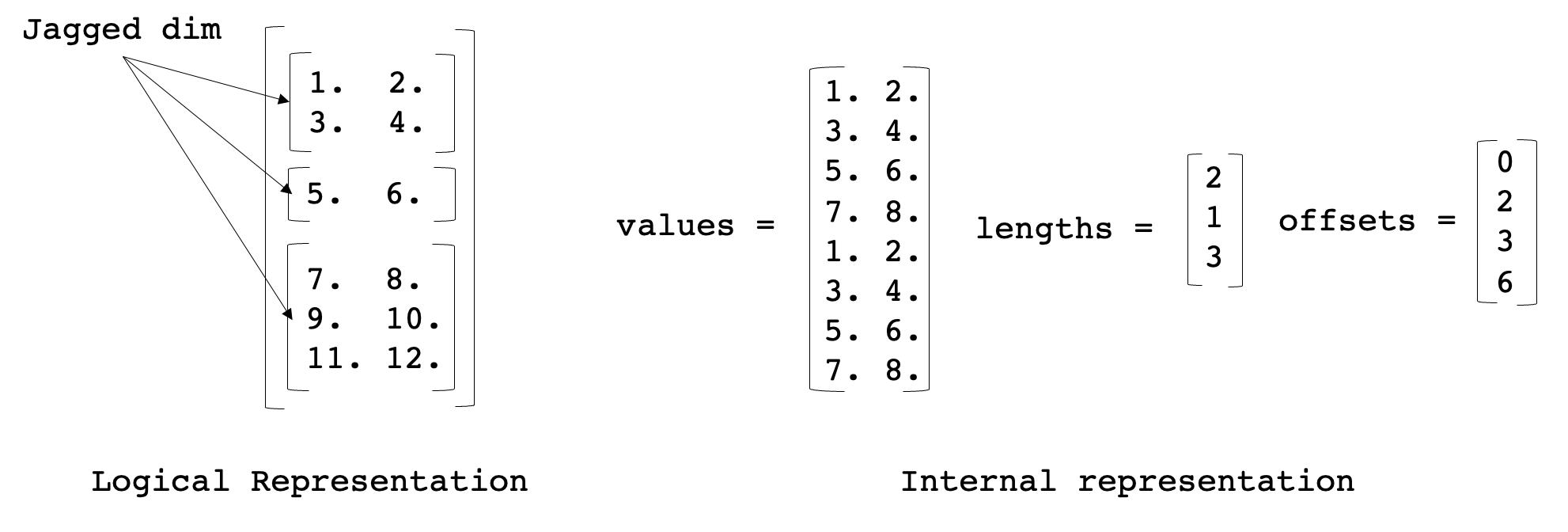
We added ops for converting jagged tensors from sparse to dense formats and back, performing matrix multiplications with jagged tensors, and elementwise ops.
Optimized permute102-baddbmm-permute102
It is difficult to fuse various matrix multiplications where the batch size is not the batch size of the model, switching the batch dimension is a quick solution. We created the permute102_baddbmm_permute102 operation that switches the first and the second dimension, performs the batched matrix multiplication and then switches back. Currently we only support forward pass with FP16 data type and will support FP32 type and backward pass in the future.
Optimized index_select for dim 0 index selection
index_select is normally used as part of a sparse operation. While PyTorch supports a generic index_select for an arbitrary-dimension index selection, its performance for a special case like the dim 0 index selection is suboptimal. For this reason, we implement a specialized index_select for dim 0. In some cases, we have observed 1.4x performance gain from FBGEMM’s index_select compared to the one from PyTorch (using uniform index distribution).
More about the implementation of influential instances can be found on our GitHub page and tutorials.
Thanks for reading, If you’re interested in these updates and want to join the PyTorch community, we encourage you to join the discussion forums and open GitHub issues. To get the latest news from PyTorch, follow us on Twitter, Medium, YouTube, and LinkedIn.
Cheers!
Team PyTorch