New generations of CPUs offer significant performance improvement in machine learning (ML) inference due to specialized built-in instructions. Combined with their flexibility, high speed of development, and low operating cost, these general-purpose processors offer an alternative ML inference solution to other existing hardware solutions.
AWS, Arm, Meta, and others helped optimize the performance of PyTorch 2.0 inference for Arm-based processors. As a result, we are delighted to announce that Arm-based AWS Graviton instance inference performance for PyTorch 2.0 is up to 3.5 times the speed for ResNet-50 compared to the previous PyTorch release, and up to 1.4 times the speed for BERT, making Graviton-based instances the fastest compute optimized instances on AWS for these models (see the following graph).
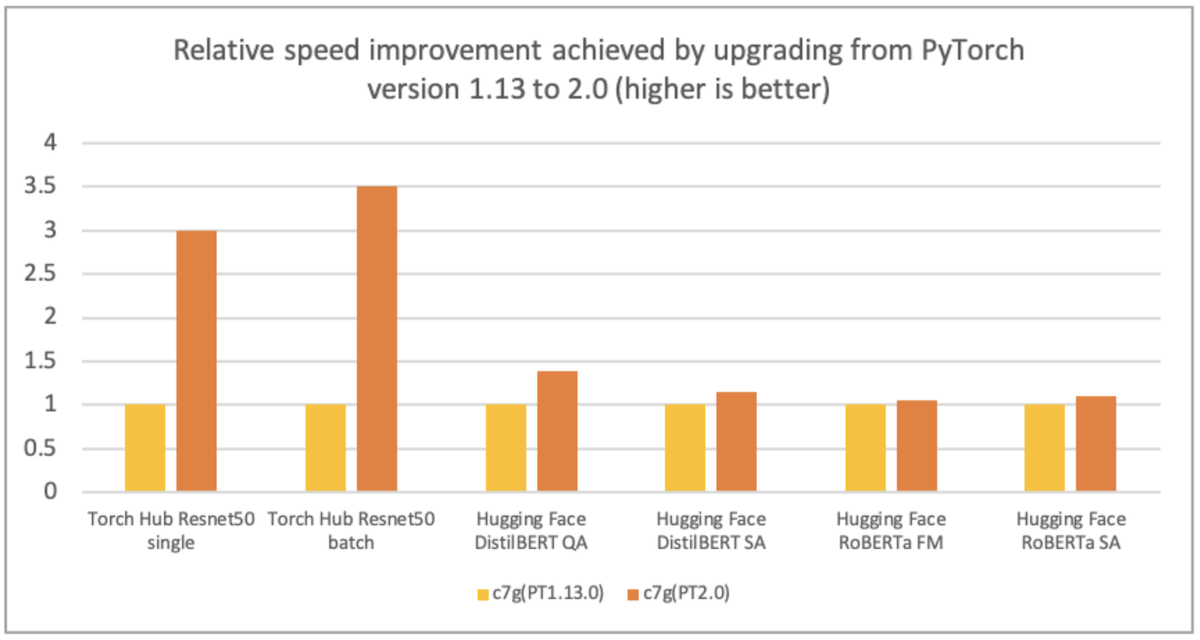
Image 1: Relative speed improvement achieved by upgrading from PyTorch version 1.13 to 2.0 (higher is better). The performance is measured on c7g.4xlarge instances.
As shown in the next graph, we measured up to 50% cost savings for PyTorch inference with Graviton3-based c7g instances across Torch Hub ResNet-50 and multiple Hugging Face models compared to comparable x86-based compute optimized Amazon EC2 instances. For that graph, we first measured the cost per million inference for the five instance types. Then, we normalized the cost per million inference results to a c5.4xlarge instance, which is the baseline measure of “1” on the Y-axis of the chart.
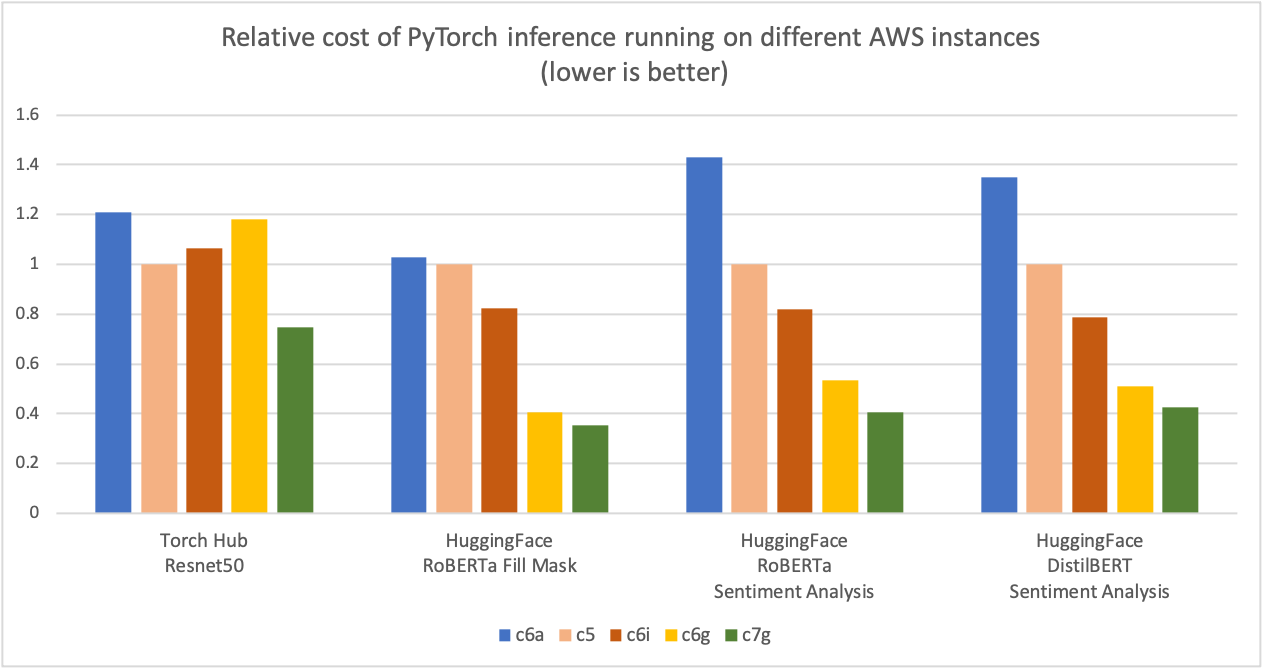
Image 2: Relative cost of PyTorch inference running on different AWS instances (lower is better).
Source: AWS ML Blog on Graviton PyTorch2.0 inference performance.
Similar to the preceding inference cost comparison graph, the following graph shows the model p90 latency for the same five instance types. We normalized the latency results to the c5.4xlarge instance, which is the baseline measure of “1” on the Y-axis of the chart. The c7g.4xlarge (AWS Graviton3) model inference latency is up to 50% better than the latencies measured on c5.4xlarge, c6i.4xlarge, and c6a.4xlarge.
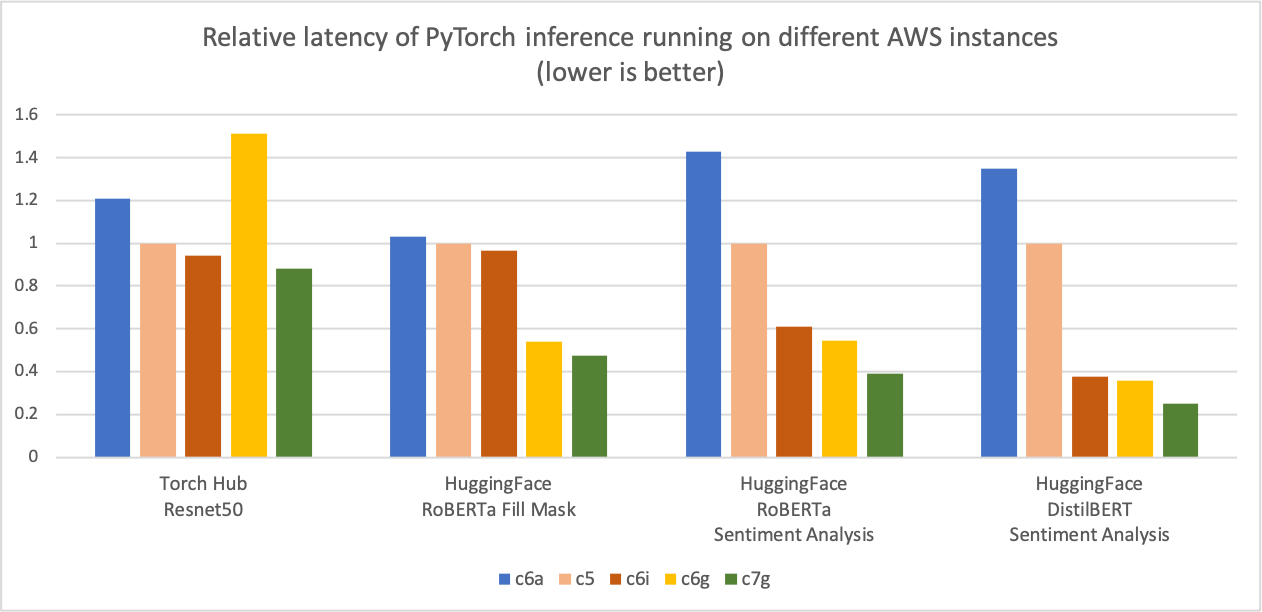
Image 3: Relative latency (p90) of PyTorch inference running on different AWS instances (lower is better).
Source: AWS ML Blog on Graviton PyTorch2.0 inference performance.
Optimization details
PyTorch supports Compute Library for the Arm® Architecture (ACL) GEMM kernels via the oneDNN backend (previously called “MKL-DNN”) for AArch64 platforms. The optimizations are primarily for PyTorch ATen CPU BLAS, ACL kernels for fp32 and bfloat16, and oneDNN primitive caching. There are no frontend API changes, so no changes are required at the application level to get these optimizations working on Graviton3-based instances.
PyTorch level optimizations
We extended the ATen CPU BLAS interface to accelerate more operators and tensor configurations via oneDNN backend for aarch64 platform. The following diagram highlights (in orange) the optimized components that improved the PyTorch inference performance on aarch64 platform.
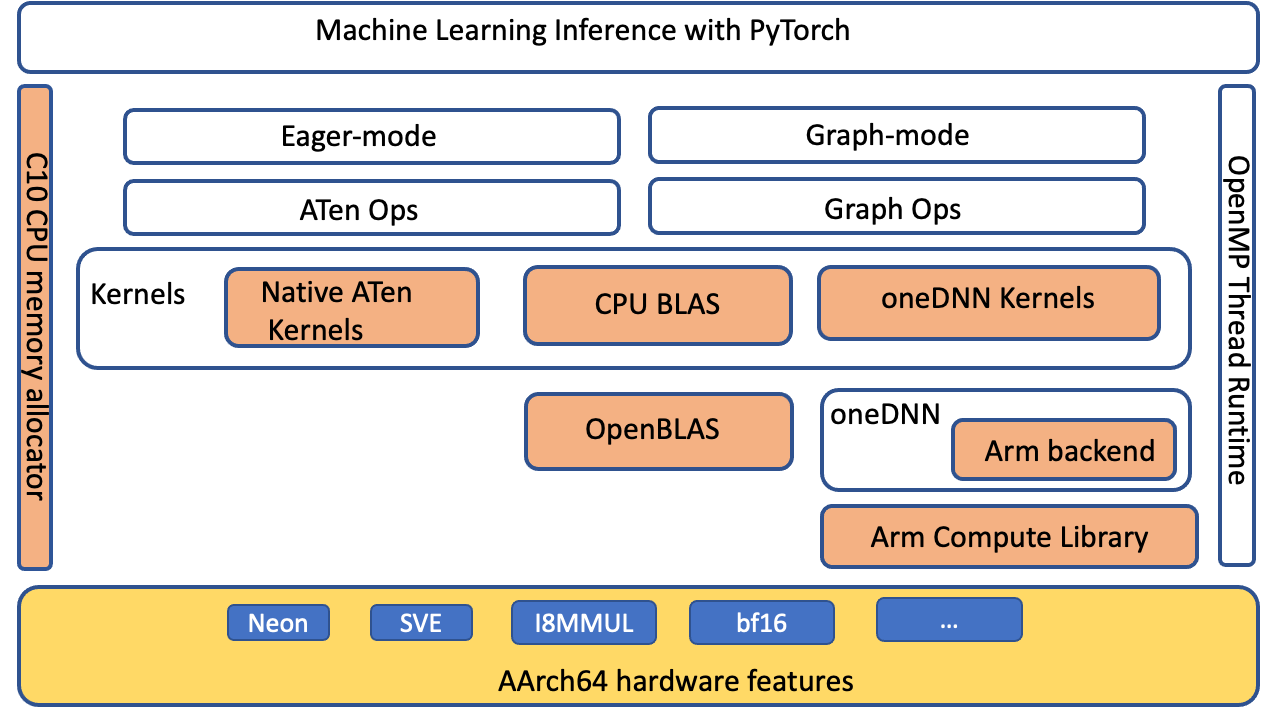
Image 4: PyTorch software stack highlighting (in orange) the components optimized for inference performance improvement on AArch64 platform
ACL kernels and BFloat16 FPmath mode
The ACL library provides Neon and SVE optimized GEMM kernels for both fp32 and bfloat16 formats: These kernels improve the SIMD hardware utilization and reduce the end to end inference latencies. The bfloat16 support in Graviton3 allows efficient deployment of models trained using bfloat16, fp32 and Automatic Mixed Precision (AMP). The standard fp32 models use bfloat16 kernels via oneDNN FPmath mode without model quantization. They provide up to two times faster performance compared to existing fp32 model inference without bfloat16 FPmath support. For more details on ACL GEMM kernel support, refer to Arm Compute Library github.
Primitive Caching
The following call sequence diagram shows how ACL operators are integrated into oneDNN backend. As shown in the diagram, ACL objects are handled as oneDNN resources instead of the primitive objects. This is because the ACL objects are stateful and mutable. Since the ACL objects are handled as resource objects, they are not cacheable with the default primitive caching feature supported in oneDNN. We implemented primitive caching at ideep operator level for “convolution”, “matmul” and “inner product” operators to avoid redundant GEMM kernel initialization and tensor allocation overhead.
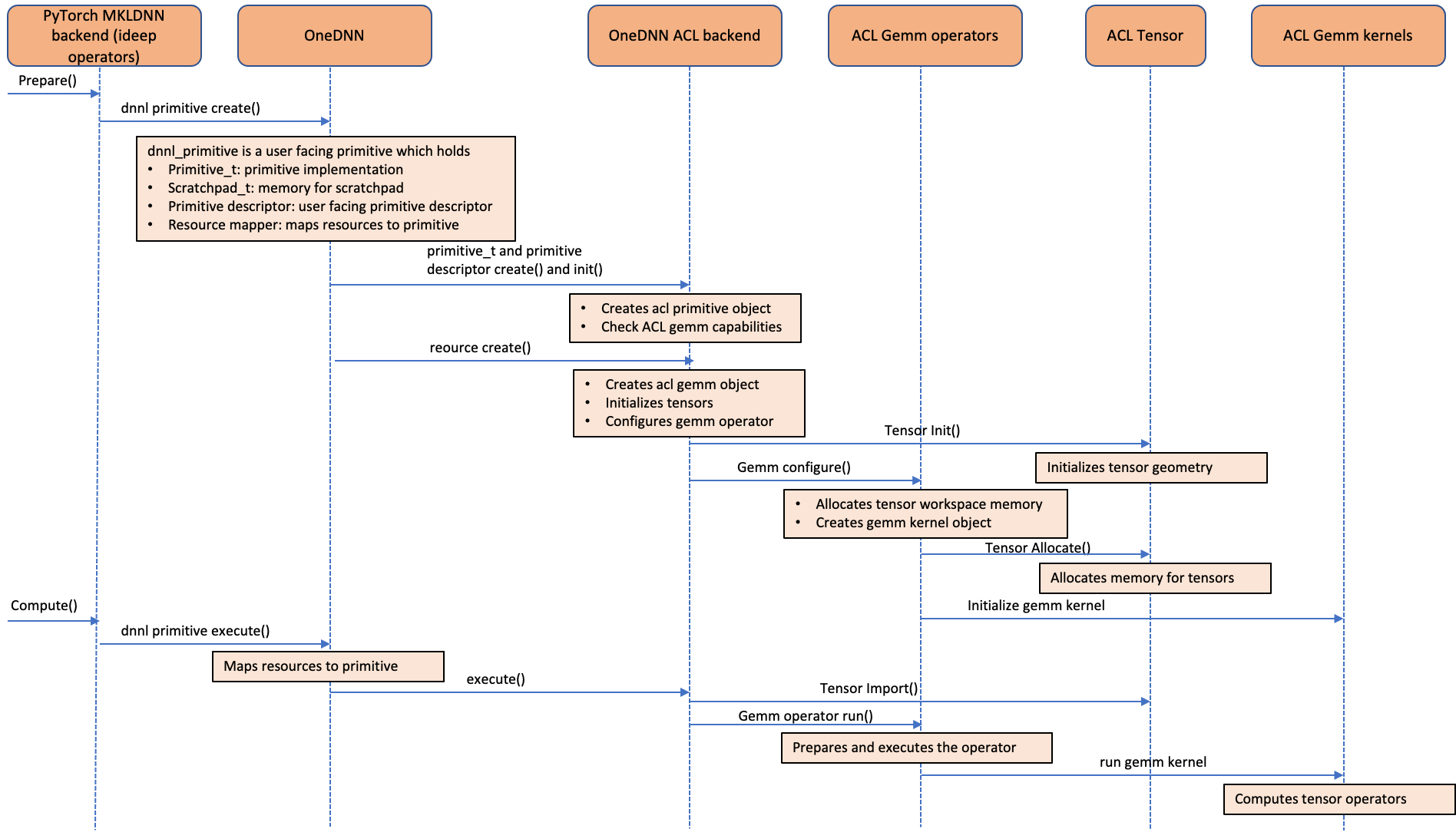
Image 5: Call sequence diagram showing how the Compute Library for the Arm® Architecture (ACL) GEMM kernels are integrated into oneDNN backend
How to take advantage of the optimizations
Install the PyTorch 2.0 wheel from the official repo and set environment variables to enable the additional optimizations.
# Install Python
sudo apt-get update
sudo apt-get install -y python3 python3-pip
# Upgrade pip3 to the latest version
python3 -m pip install --upgrade pip
# Install PyTorch and extensions
python3 -m pip install torch
python3 -m pip install torchvision torchaudio torchtext
# Turn on Graviton3 optimization
export DNNL_DEFAULT_FPMATH_MODE=BF16
export LRU_CACHE_CAPACITY=1024
Running an inference
You can use PyTorch torchbench to measure the CPU inference performance improvements, or to compare different instance types.
# Pre-requisite:
# pip install PyTorch2.0 wheels and set the above mentioned environment variables
# Clone PyTorch benchmark repo
git clone https://github.com/pytorch/benchmark.git
# Setup ResNet-50 benchmark
cd benchmark
python3 install.py resnet50
# Install the dependent wheels
python3 -m pip install numba
# Run ResNet-50 inference in jit mode. On successful completion of the inference runs,
# the script prints the inference latency and accuracy results
python3 run.py resnet50 -d cpu -m jit -t eval --use_cosine_similarity
Performance Analysis
Now, we will analyze the inference performance of ResNet-50 on Graviton3-based c7g instance using PyTorch profiler. We run the code below with PyTorch 1.13 and PyTorch 2.0 and run the inference for a few iterations as a warmup before measuring the performance.
# Turn on Graviton3 optimization
export DNNL_DEFAULT_FPMATH_MODE=BF16
export LRU_CACHE_CAPACITY=1024
import torch
from torchvision import models
sample_input = [torch.rand(1, 3, 224, 224)]
eager_model = models.resnet50(weights=models.ResNet50_Weights.DEFAULT)
model = torch.jit.script(eager_model, example_inputs=[sample_input, ])
model = model.eval()
model = torch.jit.optimize_for_inference(model)
with torch.no_grad():
# warmup runs
for i in range(10):
model(*sample_input)
prof = torch.profiler.profile(
on_trace_ready=torch.profiler.tensorboard_trace_handler('./logs'), record_shapes=True, with_stack=True)
# profile after warmup
prof.start()
model(*sample_input)
prof.stop()
We use tensorboard to view results of the profiler and analyze model performance.
Install PyTorch Profiler Tensorboard plugin as follows
pip install torch_tb_profiler
Launch the tensorboard using
tensorboard --logdir=./logs
Launch the following in the browser to view the profiler output. The profiler supports ‘Overview’, ‘Operator’, ‘Trace’ and ‘Module’ views to get insight into the inference execution.
http://localhost:6006/#pytorch_profiler
The following diagram is the profiler ‘Trace’ view which shows the call stack along with the execution time of each function. In the profiler, we selected the forward() function to get the overall inference time. As shown in the diagram, the inference time for the ResNet-50 model on Graviton3-based c7g instance is around 3 times faster in PyTorch 2.0 compared to PyTorch 1.13.
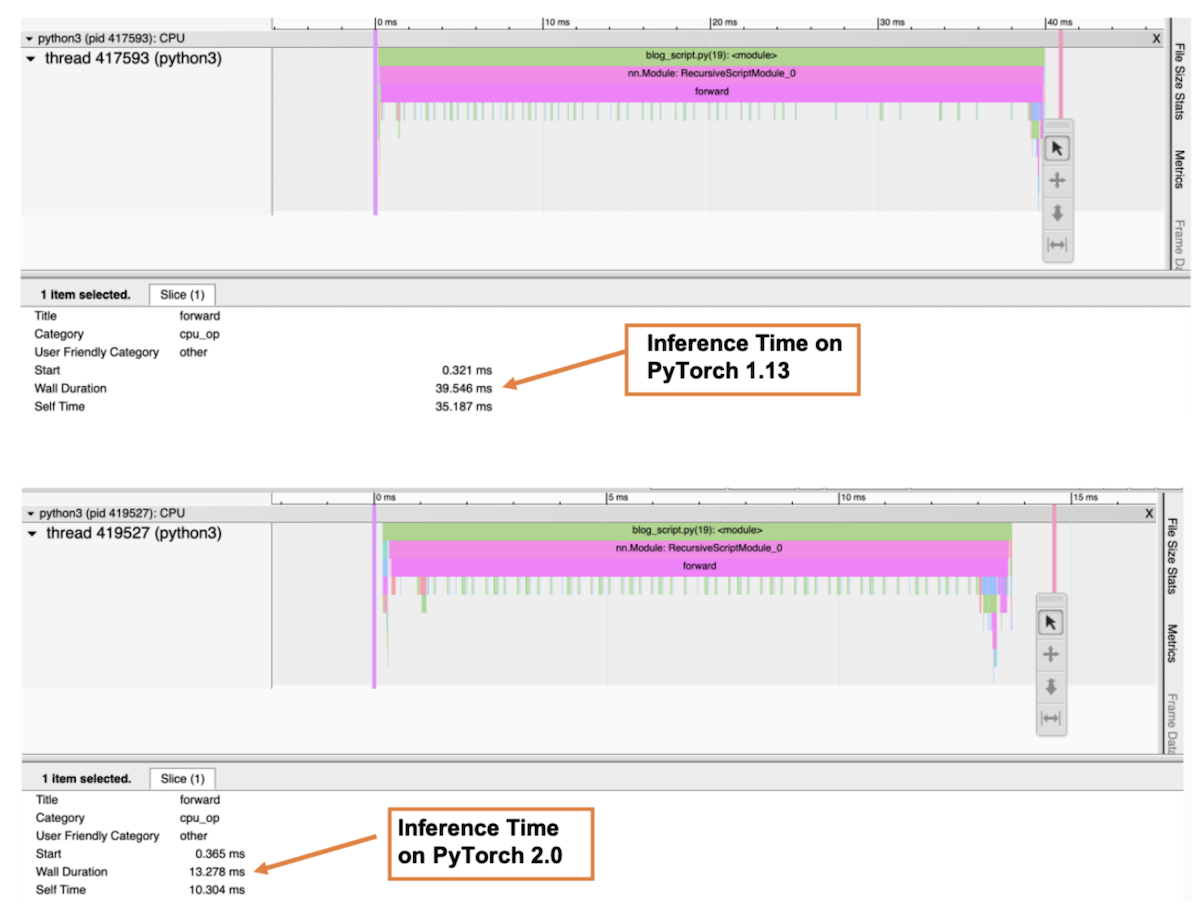
Image 6: Profiler Trace view: Forward pass wall duration on PyTorch 1.13 and PyTorch 2.0
The next diagram is the ‘Operator’ view which shows the list of PyTorch operators and their execution time. Similar to the preceding Trace view, the Operator view shows that the operator host duration for the ResNet-50 model on Graviton3-based c7g instance is around 3 times faster in PyTorch 2.0 compared to PyTorch 1.13.
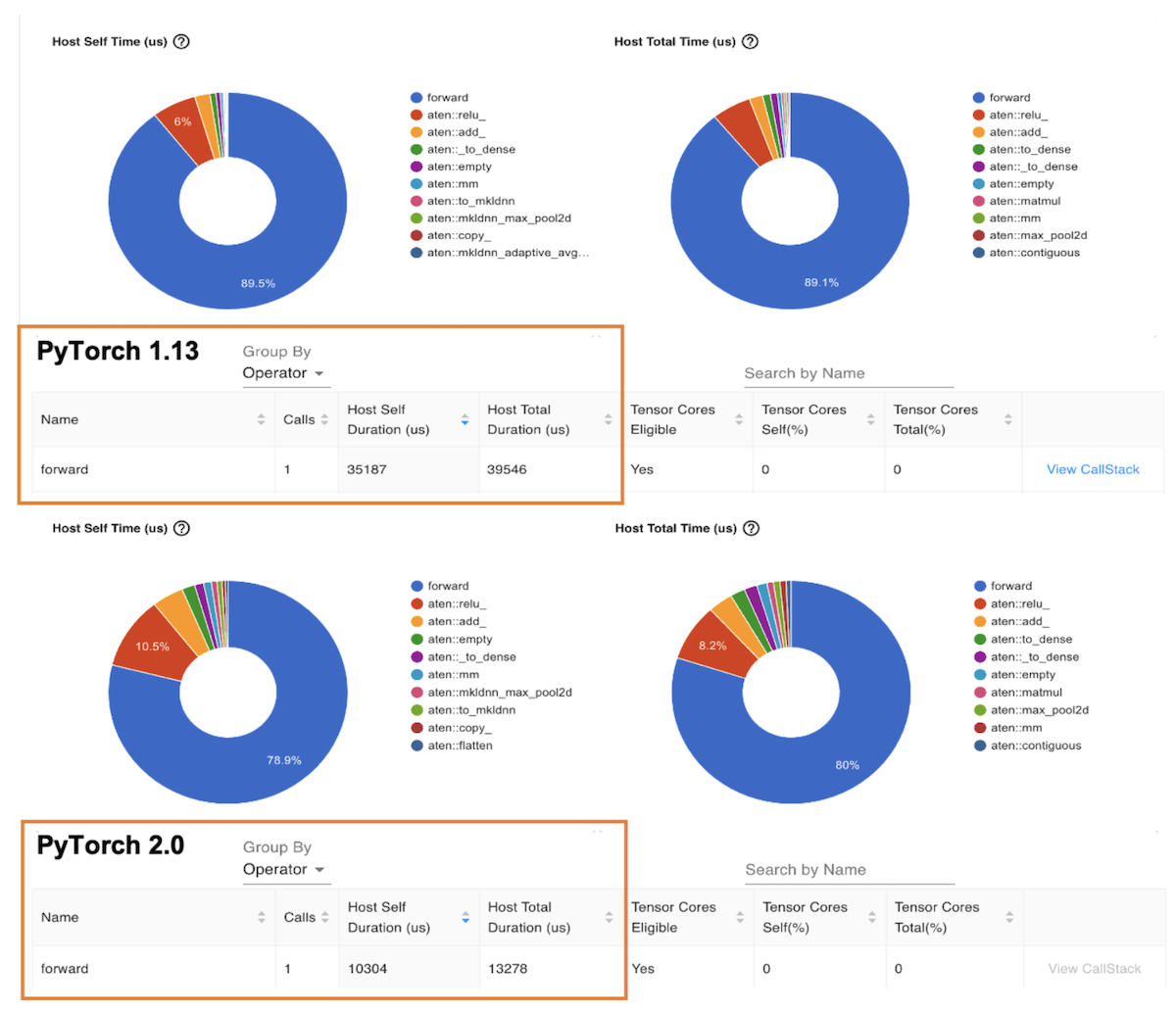
Image 7: Profiler Operator view: Forward operator Host duration on PyTorch 1.13 and PyTorch 2.0
Benchmarking Hugging Face models
You can use the Amazon SageMaker Inference Recommender utility to automate performance benchmarking across different instances. With Inference Recommender, you can find the real-time inference endpoint that delivers the best performance at the lowest cost for a given ML model. We collected the preceding data using the Inference Recommender notebooks by deploying the models on production endpoints. For more details on Inference Recommender, refer to the amazon-sagemaker-examples GitHub repo. We benchmarked the following models for this post: ResNet50 image classification, DistilBERT sentiment analysis, RoBERTa fill mask, and RoBERTa sentiment analysis.
Conclusion
For PyTorch 2.0, the Graviton3-based C7g instance is the most cost-effective compute optimized Amazon EC2 instance for inference. These instances are available on SageMaker and Amazon EC2. The AWS Graviton Technical Guide provides the list of optimized libraries and best practices that will help you achieve cost benefit with Graviton instances across different workloads.
If you find use cases where similar performance gains are not observed on Graviton, please open an issue on the aws-graviton-getting-started github to let us know about it. We will continue to add more performance improvements to make AWS Graviton-based instances the most cost-effective and efficient general purpose processor for inference using PyTorch.
Acknowledgments
We would like to thank Ali Saidi (Sr. Principal Engineer) and Csaba Csoma (Sr. Manager, Software Development) from AWS, Ashok Bhat (Sr. Product Manager), Nathan Sircombe (Sr. Engineering Manager) and Milos Puzovic (Principal Software Engineer) from Arm for their support during the Graviton PyTorch inference optimization work. We would also like to thank Geeta Chauhan (Engineering Leader, Applied AI) from Meta for her guidance on this blog.
About the authors
Sunita Nadampalli is a ML Engineer and Software Development Manager at AWS.
Ankith Gunapal is an AI Partner Engineer at Meta(PyTorch).