
Posted by Zonglin Li, Lu Wang, Maxime Brénon, and Yuqi Li, Software Engineers
Today, we’re excited to announce a new on-device embedding-based search library that allows you to quickly find similar images, text or audio from millions of data samples in a few milliseconds.

It works by using a model to embed the search query into a high-dimensional vector representing the semantic meaning of the query. Then it uses ScaNN (Scalable Nearest Neighbors) to search for similar items from a predefined database. In order to apply it to your dataset, you need to use Model Maker Searcher API (vision/text) to build a custom TFLite Searcher model, and then deploy it onto devices using Task Library Searcher API (vision/text).
For example, with the Searcher model trained on COCO, searching the query, A passenger plane on the runway, will return the following images:
 |
| Figure 1: All images are from COCO 2014 train and validation datasets. Image 1 by Mark Jones Jr. under Attribution License. Image 2 by 305 Seahill under Attribution-NoDerivs License. Image 3 by tataquax under Attribution-ShareAlike License. |
- Train a dual encoder model for image and text query encoding using the COCO dataset.
- Create a text-to-image Searcher model using the Model Maker Searcher API.
- Retrieve images with text queries using the Task Library Searcher API.
Train a Dual Encoder Model
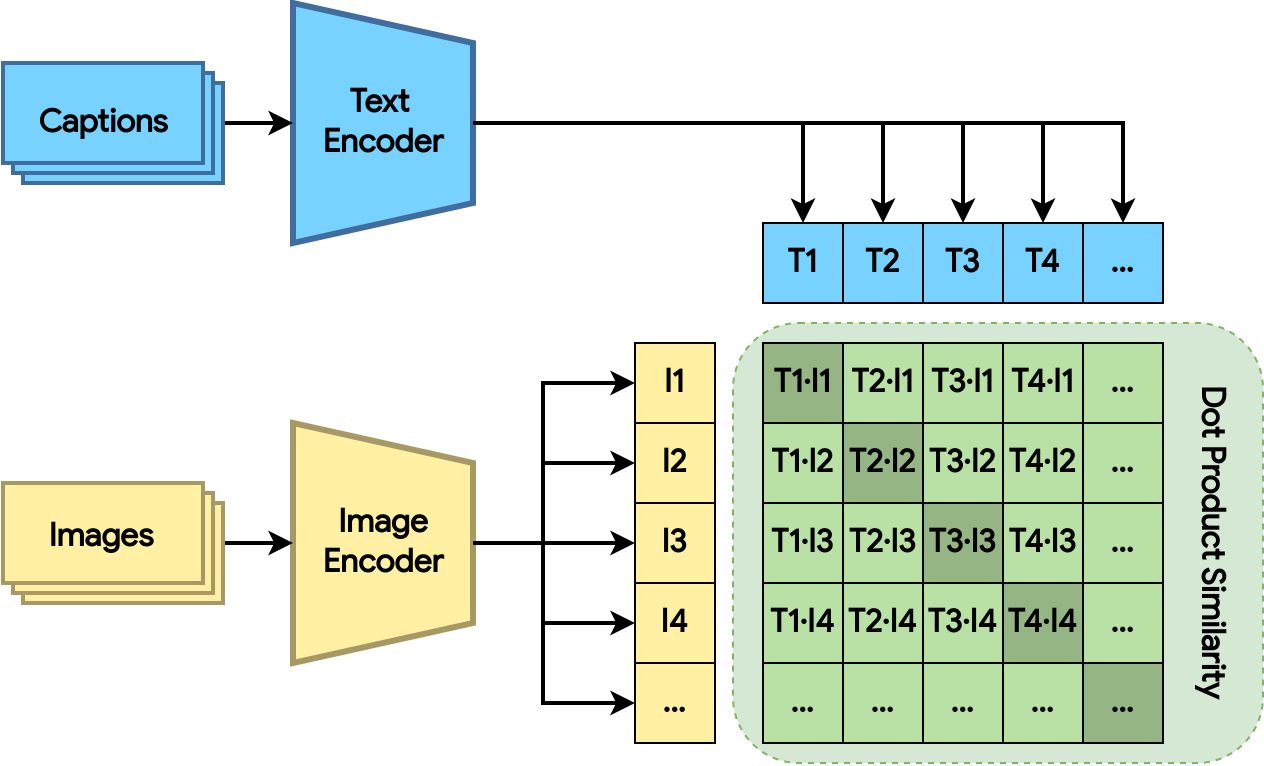 |
| Figure 2: Train the dual encoder model with dot product similarity distance. The loss encourages related images and text to have larger dot products (the shaded green squares). |
The dual encoder model consists of an image encoder and a text encoder. The two encoders map the images and text, respectively, to embeddings in a high-dimensional space. The model computes the dot product between the image and text embeddings, and the loss encourages relevant image and text to have larger dot product (closer), and unrelated ones to have smaller dot product (farther apart).
The training procedure is inspired by the CLIP paper and this Keras example. The image encoder is based on a pre-trained EfficientNet model and the text encoder is based on a pre-trained Universal Sentence Encoder model. The outputs from both encoders are then projected to a 128 dimensional space and are L2 normalized. For the dataset, we chose to use COCO, as its train and validation splits have human generated captions for each image. Please take a look at the companion Colab notebook for the details of the training process.
The dual encoder model makes it possible to retrieve images from a database without captions because once trained, the image embedder can directly extract the semantic meaning from the image without any need for human-generated captions.
Create the text-to-image Searcher model using Model Maker
 |
| Figure 3: Generate image embeddings using the image encoder and use Model Maker to create the TFLite Searcher model. |
Once the dual encoder model is trained, we can use it to create the TFLite Searcher model that searches for the most relevant images from an image dataset based on the text queries. This can be done by the following three steps:
- Generate the embeddings of the image dataset using the TensorFlow image encoder. ScaNN is capable of searching through a very large dataset, hence we combined the train and validation splits of COCO 2014 totaling 123K+ images to demonstrate its capabilities. See the code here.
- Convert the TensorFlow text encoder model into TFLite format. See the code here.
- Use Model Maker to create the TFLite Searcher model from the TFLite text encoder and the image embeddings using the code below:
# Configure ScaNN options. See the API doc for how to configure ScaNN.
scann_options = searcher.ScaNNOptions(
distance_measure='dot_product',
tree=searcher.Tree(num_leaves=351, num_leaves_to_search=4),
score_ah=searcher.ScoreAH(1, anisotropic_quantization_threshold=0.2))
# Load the image embeddings and corresponding metadata if any.
data = searcher.DataLoader(tflite_embedder_path, image_embeddings, metadata)
# Create the TFLite Searcher model.
model = searcher.Searcher.create_from_data(data, scann_options)
# Export the TFLite Searcher model.
model.export(
export_filename='searcher.tflite',
userinfo='',
export_format=searcher.ExportFormat.TFLITE)
When creating the Searcher model, Model Maker leverages ScaNN to index the embedding vectors. The embedding dataset is first partitioned into multiple subsets. In each of the subsets, ScaNN stores the quantized representation of the embedding vectors. At retrieval time, ScaNN selects a few most relevant partitions and scores the quantized representations with fast, approximate distances. This procedure saves both the model size (through quantization) and achieves speed up (through partition selection). See the in-depth examination to learn more about the ScaNN algorithm.
In the above example, we divide the dataset into 351 partitions (roughly the square root of the number of embeddings we have), and search 4 of them during retrieval, which is roughly 1% of the dataset. We also quantize the 128 dimensional float embeddings to 128 int8 values to save space.
Run inference using Task Library
 |
| Figure 4: Run inference using Task Library with the TFLite Searcher model. It takes the query text and returns the top neighbor’s metadata. From there we can find the corresponding images. |
To query images using the Searcher model, you only need a couple of lines of code like the following using Task Library:
from tflite_support.task import text
# Initialize a TextSearcher object
searcher = text.TextSearcher.create_from_file('searcher.tflite')
# Search the input query
results = searcher.search(query_text)
# Show the results
for rank in range(len(results.nearest_neighbors)):
print('Rank #', rank, ':')
image_id = results.nearest_neighbors[rank].metadata
print('image_id: ', image_id)
print('distance: ', results.nearest_neighbors[rank].distance)
show_image_by_id(image_id)Try the code from the Colab. Also, see more information on how to integrate the model using the Task Library Java and C++ API, especially on Android. Each query in general takes only 6 milliseconds on Pixel 6.
Here are some example results:
Query: A man riding a bike
Results are ranked according to the approximate similarity distance. Here is a sample of retrieved images. Note that we are only showing images if their licenses allow.
 |
| Figure 5: All images are from COCO 2014 train and validation datasets. Image 1 by Reuel Mark Delez under Attribution License. Image 2 by Richard Masoner / Cyclelicious under Attribution-ShareAlike License. Image 3 by Julia under Attribution-ShareAlike License. Image 4 by Aaron Fulkerson under Attribution-ShareAlike License. Image 5 by Richard Masoner / Cyclelicious under Attribution-ShareAlike License. Image 6 by Richard Masoner / Cyclelicious under Attribution-ShareAlike License. |
Future work
We’ll be working on enabling more search types beyond image and text, such as audio clips.
Contact odml-pipelines-team@google.com if you want to leave any feedback. Our goal is to make on-device ML even easier for you and we value your input!
In this post, we will walk you through an end-to-end example of building a text-to-image search feature (retrieve the images given textual queries) using the new TensorFlow Lite Searcher Library. Here are the major steps:
Acknowledgements
We would like to thank Khanh LeViet, Chuo-Ling Chang, Ruiqi Guo, Lawrence Chan, Laurence Moroney, Yu-Cheng Ling, Matthias Grundmann, as well as Robby Neale, Chung-Ching Chang, Tom Small and Khalid Salama for their active support of this work. We would also like to thank the entire ScaNN team: David Simcha, Erik Lindgren, Felix Chern, Phil Sun and Sanjiv Kumar.