Alexander Goldberg, Ivan Stelmakh, Kyunghyun Cho, Alice Oh, Alekh Agarwal, Danielle Belgrave, and Nihar Shah
Is it possible to reliably evaluate the quality of peer reviews? We study peer reviewing of peer reviews driven by two primary motivations:
(i) Incentivizing reviewers to provide high-quality reviews is an important open problem. The ability to reliably assess the quality of reviews can help design such incentive mechanisms.
(ii) Many experiments in the peer-review processes of various scientific fields use evaluations of reviews as a “gold standard” for investigating policies and interventions. The reliability of such experiments depends on the accuracy of these review evaluations.
We conducted a large-scale study at the NeurIPS 2022 conference in which we invited participants to evaluate reviews given to submitted papers. The evaluators of any review comprised other reviewers for that paper, the meta reviewer, authors of the paper, and reviewers with relevant expertise who were not assigned to review that paper. Each evaluator was provided the complete review along with the associated paper. The evaluation of any review was based on four specified criteria—comprehension, thoroughness, justification, and helpfulness—using a 5-point Likert scale, accompanied by an overall score on a 7-point scale, where a higher score indicates superior quality.
(1) Uselessly elongated review bias
We examined potential biases due to the length of reviews. We generated uselessly elongated versions of reviews by adding substantial amounts of non-informative content. Elongated because we made the reviews 2.5x–3x as long. Useless because the elongation did not provide any useful information: we added filler text, replicated the summary in another part of the review, replicated the abstract in the summary, replicated the drop-down menus in the review text.
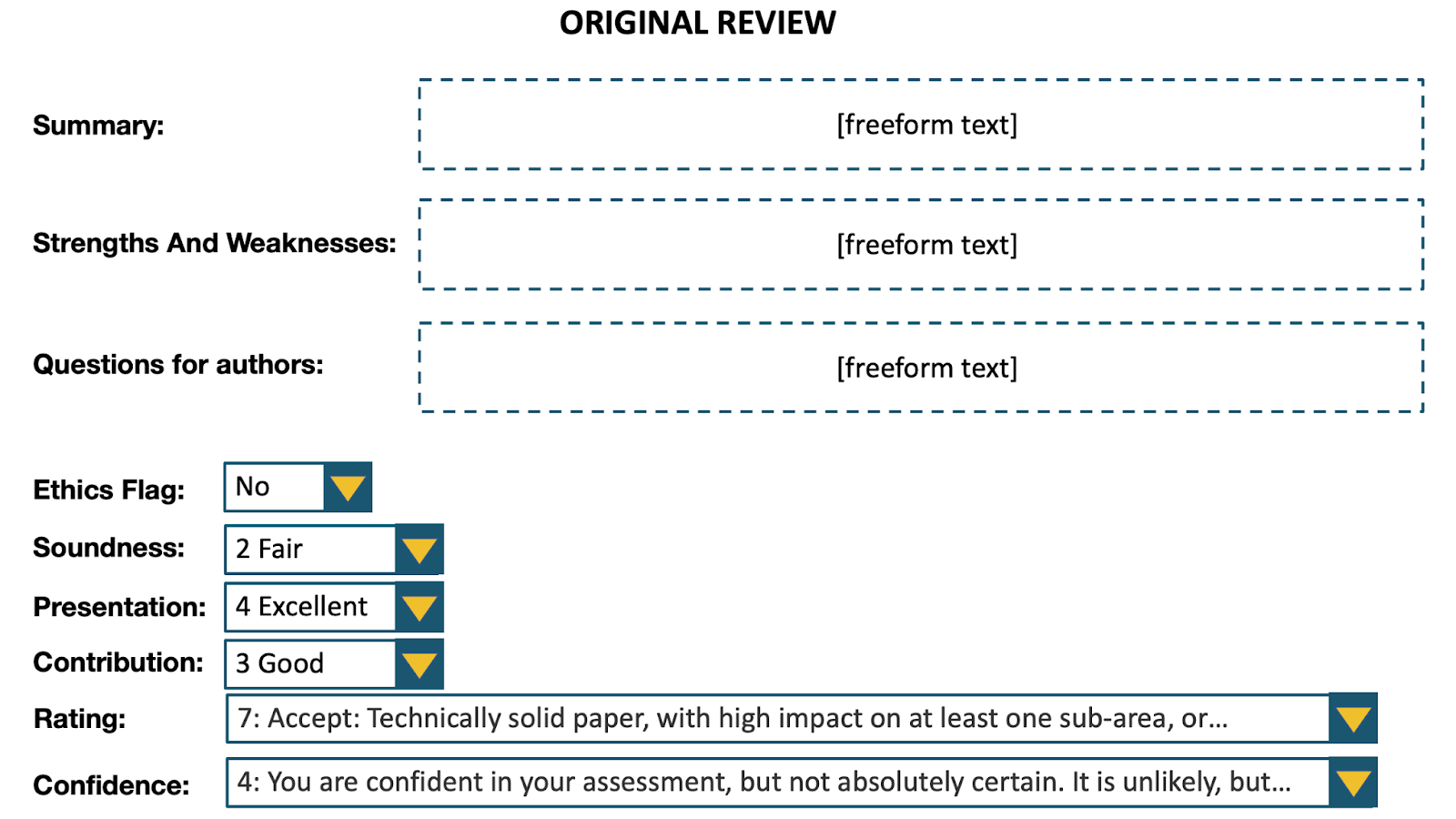
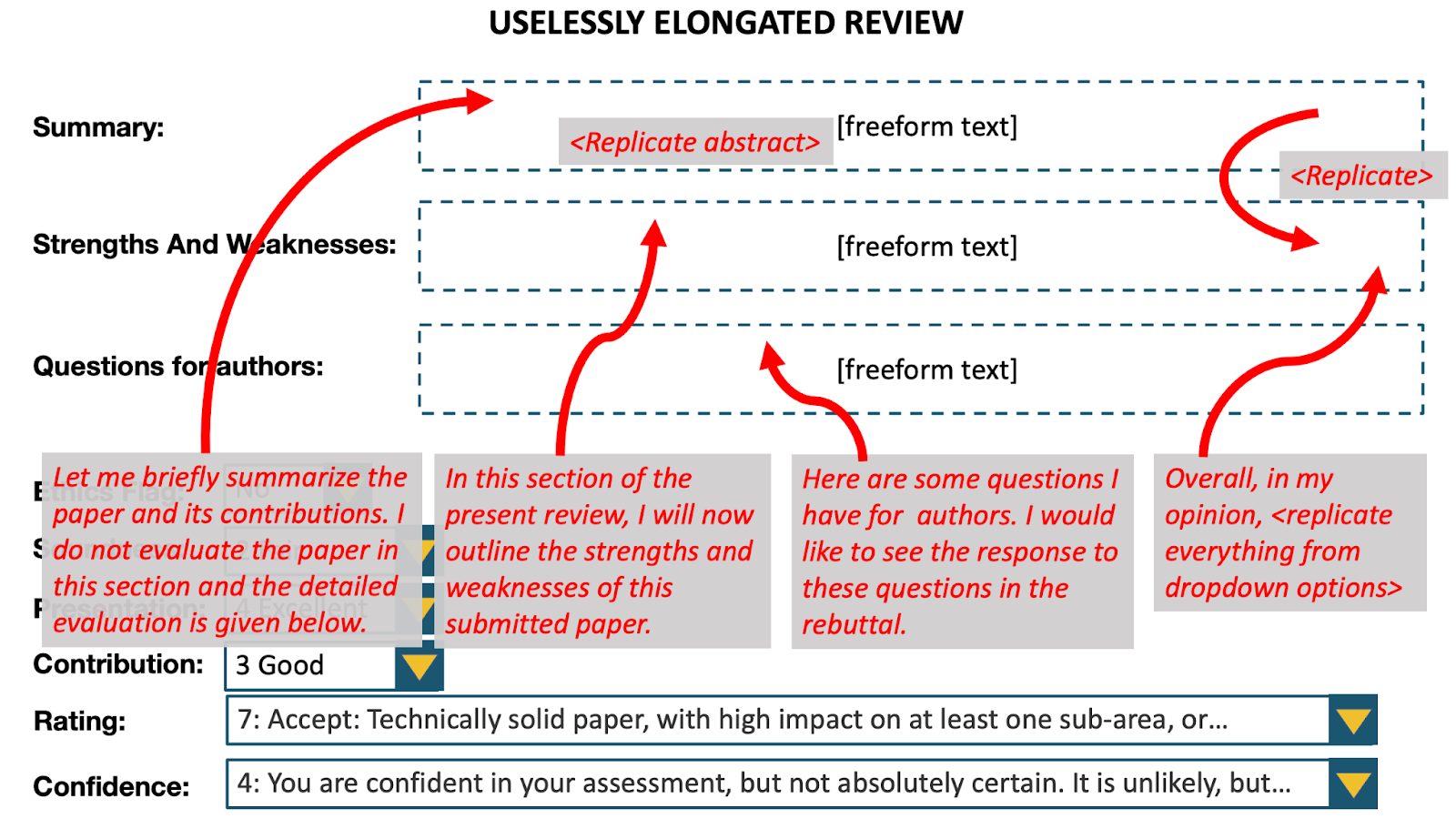
We conducted a randomized controlled trial, in which each evaluator was shown either the original review or the uselessly elongated version at random along with the associated paper. The evaluators comprised reviewers in the research area of the paper who were not originally assigned the paper. In the results shown below, we employ the Mann-Whitney U test, and the test statistic can be interpreted as the probability that a randomly chosen elongated review is rated higher than a randomly chosen original review. The test reveals significant evidence of bias in favor of longer reviews.
| Criteria | Test statistic | 95% CI | P-value | Difference in mean scores |
|---|---|---|---|---|
| Overall score | 0.64 | [0.60, 0.69] | < 0.0001 | 0.56 |
| Understanding | 0.57 | [0.53, 0.62] | 0.04 | 0.25 |
| Coverage | 0.71 | [0.66, 0.76] | <0.0001 | 0.83 |
| Substantiation | 0.59 | [0.54, 0.64] | 0.001 | 0.31 |
| Constructiveness | 0.60 | [0.55, 0.64] | 0.001 | 0.37 |
(2) Author-outcome bias
The graphs below depict the review score given to a paper by a reviewer on the x axis, plotted against the evaluation score for that review by evaluators on the y axis.
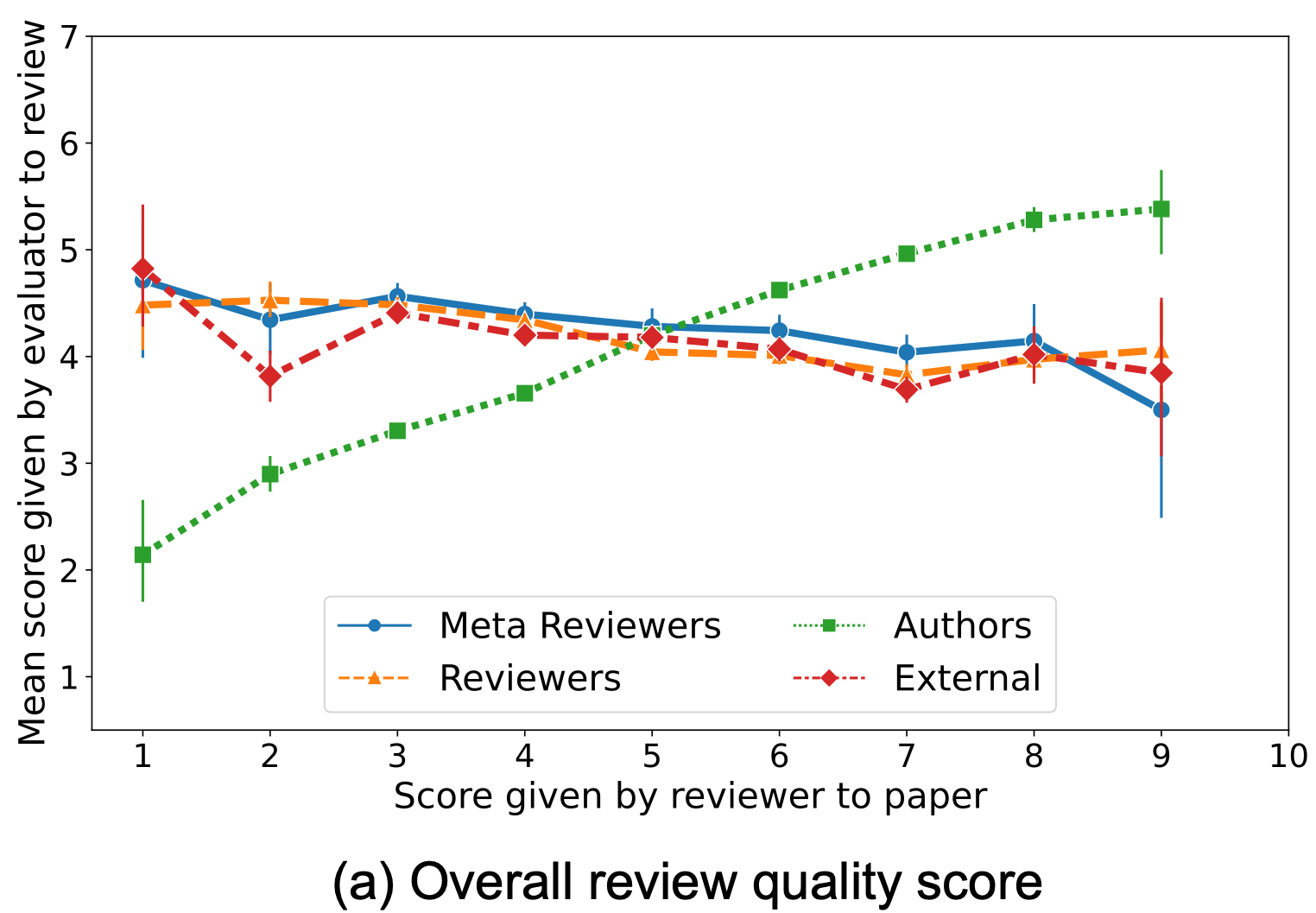
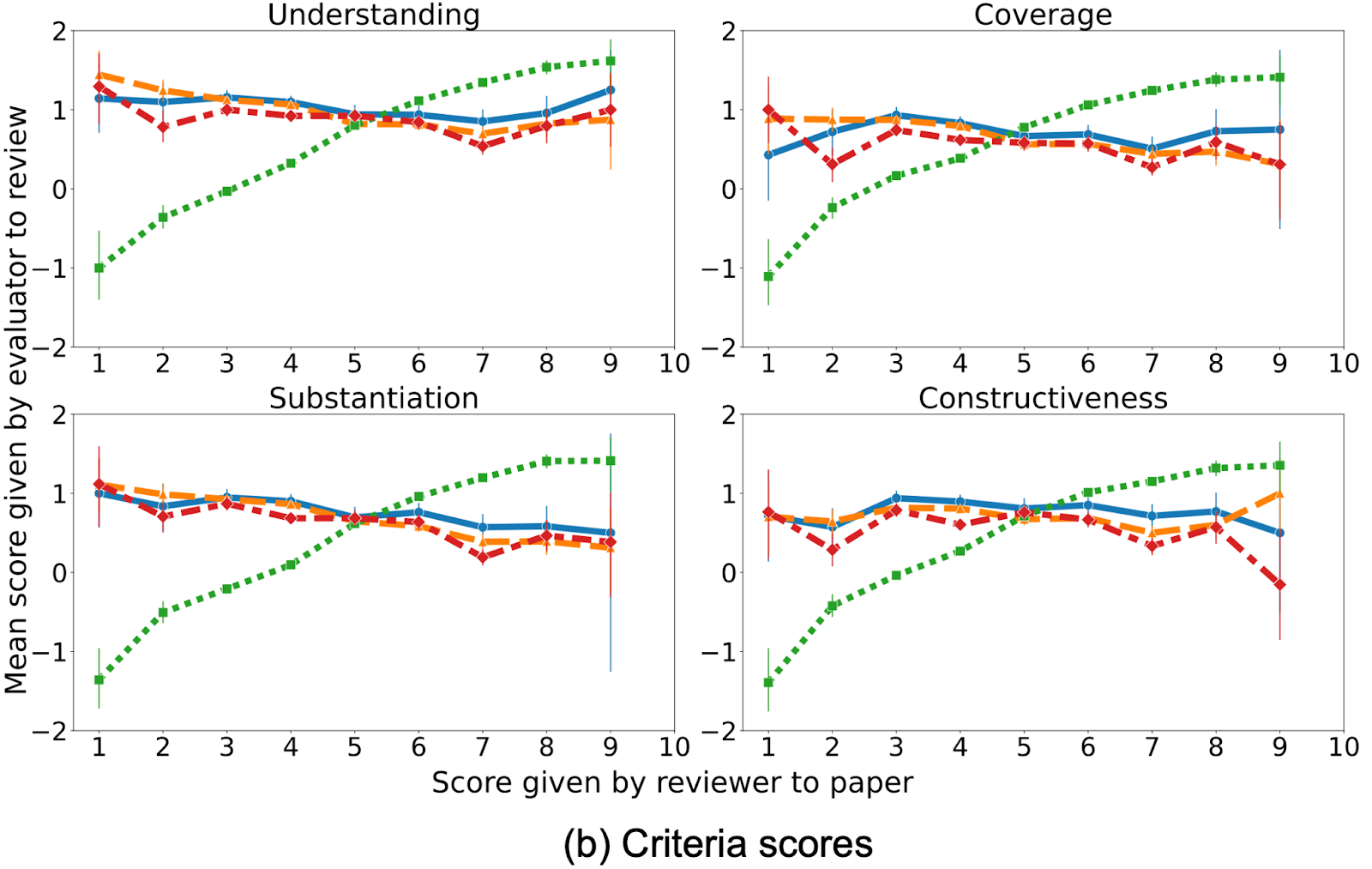
We see that authors’ evaluations of reviews are much more positive towards reviews recommending acceptance of their own papers, and negative towards reviews recommending rejection. In contrast, evaluations of reviews by other evaluators show little dependence on the score given by the review to the paper. We formally test for this bias of authors’ evaluations of reviews on the scores their papers received. Our analysis compares authors’ evaluations of reviews that recommended acceptance versus rejection of their paper, controlling for the review length, quality of review (as measured by others’ evaluations), and different numbers of accepted/rejected papers per author. The test reveals significant evidence of this bias.
| Criteria | Test statistic | 95% CI | P-value | Difference in mean scores |
|---|---|---|---|---|
| Overall score | 0.82 | [0.79, 0.85] | < 0.0001 | 1.41 |
| Understanding | 0.78 | [0.75, 0.81] | < 0.0001 | 1.12 |
| Coverage | 0.76 | [0.72, 0.79] | <0.0001 | 0.97 |
| Substantiation | 0.80 | [0.76, 0.83] | < 0.0001 | 1.28 |
| Constructiveness | 0.77 | [0.74, 0.80] | < 0.0001 | 1.15 |
(3) Inter-evaluator (dis)agreement
We measure the disagreement rates between multiple evaluations of the same review as follows. Take any pair of evaluators and any pair of reviews that receives an evaluation from both evaluators. We say the pair of evaluators agrees on this pair of reviews if both score the same review higher than the other; we say that this pair disagrees if the review scored higher by one evaluator is scored lower by the other. Ties are discarded.
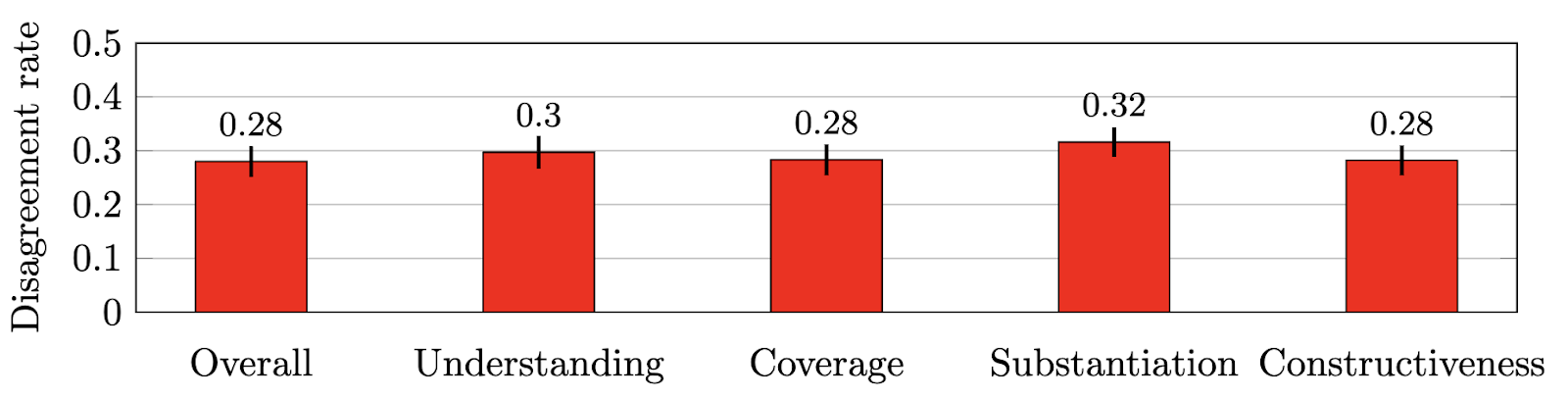
Interestingly, the rate of disagreement between reviews of papers measured in NeurIPS 2016 was in a similar range — 0.25 to 0.3.
(4) Miscalibration
Miscalibration refers to the phenomenon that reviewers have different strictness or leniency standards. We assess the amount of miscalibration of evaluators of reviews following the miscalibration analysis procedure for NeurIPS 2014 paper review data. This analysis uses a linear model of quality scores, assumes a Gaussian prior on the miscalibration of each reviewer, and the estimated variance of this prior then represents the magnitude of miscalibration. The analysis finds that the amount of miscalibration in evaluations of the reviews (in NeurIPS 2022) is higher than the reported amount of miscalibration in reviews of papers in NeurIPS 2014.
(5) Subjectivity
We evaluate a key source of subjectivity in reviews—commensuration bias—where different evaluators differently map individual criteria to overall scores. Our approach is to first learn a mapping from criteria scores to overall scores that best fits the collection of all reviews. We then compute the amount of subjectivity as the average difference between the overall scores given in the reviews and the respective overall scores determined by the learned mapping. Following previously derived theory, we use the L(1,1) norm as the loss. We find that the amount of subjectivity in the evaluation of reviews at NeurIPS 2022 is higher than that in the reviews of papers at NeurIPS 2022.
Conclusions
Our findings indicate that the issues commonly encountered in peer reviews of papers, such as inconsistency, bias, miscalibration, and subjectivity, are also prevalent in peer reviews of peer reviews. Although assessing reviews can aid in creating improved incentives for high-quality peer review and evaluating the impact of policy decisions in this domain, it is crucial to exercise caution when interpreting peer reviews of peer reviews as indicators of the underlying review quality.
More details: https://arxiv.org/pdf/2311.09497.pdf
Acknowledgements: We sincerely thank everyone involved in the NeurIPS 2022 review process who agreed to take part in this experiment. Your participation has been invaluable in shedding light on the important topic of evaluating reviews, towards improving the peer-review process.