This is a guest post co-authored by Taylor Names, Staff Machine Learning Engineer, Dev Gupta, Machine Learning Manager, and Argie Angeleas, Senior Product Manager at Ibotta. Ibotta is an American technology company that enables users with its desktop and mobile apps to earn cash back on in-store, mobile app, and online purchases with receipt submission, linked retailer loyalty accounts, payments, and purchase verification.
Ibotta strives to recommend personalized promotions to better retain and engage its users. However, promotions and user preferences are constantly evolving. This ever-changing environment with many new users and new promotions is a typical cold start problem—there is no sufficient historical user and promotion interactions to draw any inferences from. Reinforcement learning (RL) is an area of machine learning (ML) concerned with how intelligent agents should take action in an environment in order to maximize the notion of cumulative rewards. RL focuses on finding a balance between exploring uncharted territory and exploiting current knowledge. Multi-armed bandit (MAB) is a classic reinforcement learning problem that exemplifies the exploration/exploitation tradeoff: maximizing reward in the short-term (exploitation) while sacrificing the short-term reward for knowledge that can increase rewards in the long term (exploration). A MAB algorithm explores and exploits optimal recommendations for the user.
Ibotta collaborated with the Amazon Machine Learning Solutions Lab to use MAB algorithms to increase user engagement when the user and promotion information is highly dynamic.
We selected a contextual MAB algorithm because it’s effective in the following use cases:
- Making personalized recommendations according to users’ state (context)
- Dealing with cold start aspects such as new bonuses and new customers
- Accommodating recommendations where users’ preferences change over time
Data
To increase bonus redemptions, Ibotta desires to send personalized bonuses to customers. Bonuses are Ibotta’s self-funded cash incentives, which serve as the actions of the contextual multi-armed bandit model.
The bandit model uses two sets of features:
- Action features – These describe the actions, such as bonus type and average amount of the bonus
- Customer features – These describe customers’ historical preferences and interactions, such as past weeks’ redemptions, clicks, and views
The contextual features are derived from historical customer journeys, which contained 26 weekly activity metrics generated from users’ interactions with the Ibotta app.
Contextual multi-armed bandit
Bandit is a framework for sequential decision-making in which the decision-maker sequentially chooses an action, potentially based on the current contextual information, and observes a reward signal.
We set up the contextual multi-armed bandit workflow on Amazon SageMaker using the built-in Vowpal Wabbit (VW) container. SageMaker helps data scientists and developers prepare, build, train, and deploy high-quality ML models quickly by bringing together a broad set of capabilities purpose-built for ML. The model training and testing are based on offline experimentation. The bandit learns user preferences based on their feedback from past interactions rather than a live environment. The algorithm can switch to production mode, where SageMaker remains as the supporting infrastructure.
To implement the exploration/exploitation strategy, we built the iterative training and deployment system that performs the following actions:
- Recommends an action using the contextual bandit model based on user context
- Captures the implicit feedback over time
- Continuously trains the model with incremental interaction data
The workflow of the client application is as follows:
- The client application picks a context, which is sent to the SageMaker endpoint to retrieve an action.
- The SageMaker endpoint returns an action, associated bonus redemption probability, and
event_id. - Because this simulator was generated using historical interactions, the model knows the true class for that context. If the agent selects an action with redemption, the reward is 1. Otherwise, the agent obtains a reward of 0.
In the case where historical data is available and is in the format of <state, action, action probability, reward>, Ibotta can warm start a live model by learning the policy offline. Otherwise, Ibotta can initiate a random policy for day 1 and start to learn a bandit policy from there.
The following is the code snippet to train the model:
Model performance
We randomly split the redeemed interactions as training data (10,000 interactions) and evaluation data (5,300 holdout interactions).
Evaluation metrics are the mean reward, where 1 indicates the recommended action was redeemed, and 0 indicates the recommended action didn’t get redeemed.
We can determine the mean reward as follows:
Mean reward (redeem rate) = (# of recomended actions with redemption)/(total # recommended actions)
The following table shows the mean reward result:
| Mean Reward | Uniform Random Recommendation | Contextual MAB-based Recommendation |
| Train | 11.44% | 56.44% |
| Test | 10.69% | 59.09% |
The following figure plots the incremental performance evaluation during training, where the x-axis is the number of records learned by the model and the y-axis is the incremental mean reward. The blue line indicates the multi-armed bandit; the orange line indicates random recommendations.
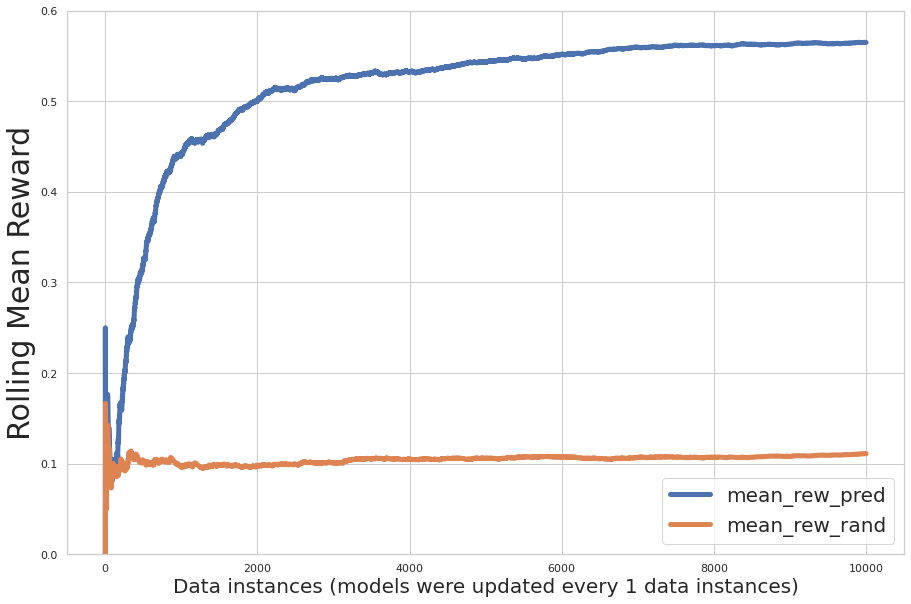
The graph shows that the predicted mean reward increases over the iterations, and the predicted action reward is significantly greater than the random assignment of actions.
We can use previously trained models as warm starts and batch retrain the model with new data. In this case, model performance already converged through initial training. No significant additional performance improvement was observed in new batch retraining, as shown in the following figure.

We also compared contextual bandit with uniformly random and posterior random (random recommendation using historical user preference distribution as warm start) policies. The results are listed and plotted as follows:
- Bandit – 59.09% mean reward (training 56.44%)
- Uniform random – 10.69% mean reward (training 11.44%)
- Posterior probability random – 34.21% mean reward (training 34.82%)
The contextual multi-armed bandit algorithm outperformed the other two policies significantly.

Summary
The Amazon ML Solutions Lab collaborated with Ibotta to develop a contextual bandit reinforcement learning recommendation solution using a SageMaker RL container.
This solution demonstrated a steady incremental redemption rate lift over random (five-times lift) and non-contextual RL (two-times lift) recommendations based on an offline test. With this solution, Ibotta can establish a dynamic user-centric recommendation engine to optimize customer engagement. Compared to random recommendation, the solution improved recommendation accuracy (mean reward) from 11% to 59%, according to the offline test. Ibotta plans to integrate this solution into more personalization use cases.
“The Amazon ML Solutions Lab worked closely with Ibotta’s Machine Learning team to build a dynamic bonus recommendation engine to increase redemptions and optimize customer engagement. We created a recommendation engine leveraging reinforcement learning that learns and adapts to the ever-changing customer state and cold starts new bonuses automatically. Within 2 months, the ML Solutions Lab scientists developed a contextual multi-armed bandit reinforcement learning solution using a SageMaker RL container. The contextual RL solution showed a steady increase in redemption rates, achieving a five-times lift in bonus redemption rate over random recommendation, and a two-times lift over a non-contextual RL solution. The recommendation accuracy improved from 11% using random recommendation to 59% using the ML Solutions Lab solution. Given the effectiveness and flexibility of this solution, we plan to integrate this solution into more Ibotta personalization use cases to further our mission of making every purchase rewarding for our users.”
– Heather Shannon, Senior Vice President of Engineering & Data at Ibotta.
About the Authors
 Taylor Names is a staff machine learning engineer at Ibotta, focusing on content personalization and real-time demand forecasting. Prior to joining Ibotta, Taylor led machine learning teams in the IoT and clean energy spaces.
Taylor Names is a staff machine learning engineer at Ibotta, focusing on content personalization and real-time demand forecasting. Prior to joining Ibotta, Taylor led machine learning teams in the IoT and clean energy spaces.
 Dev Gupta is an engineering manager at Ibotta Inc, where he leads the machine learning team. The ML team at Ibotta is tasked with providing high-quality ML software, such as recommenders, forecasters, and internal ML tools. Before joining Ibotta, Dev worked at Predikto Inc, a machine learning startup, and The Home Depot. He graduated from the University of Florida.
Dev Gupta is an engineering manager at Ibotta Inc, where he leads the machine learning team. The ML team at Ibotta is tasked with providing high-quality ML software, such as recommenders, forecasters, and internal ML tools. Before joining Ibotta, Dev worked at Predikto Inc, a machine learning startup, and The Home Depot. He graduated from the University of Florida.
 Argie Angeleas is a Senior Product Manager at Ibotta, where he leads the Machine Learning and Browser Extension squads. Before joining Ibotta, Argie worked as Director of Product at iReportsource. Argie obtained his PhD in Computer Science and Engineering from Wright State University.
Argie Angeleas is a Senior Product Manager at Ibotta, where he leads the Machine Learning and Browser Extension squads. Before joining Ibotta, Argie worked as Director of Product at iReportsource. Argie obtained his PhD in Computer Science and Engineering from Wright State University.
 Fang Wang is a Senior Research Scientist at the Amazon Machine Learning Solutions Lab, where she leads the Retail Vertical, working with AWS customers across various industries to solve their ML problems. Before joining AWS, Fang worked as Sr. Director of Data Science at Anthem, leading the medical claim processing AI platform. She obtained her master’s in Statistics from the University of Chicago.
Fang Wang is a Senior Research Scientist at the Amazon Machine Learning Solutions Lab, where she leads the Retail Vertical, working with AWS customers across various industries to solve their ML problems. Before joining AWS, Fang worked as Sr. Director of Data Science at Anthem, leading the medical claim processing AI platform. She obtained her master’s in Statistics from the University of Chicago.
 Xin Chen is a senior manager at the Amazon Machine Learning Solutions Lab, where he leads the Central US, Greater China Region, LATAM, and Automotive Vertical. He helps AWS customers across different industries identify and build machine learning solutions to address their organization’s highest return-on-investment machine learning opportunities. Xin obtained his PhD in Computer Science and Engineering from the University of Notre Dame.
Xin Chen is a senior manager at the Amazon Machine Learning Solutions Lab, where he leads the Central US, Greater China Region, LATAM, and Automotive Vertical. He helps AWS customers across different industries identify and build machine learning solutions to address their organization’s highest return-on-investment machine learning opportunities. Xin obtained his PhD in Computer Science and Engineering from the University of Notre Dame.
 Raj Biswas is a Data Scientist at the Amazon Machine Learning Solutions Lab. He helps AWS customers develop ML-powered solutions across diverse industry verticals for their most pressing business challenges. Prior to joining AWS, he was a graduate student at Columbia University in Data Science.
Raj Biswas is a Data Scientist at the Amazon Machine Learning Solutions Lab. He helps AWS customers develop ML-powered solutions across diverse industry verticals for their most pressing business challenges. Prior to joining AWS, he was a graduate student at Columbia University in Data Science.
 Xinghua Liang is an Applied Scientist at the Amazon Machine Learning Solutions Lab, where he works with customers across various industries, including manufacturing and automotive, and helps them to accelerate their AI and cloud adoption. Xinghua obtained his PhD in Engineering from Carnegie Mellon University.
Xinghua Liang is an Applied Scientist at the Amazon Machine Learning Solutions Lab, where he works with customers across various industries, including manufacturing and automotive, and helps them to accelerate their AI and cloud adoption. Xinghua obtained his PhD in Engineering from Carnegie Mellon University.
 Yi Liu is an applied scientist with Amazon Customer Service. She is passionate about using the power of ML/AI to optimize user experience for Amazon customers and help AWS customers build scalable cloud solutions. Her science work in Amazon spans membership engagement, online recommendation system, and customer experience defect identification and resolution. Outside of work, Yi enjoys traveling and exploring nature with her dog.
Yi Liu is an applied scientist with Amazon Customer Service. She is passionate about using the power of ML/AI to optimize user experience for Amazon customers and help AWS customers build scalable cloud solutions. Her science work in Amazon spans membership engagement, online recommendation system, and customer experience defect identification and resolution. Outside of work, Yi enjoys traveling and exploring nature with her dog.