
Posted by Ronny Votel and Na Li, Google Research
Today we’re excited to launch our latest pose detection model, MoveNet, with our new pose-detection API in TensorFlow.js. MoveNet is an ultra fast and accurate model that detects 17 keypoints of a body. The model is offered on TF Hub with two variants, known as Lightning and Thunder. Lightning is intended for latency-critical applications, while Thunder is intended for applications that require high accuracy. Both models run faster than real time (30+ FPS) on most modern desktops, laptops, and phones, which proves crucial for live fitness, sports, and health applications. This is achieved by running the model completely client-side, in the browser using TensorFlow.js with no server calls needed after the initial page load and no dependencies to install.
|
| MoveNet can track keypoints through fast motions and atypical poses. |
Human pose estimation has come a long way in the last five years, but surprisingly hasn’t surfaced in many applications just yet. This is because more focus has been placed on making pose models larger and more accurate, rather than doing the engineering work to make them fast and deployable everywhere. With MoveNet, our mission was to design and optimize a model that leverages the best aspects of state-of-the-art architectures, while keeping inference times as low as possible. The result is a model that can deliver accurate keypoints across a wide variety of poses, environments, and hardware setups.
Unlocking Live Health Applications with MoveNet
We teamed up with IncludeHealth, a digital health and performance company, to understand whether MoveNet can help unlock remote care for patients. IncludeHealth has developed an interactive web application that guides a patient through a variety of routines (using a phone, tablet, or laptop) from the comfort of their own home. The routines are digitally built and prescribed by physical therapists to test balance, strength, and range of motion.
The service requires web-based and locally run pose models for privacy that can deliver precise keypoints at high frame rates, which are then used to quantify and qualify human poses and movements. While a typical off-the-shelf detector is sufficient for easy movements such as shoulder abductions or full body squats, more complicated poses such as seated knee extensions or supine positions (laying down) cause grief for even state-of-the-art detectors trained on the wrong data.
 |
| Comparison of a traditional detector (top) vs MoveNet (bottom) on difficult poses. |
We provided an early release of MoveNet to IncludeHealth, accessible through the new pose-detection API. This model is trained on fitness, dance, and yoga poses (see more details about the training dataset below). IncludeHealth integrated the model into their application and benchmarked MoveNet relative to other available pose detectors:
“The MoveNet model has infused a powerful combination of speed and accuracy needed to deliver prescriptive care. While other models trade one for the other, this unique balance has unlocked the next generation of care delivery. The Google team has been a fantastic collaborator in this pursuit.” – Ryan Eder, Founder & CEO at IncludeHealth.
As a next step, IncludeHealth is partnering with hospital systems, insurance plans, and the military to enable the extension of traditional care and training beyond brick and mortar.
 |
| IncludeHealth demo application running in browser that quantifies balance and motion using keypoint estimation powered by MoveNet and TensorFlow.js |
Installation
There are two ways to use MoveNet with the new pose-detection api:
- Through NPM:
import * as poseDetection from '@tensorflow-models/pose-detection'; - Through script tag:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-core"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-converter"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs-backend-webgl"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/pose-detection"></script>
Try it yourself!
Once the package is installed, you only need to follow the few steps below to start using it:
// Create a detector.
const detector = await poseDetection.createDetector(poseDetection.SupportedModels.MoveNet);The detector defaults to use the Lightning version; to choose the Thunder version, create the detector as below:
// Create a detector.
const detector = await poseDetection.createDetector(poseDetection.SupportedModels.MoveNet, {modelType: poseDetection.movenet.modelType.SINGLEPOSE_THUNDER});// Pass in a video stream to the model to detect poses.
const video = document.getElementById('video');
const poses = await detector.estimatePoses(video);Each pose contains 17 keypoints, with absolute x, y coordinates, confidence score and name:
console.log(poses[0].keypoints);
// Outputs:
// [
// {x: 230, y: 220, score: 0.9, name: "nose"},
// {x: 212, y: 190, score: 0.8, name: "left_eye"},
// ...
// ]Refer to our README for more details about the API.
As you begin to play and develop with MoveNet, we would appreciate your feedback and contributions. If you make something using this model, tag it with #MadeWithTFJS on social so we can find your work, as we would love to see what you create.
MoveNet Deep Dive
MoveNet Architecture
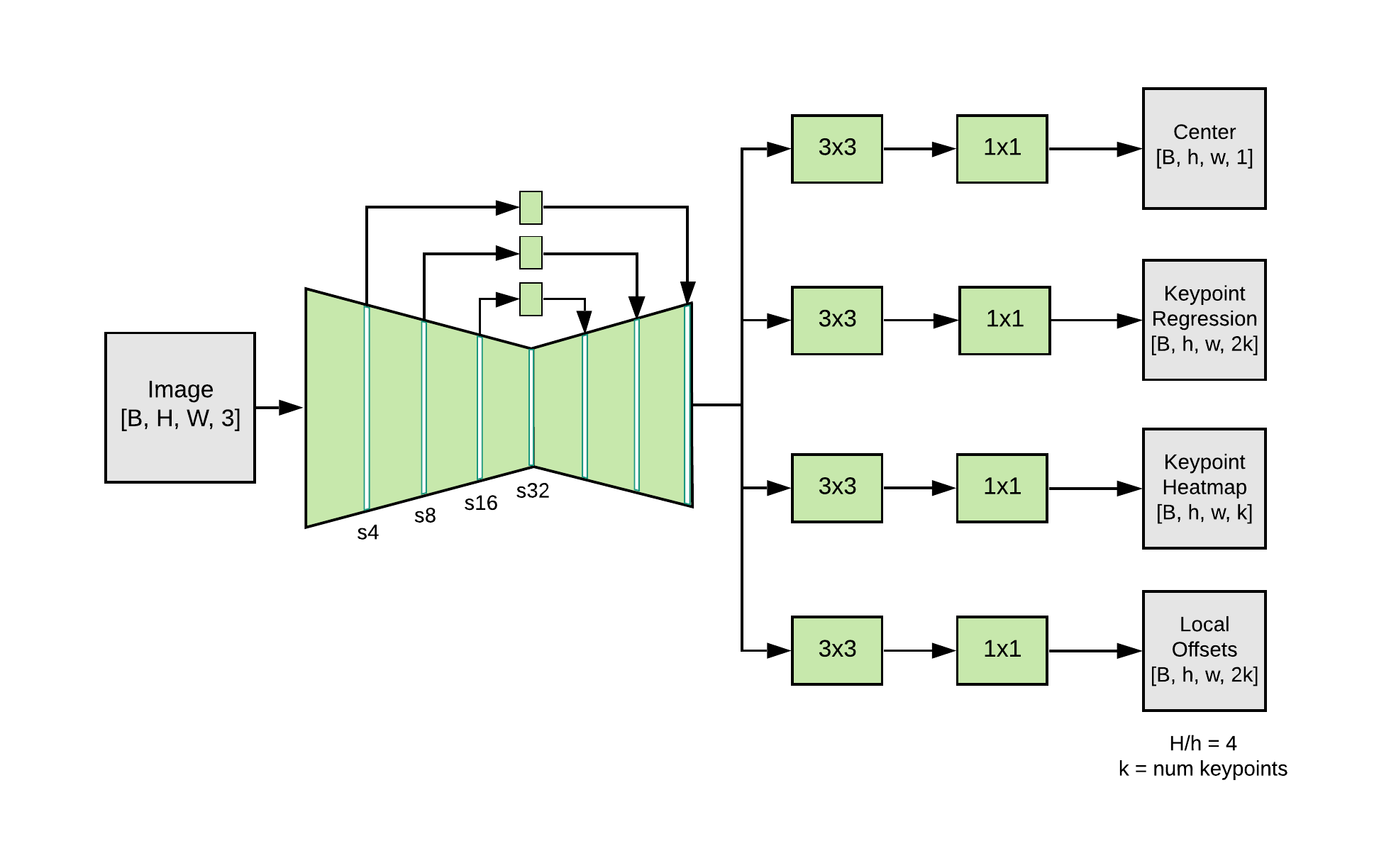
MoveNet is a bottom-up estimation model, using heatmaps to accurately localize human keypoints. The architecture consists of two components: a feature extractor and a set of prediction heads. The prediction scheme loosely follows CenterNet, with notable changes that improve both speed and accuracy. All models are trained using the TensorFlow Object Detection API.
The feature extractor in MoveNet is MobileNetV2 with an attached feature pyramid network (FPN), which allows for a high resolution (output stride 4), semantically rich feature map output. There are four prediction heads attached to the feature extractor, responsible for densely predicting a:
- Person center heatmap: predicts the geometric center of person instances
- Keypoint regression field: predicts full set of keypoints for a person, used for grouping keypoints into instances
- Person keypoint heatmap: predicts the location of all keypoints, independent of person instances
- 2D per-keypoint offset field: predicts local offsets from each output feature map pixel to the precise sub-pixel location of each keypoint
 |
| MoveNet architecture |
Although these predictions are computed in parallel, one can gain insight into the model’s operation by considering the following sequence of operations:
Step 1: The person center heatmap is used to identify the centers of all individuals in the frame, defined as the arithmetic mean of all keypoints belonging to a person. The location with the highest score (weighted by the inverse-distance from the frame center) is selected.
Step 2: An initial set of keypoints for the person is produced by slicing the keypoint regression output from the pixel corresponding to the object center. Since this is a center-out prediction – which must operate over different scales – the quality of regressed keypoints will not be very accurate.
Step 3: Each pixel in the keypoint heatmap is multiplied by a weight which is inversely proportional to the distance from the corresponding regressed keypoint. This ensures that we do not accept keypoints from background people, since they typically will not be in the proximity of regressed keypoints, and hence will have low resulting scores.
Step 4: The final set of keypoint predictions are selected by retrieving the coordinates of the maximum heatmap values in each keypoint channel. The local 2D offset predictions are then added to these coordinates to give refined estimates. See the figure below which illustrates these four steps.
 |
| MoveNet post-processing steps. |
Training Datasets
MoveNet was trained on two datasets: COCO and an internal Google dataset called Active. While COCO is the standard benchmark dataset for detection – due to its scene and scale diversity – it is not suitable for fitness and dance applications, which exhibit challenging poses and significant motion blur. Active was produced by labeling keypoints (adopting COCO’s standard 17 body keypoints) on yoga, fitness, and dance videos from YouTube. No more than three frames are selected from each video for training, to promote diversity of scenes and individuals.
Evaluations on the Active validation dataset show a significant performance boost relative to identical architectures trained using only COCO. This isn’t surprising since COCO infrequently exhibits individuals with extreme poses (e.g. yoga, pushups, headstands, and more).
To learn more about the dataset and how MoveNet performs across different categories, please see the model card.
 |
| Images from Active keypoint dataset. |
Optimization
While a lot of effort went into architecture design, post-processing logic, and data selection to make MoveNet a high-quality detector, an equal focus was given to inference speed. First, bottleneck layers from MobileNetV2 were selected for lateral connections in the FPN. Likewise, the number of convolution filters in each prediction head were slimmed down significantly to speed up execution on the output feature maps. Depthwise separable convolutions are used throughout the network, except in the first MobileNetV2 layer.
MoveNet was repeatedly profiled, uncovering and removing particularly slow ops. For example, we replaced tf.math.top_k with tf.math.argmax, since it executes significantly faster and is adequate for the single-person setting.
To ensure fast execution with TensorFlow.js, all model outputs were packed into a single output tensor, so that there is only one download from GPU to CPU.
Perhaps the most significant speedup is the use of 192×192 inputs to the model (256×256 for Thunder). To counteract the lower resolution, we apply intelligent cropping based on detections from the previous frame. This allows the model to devote its attention and resources to the main subject, and not the background.
Temporal Filtering
Operating on a high FPS camera stream provides the luxury of applying smoothing to keypoint estimates. Both Lightning and Thunder apply a robust, non-linear filter to the incoming stream of keypoint predictions. This filter is tuned to simultaneously suppress high-frequency noise (i.e. jitter) and outliers from the model, while also maintaining high-bandwidth throughput during quick motions. This leads to smooth keypoint visualizations with minimal lag in all circumstances.
MoveNet Browser Performance
To quantify the inference speed of MoveNet, the model was benchmarked across multiple devices. The model latency (expressed in FPS) was measured on GPU with WebGL, as well as WebAssembly (WASM), which is the typical backend for devices with lower-end or no GPUs.
|
MacBook Pro 15” 2019. Intel core i9. AMD Radeon Pro Vega 20 Graphics. (FPS) |
iPhone 12 (FPS) |
Pixel 5 (FPS) |
Desktop Intel i9-10900K. Nvidia GTX 1070 GPU. (FPS) |
|
|
WebGL |
104 | 77 |
51 | 43 |
34 | 12 |
87 | 82 |
|
WASM with SIMD + Multithread |
42 | 21 |
N/A |
N/A |
71 | 30 |
Inference speed of MoveNet across different devices and TF.js backends. The first number in each cell is for Lightning, and the second number is for Thunder.
TF.js continuously optimizes its backends to accelerate model execution across all supported devices. We applied several techniques here to help the models achieve this performance, such as implementing a packed WebGL kernel for the depthwise separable convolutions and improving GL scheduling for mobile Chrome.
To see the model’s FPS on your device, try our demo. You can switch the model type and backends live in the demo UI to see what works best for your device.
Looking Ahead
The next step is to extend Lightning and Thunder models to the multi-person domain, so that developers can support applications with multiple people in the camera field-of-view.
We also have plans to speed up the TensorFlow.js backends to make model execution even faster. This is achieved through repeated benchmarking and backend optimization.
Acknowledgements
We would like to acknowledge the other contributors to MoveNet: Yu-Hui Chen, Ard Oerlemans, Francois Belletti, Andrew Bunner, and Vijay Sundaram, along with those involved with the TensorFlow.js pose-detection API: Ping Yu, Sandeep Gupta, Jason Mayes, and Masoud Charkhabi.