Today, customers interact with brands over an increasingly large digital and offline footprint, generating a wealth of interaction data known as behavioral data. As a result, marketers and customer experience teams must work with multiple overlapping tools to engage and target those customers across touchpoints. This increases complexity, creates multiple views of each customer, and makes it more challenging to provide an individual experience with relevant content, messaging, and product suggestions to each customer. In response, marketing teams use customer data platforms (CDPs) and cross-channel campaign management tools (CCCMs) to simplify the process of consolidating multiple views of their customers. These technologies provide non-technical users with an accelerated path to enable cross-channel targeting, engagement, and personalization, while reducing marketing teams’ dependency on technical teams and specialist skills to engage with customers.
Despite this, marketers find themselves with blind spots in customer activity when these technologies aren’t integrated with systems from other parts of the business. This is particularly true with non-digital channels, for example, in-store transactions or customer feedback from customer support. Marketing teams and their customer experience counterparts also struggle to integrate predictive capabilities developed by data scientists into their cross-channel campaigns or customer touchpoints. As a result, customers receive messaging and recommendations that aren’t relevant or are inconsistent with their expectations.
This post outlines how cross-functional teams can work together to address these challenges using an omnichannel personalization use case. We use a fictional retail scenario to illustrate how those teams interlock to provide a personalized experience at various points along the customer journey. We use Twilio Segment in our scenario, a customer data platform built on AWS. There are more than 12 CDPs in the market to choose from, many of which are also AWS partners, but we use Segment in this post because they provide a self-serve free tier that allows you to explore and experiment. We explain how to combine the output from Segment with in-store sales data, product metadata, and inventory information. Building on this, we explain how to integrate Segment with Amazon Personalize to power real-time recommendations. We also describe how we create scores for churn and repeat-purchase propensity using Amazon SageMaker. Lastly, we explore how to target new and existing customers in three ways:
- With banners on third-party websites, also known as display advertising, using a propensity-to-buy score to attract similar customers.
- On web and mobile channels presented with personalized recommendations powered by Amazon Personalize, which uses machine learning (ML) algorithms to create content recommendations.
- With personalized messaging using Amazon Pinpoint, an outbound and inbound marketing communications service. These messages target disengaged customers and those showing a high propensity to churn.
Solution overview
Imagine you are a product owner leading the charge on cross-channel customer experience for a retail company. The company has a diverse set of online and offline channels, but sees digital channels as its primary opportunity for growth. They want to grow the size and value of their customer base with the following methods:
- Attract new, highly qualified customers who are more likely to convert
- Increase the average order value of all their customers
- Re-attract disengaged customers to return and hopefully make repeat purchases
To ensure those customers receive a consistent experience across channels, you as a product owner need to work with teams such as digital marketing, front-end development, mobile development, campaign delivery, and creative agencies. To ensure customers receive relevant recommendations, you also need to work with data engineering and data science teams. Each of these teams are responsible for interacting with or developing features within the architecture illustrated in the following diagram.
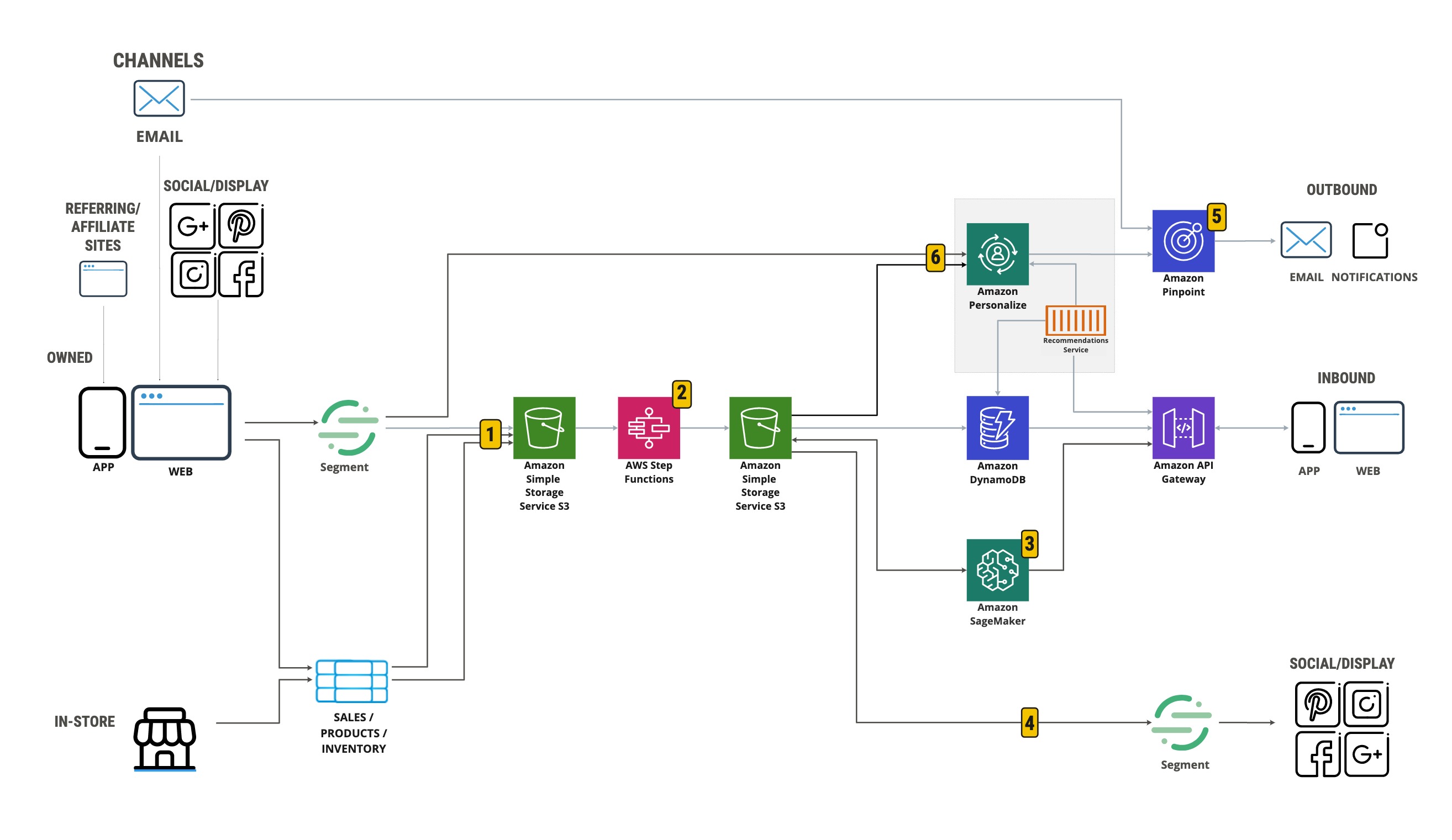
The solution workflow contains the following high-level steps:
- Collect data from multiple sources to store in Amazon Simple Storage Service (Amazon S3).
- Use AWS Step Functions to orchestrate data onboarding and feature engineering.
- Build segments and predictions using SageMaker.
- Use propensity scores for display targeting.
- Send personalized messaging using Amazon Pinpoint.
- Integrate real-time personalized suggestions using Amazon Personalize.
In the following sections, we walk through each step, explain the activities of each team at a high level, provide references to related resources, and share hands-on labs that provide more detailed guidance.
Collect data from multiple sources
Digital marketing, front-end, and mobile development teams can configure Segment to capture and integrate web and mobile analytics, digital media performance, and online sales sources using Segment Connections. Segment Personas allows digital marketing teams to resolve the identity of users by stitching together interactions across these sources into a single user profile with one persistent identifier. These profiles, along with calculated metrics called Computed Traits and raw events, can be exported to Amazon S3. The following screenshot shows how identity rules are set up in Segment Personas.

In parallel, engineering teams can use AWS Data Migration Service (AWS DMS) to replicate in-store sales, product metadata, and inventory data sources from databases such as Microsoft SQL or Oracle and store the output in Amazon S3.
Data onboarding and feature engineering
After data is collected and stored in the landing zone on Amazon S3, data engineers can use components from the serverless data lake framework (SDLF) to accelerate data onboarding and build out the foundational structure of a data lake. With SDLF, engineers can automate the preparation of user-item data used to train Amazon Personalize or create a single view of customer behavior by joining online and offline behavioral data and sales data, using attributes such as customer ID or email address as a common identifier.
Step Functions is the key orchestrator driving these transformation jobs within SDLF. You can use Step Functions to build and orchestrate both scheduled and event-driven data workflows. The engineering team can orchestrate the tasks of other AWS services within a data pipeline. The outputs from this process are stored in a trusted zone on Amazon S3 to use for ML development. For more information on implementing the serverless data lake framework, see AWS serverless data analytics pipeline reference architecture.
Build segments and predictions
The process of building segments and predictions can be broken down into three steps: access the environment, build propensity models, and create output files.
Access the environment
After the engineering team has prepared and transformed the ML development data, the data science team can build propensity models using SageMaker. First, they build, train, and test an initial set of ML models. This allows them to see early results, decide which direction to go next, and reproduce experiments.
The data science team needs an active Amazon SageMaker Studio instance, an integrated development environment (IDE) for rapid ML experimentation. It unifies all the key features of SageMaker and offers an environment to manage the end-to-end ML pipelines. It removes complexity and reduces the time it takes to build ML models and deploy them into production. Developers can use SageMaker Studio notebooks, which are one-click Jupyter notebooks that you can quickly spin up to enable the entire ML workflow from data preparation to model deployment. For more information on SageMaker for ML, see Amazon SageMaker for Data Science.
Build the propensity models
To estimate churn and repeat-purchase propensity, the customer experience and data science teams should agree on the known driving factors for either outcome.
The data science team validates these known factors while also discovering unknown factors through the modeling process. An example of a factor driving churn can be the number of returns in the last 3 months. An example of a factor driving repurchases can be the number of items saved on the website or mobile app.
For our use case, we assume that the digital marketing team wants to create a target audience using lookalike modeling to find customers most likely to repurchase in the next month. We also assume that the campaign team wants to send an email offer to customers who will likely end their subscription in the next 3 months to encourage them to renew their subscription.
The data science team can start by analyzing the data (features) and summarizing the main characteristics of the dataset to understand the key data behaviors. They can then shuffle and split the data into training and test and upload these datasets into the trusted zone. You can use an algorithm such as the XGBoost classifier to train the model and automatically provide the feature selection, which is the best set of candidates to determine the propensity scores (or predicted values).
You can then tune the model by optimizing the algorithm metrics (such as hyperparameters) based on the ranges provided within the XGBoost framework. Test data is used to evaluate the model’s performance and estimate how well it generalizes to new data. For more information on evaluation metrics, see Tune an XGBoost Model.
Lastly, the propensity scores are calculated for each customer and stored in the trusted S3 zone to be accessed, reviewed, and validated by the marketing and campaign teams. This process also provides a prioritized evaluation of feature importance, which helps to explain how the scores were produced.
Create the output files
After the data science team has completed the model training and tuning, they work with the engineering team to deploy the best model to production. We can use SageMaker batch transform to run predictions as new data is collected and generate scores for each customer. The engineering team can orchestrate and automate the ML workflow using Amazon SageMaker Pipelines, a purpose-built continuous integration and continuous delivery (CI/CD) service for ML, which offers an environment to manage the end-to-end ML workflow. It saves time and reduces errors typically caused by manual orchestration.
The output of the ML workflow is imported by Amazon Pinpoint for sending personalized messaging and exported to Segment to use when targeting on display channels. The following illustration provides a visual overview of the ML workflow.

The following screenshot shows an example output file.

Use propensity scores for display targeting
The engineering and digital marketing teams can create the reverse data flow back to Segment to increase reach. This uses a combination of AWS Lambda and Amazon S3. Every time a new output file is generated by the ML workflow and saved in the trusted S3 bucket, a Lambda function is invoked that triggers an export to Segment. Digital marketing can then use regularly updated propensity scores as customer attributes to build and export audiences to Segment destinations (see the following screenshot). For more information on the file structure of the Segment export, see Amazon S3 from Lambda.

When the data is available in Segment, digital marketing can see the propensity scores developed in SageMaker as attributes when they create customer segments. They can generate lookalike audiences to target them with digital advertising. To create a feedback loop, digital marketing must ensure that impressions, clicks, and campaigns are being ingested back into Segment to optimize performance.
Send personalized outbound messaging
The campaign delivery team can implement and deploy AI-driven win-back campaigns to re-engage customers at risk of churn. These campaigns use the list of customer contacts generated in SageMaker as segments while integrating with Amazon Personalize to present personalized product recommendations. See the following diagram.

The digital marketing team can experiment using Amazon Pinpoint journeys to split win-back segments into subgroups and reserve a percentage of users as a control group that isn’t exposed to the campaign. This allows them to measure the campaign’s impact and creates a feedback loop.
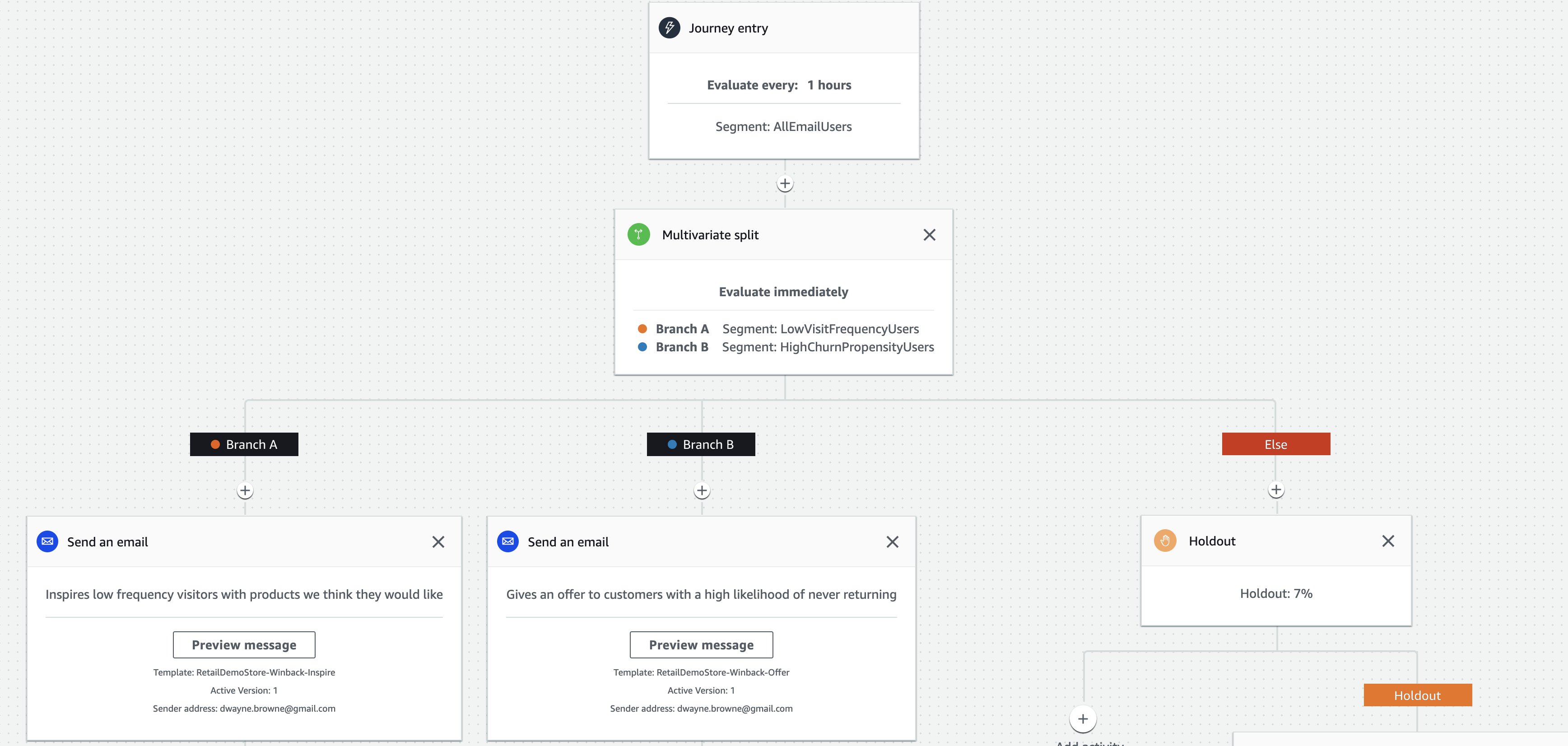
Integrate real-time recommendations
To personalize inbound channels, the digital marketing and engineering teams work together to integrate and configure Amazon Personalize to provide product recommendations at different points in the customer’s journey. For example, they can deploy a similar item recommender on product detail pages to suggest complementary items (see the following diagram). Additionally, they can deploy a content-based filtering recommender in the checkout journey to remind customers of products they would typically buy before completing their order.

First, the engineering team needs to create RESTful microservices that respond to web, mobile, and other channel application requests with product recommendations. These microservices call Amazon Personalize to get recommendations, resolve product IDs into more meaningful information like name and price, check inventory stock levels, and determine which Amazon Personalize campaign endpoint to query based on the user’s current page or screen.
The front-end and mobile development teams need to add tracking events for specific customer actions to their applications. They can then use Segment to send those events directly to Amazon Personalize in real time. These tracking events are the same as the user-item data we extracted earlier. They allow Amazon Personalize solutions to refine recommendations based on live customer interactions. It’s essential to capture impressions, product views, cart additions, and purchases because these events create a feedback loop for the recommenders. Lambda is an intermediary, collecting user events from Segment and sending them to Amazon Personalize. Lambda also facilitates the reverse data exchange, relaying updated recommendations for the user back to Segment. For more information on configuring real-time recommendations with Segment and Amazon Personalize, see the Segment Real-time data and Amazon Personalize Workshop.
Conclusion
This post described how to deliver an omnichannel customer experience using a combination of Segment customer data platform and AWS services such as Amazon SageMaker, Amazon Personalize, and Amazon Pinpoint. We explored the role cross-functional teams play at each stage in the customer journey and in the data value chain. The architecture and approach discussed are focused on a retail environment, but you can apply it to other verticals such as financial services or media and entertainment. If you’re interested in trying out some of what we discussed, check out the Retail Demo Store, where you can find hands-on workshops that include Segment and other AWS partners.
Additional references
For additional information, see the following resources:
- Omnichannel personalization with Segment
- Omnichannel personalization with Amazon Personalize
- Build, tune, and deploy an end-to-end churn prediction model using Amazon SageMaker Pipelines
- Automate feature engineering pipelines with Amazon SageMaker
- Monitor model quality
About Segment
Segment is an AWS Advanced Technology Partner and holder of the following AWS Independent Software Vendor (ISV) competencies: Data & Analytics, Digital Customer Experience, Retail, and Machine Learning. Brands such as Atlassian and Digital Ocean use real-time analytics solutions powered by Segment.
About the Authors
 Dwayne Browne is a Principal Analytics Platform Specialist at AWS based in London. He is part of the Data-Driven Everything (D2E) customer program, where he helps customers become more data-driven and customer experience focused. He has a background in digital analytics, personalization, and marketing automation. In his spare time, Dwayne enjoys indoor climbing and exploring nature.
Dwayne Browne is a Principal Analytics Platform Specialist at AWS based in London. He is part of the Data-Driven Everything (D2E) customer program, where he helps customers become more data-driven and customer experience focused. He has a background in digital analytics, personalization, and marketing automation. In his spare time, Dwayne enjoys indoor climbing and exploring nature.
 Hara Gavriliadi is a Senior Data Analytics Strategist at AWS Professional Services based in London. She helps customers transform their business using data, analytics, and machine learning. She specializes in customer analytics and data strategy. Hara loves countryside walks and enjoys discovering local bookstores and yoga studios in her free time.
Hara Gavriliadi is a Senior Data Analytics Strategist at AWS Professional Services based in London. She helps customers transform their business using data, analytics, and machine learning. She specializes in customer analytics and data strategy. Hara loves countryside walks and enjoys discovering local bookstores and yoga studios in her free time.
 Kenny Rajan is a Senior Partner Solution Architect. Kenny helps customers get the most from AWS and its partners by demonstrating how AWS partners and AWS services work better together. He’s interested in machine learning, data, ERP implementation, and voice-based solutions on the cloud. Outside of work, Kenny enjoys reading books and helping with charity activities.
Kenny Rajan is a Senior Partner Solution Architect. Kenny helps customers get the most from AWS and its partners by demonstrating how AWS partners and AWS services work better together. He’s interested in machine learning, data, ERP implementation, and voice-based solutions on the cloud. Outside of work, Kenny enjoys reading books and helping with charity activities.