Posted by Juhyun Lee and Yury Pisarchyk, Software Engineers
Running inference on mobile and embedded devices is challenging due to tight resource constraints; one has to work with limited hardware under strict power requirements. In this article, we want to showcase improvements in TensorFlow Lite’s (TFLite) memory usage that make it even better for running inference at the edge.
Intermediate Tensors
Typically, a neural network can be thought of as a computational graph consisting of operators, such as CONV_2D or FULLY_CONNECTED, and tensors holding the intermediate computation results, called intermediate tensors. These intermediate tensors are typically pre-allocated to reduce the inference latency at the cost of memory space. However, this cost, when implemented naively, can’t be taken lightly in a resource-constrained environment; it can take up a significant amount of space, sometimes even several times larger than the model itself. For example, the intermediate tensors in MobileNet v2 take up 26MB memory (Figure 1) which is about twice as large as the model itself.
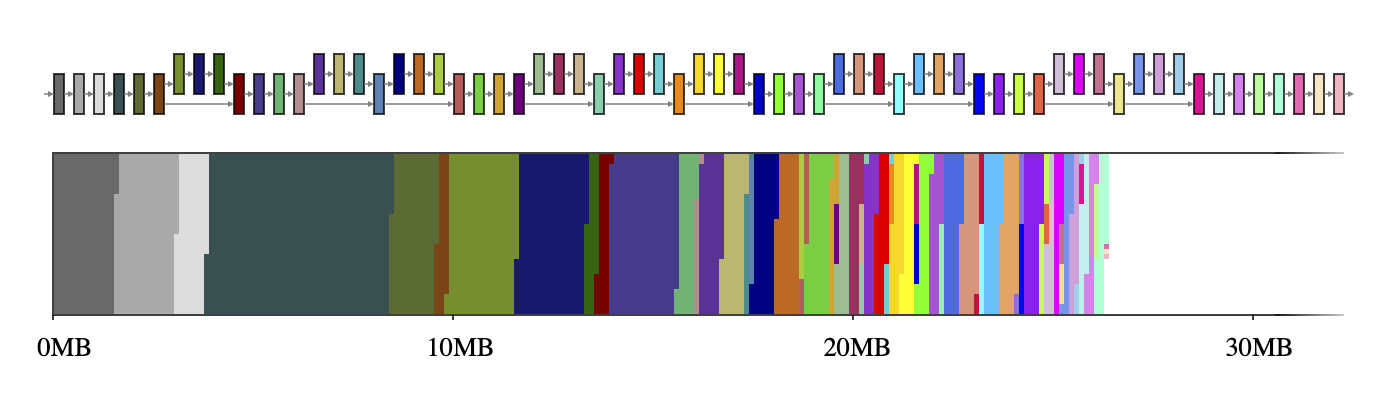 |
| Figure 1. The intermediate tensors of MobileNet v2 (top) and a mapping of their sizes onto a 2D memory space (bottom). If each intermediate tensor uses a dedicated memory buffer (depicted with 65 distinct colors), they take up ~26MB of runtime memory. |
The good news is that these intermediate tensors don’t have to co-exist in memory thanks to data dependency analysis. This allows us to reuse the memory buffers of the intermediate tensors and reduce the total memory footprint of the inference engine. If the network has the shape of a simple chain, two large memory buffers are sufficient as they can be swapped back and forth interchangeably throughout the network. However, for arbitrary networks forming complicated graphs, this NP-complete resource allocation problem requires a good approximation algorithm.
We have devised a number of different approximation algorithms for this problem, and they all perform differently depending on the neural network and the properties of memory buffers, but they all use one thing in common: tensor usage records. A tensor usage record of an intermediate tensor is an auxiliary data structure that contains information about how big the tensor is and when it is used for the first and the last time in a given execution plan of the network. With the help of these records, the memory manager is able to compute the intermediate tensor usages at any moment in the network’s execution and optimize its runtime memory for the smallest footprint possible.
Shared Memory Buffer Objects
In TFLite GPU OpenGL backend, we employ GL textures for these intermediate tensors. These come with a couple of interesting restrictions: (a) A texture’s size can’t be modified after its creation, and (b) only one shader program gets exclusive access to the texture object at a given time. In this Shared Memory Buffer Objects mode, the objective is to minimize the sum of the sizes of all created shared memory buffer objects in the object pool. This optimization is similar to the well-known register allocation problem, except that it’s much more complicated due to the variable size of each object.
With the aforementioned tensor usage records, we have devised 5 different algorithms as shown in Table 1. Except for Min-Cost Flow, they are greedy algorithms, each using a different heuristic, but still reaching or getting very close to the theoretical lower bound. Some algorithms perform better than others depending on the network topology, but in general, GREEDY_BY_SIZE_IMPROVED and GREEDY_BY_BREADTH produce the object assignments with the smallest memory footprint.
 |
| Table 1. Memory footprint of Shared Objects strategies (in MB; best results highlighted in green). The first 5 rows are our strategies, and the last 2 serve as a baseline (Lower Bound denotes an approximation of the best number possible which may not be achievable, and Naive denotes the worst number possible with each intermediate tensor assigned its own memory buffer). |
Coming back to our opening example, GREEDY_BY_BREADTH performs best on MobileNet v2 which leverages each operator’s breadth, i.e. the sum of all tensors in the operator’s profile. Figure 2, especially when compared to Figure 1, highlights how big of a gain one can get when employing a smart memory manager.
 |
| Figure 2. The intermediate tensors of MobileNet v2 (top) and a mapping of their sizes onto a 2D memory space (bottom). If the intermediate tensors share memory buffers (depicted with 4 distinct colors), they only take up ~7MB of runtime memory. |
Memory Offset Calculation
For TFLite running on the CPU, the memory buffer properties applicable to GL textures don’t apply. Thus, it is more common to allocate a huge memory arena upfront and have it shared among all readers and writers which access it by a given offset that does not interfere with other read and writes. The objective in this Memory Offset Calculation approach is to minimize the size of the memory arena.
We have devised 3 different algorithms for this optimization problem and have also explored prior work (Strip Packing by Sekiyama et al. 2018). Similar to the Shared Objects approach, some algorithms perform better than others depending on the network as shown in Table 2. One takeaway from this investigation is that the Offset Calculation approach has a smaller footprint than the Shared Objects approach in general, and thus, one should prefer the former over the latter if applicable.
 |
| Table 2. Memory footprint of Offset Calculation strategies (in MB; best results highlighted in green). The first 3 rows are our strategies, the next 1 is prior work, and the last 2 serve as baseline (Lower Bound denotes an approximation of the best number possible which may not be achievable, and Naive denotes the worst number possible with each intermediate tensor assigned its own memory buffer). |
These memory optimizations, for both CPU and GPU, have shipped by default with the last few stable TFLite releases, and have proven valuable in supporting more demanding, state-of-the-art models like MobileBERT. You can find more details about the implementation by looking at the GPU implementation and CPU implementation directly.
Acknowledgements
Matthias Grundmann, Jared Duke, Sarah Sirajuddin, and special thanks to Andrei Kulik for initial brainstorming and Terry Heo for the final implementation in TFLite.