Figure 1: Overview: To avoid out-of-distribution actions in the Offline Reinforcement Learning problem, we propose to implicitly constrain the policy by modifying the action space instead of enforcing explicit constraints. The policy is trained to output a latent action which will be passed into a decoder pretrained with the dataset. We demonstrate that our method provides competitive performance in both simulation and real-robot experiments.
Offline RL: Learning a policy from a static dataset
The goal of Reinforcement Learning (RL) is to learn to perform a task by interacting with the environment. It has achieved significant success in a lot of applications such as games and robotics. One major challenge in RL is that it requires a huge amount of interactive data collected in the environment to learn a policy. However, data collection is expensive and potentially dangerous in many real-world applications, such as robotics in safety-critical situations (e.g., around humans) or healthcare problems. Worse, RL algorithms also usually assume that the dataset used to update the policy comes from the current policy or its own training process.
To use data more wisely, we may consider Offline Reinforcement Learning. The goal of offline RL is to learn a policy from a static dataset of transitions without further data collection. Although we may still need a large amount of data, the assumption of static datasets allows more flexibility in data collection. For example, in robotics, we can include human demonstrations, reuse rollouts from previous experiments, and share data within the community. In this way, the dataset is more likely to be scaled up in size even when data collection is expensive.
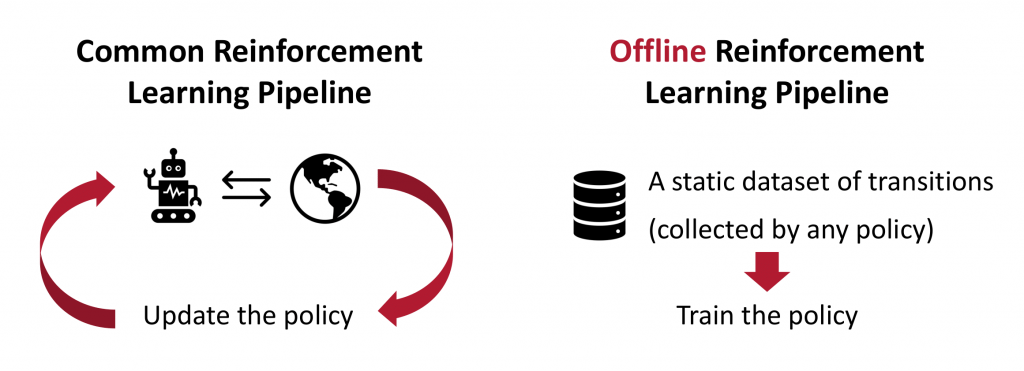
One important feature of offline RL is that it requires no assumption about the performance of the policy that is used to collect the dataset. This is in contrast to behavior cloning, where we assume that the dataset is collected by an expert, so that we can directly “copy” the actions given states without reasoning about the future reward. In offline RL, the dataset could be collected by a policy (or several policies) with arbitrary performance.
At first glance, off-policy algorithms seem to be able to meet the above requirements. Off-policy algorithms save the agent’s interactions during training in a replay buffer and train the policy by sampling transitions from the replay buffer (Lillicrap 2015, Haarnoja 2018). However, as shown in previous work (Fujimoto 2018b), when we apply off-policy algorithms to a static dataset, the performance can be very poor due to out-of-distribution actions. In the off-policy algorithm, the Q-function is updated by the Bellman operator:
$$ mathcal{T} hat{Q}^pi(s_t, a_t) = mathbb{E}_{r_t, s_{t+1}}[r_t + gamma hat{Q}^pi(s_{t+1}, pi(s_{t+1}))] $$
As explained in Fujimoto (2018b), if the policy selects an action (pi(s_{t+1})) that is not included in this static dataset, then the term (hat{Q}^pi(s_{t+1},pi(s_{t+1}))) may have a large extrapolation error. The extrapolation error will be accumulated by the Bellman operator and exacerbated by the policy updates. These errors eventually lead to significant overestimation bias that can hurt the performance. This has always been an issue for Q-learning-based methods (Thrun 1993, Fujimoto 2018a), but it is especially problematic when applied on a static dataset because the policy is not able to try out and correct the overly-optimistic actions. The problem is more significant when the action space is large, such as continuous action space with high dimensions.
Objectives for Offline RL algorithms to avoid out-of-distribution actions
To fix the issue discussed above and to fully utilize the dataset, we need two objectives in offline RL. First, the policy should be constrained to select actions within the support of the dataset. The policy that represents the probability distribution (p(a|s)) of the dataset is usually called the behavior policy, denoted as (pi_B). We aim to maximize the return of the policy (G_t) subject to the constraint that (pi_B(a|s)) is larger than a threshold (epsilon):
$$ max_{asim pi(cdot|s)} mathbb{E}[G_t]$$
$$ s.t. pi_B(a|s) > epsilon$$
An illustration of this constraint is shown in Figure 3 below. Given a behavior policy ( pi_B(a|s) ) on the top figure, the agent policy ( pi) should only choose actions within the green region where ( pi_B(a|s) > epsilon). On the other hand, the constraint cannot be overly restrictive. Specifically, the policy should not be affected by the density of (pi_B). In the example in Figure 3, the policy should have the flexibility to choose any action within the green region even if it deviates from the most probable action of (pi_B) and the “shape” of the distribution (pi) is very different from the shape of (pi_B).
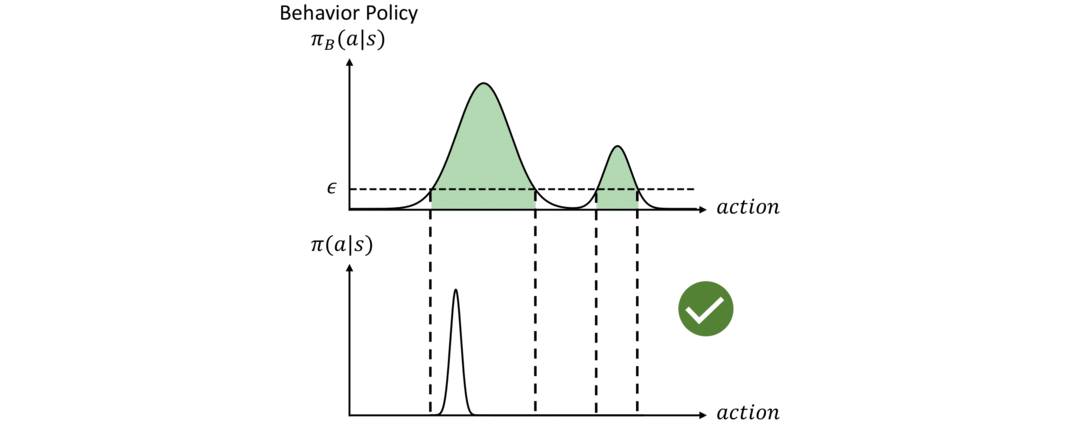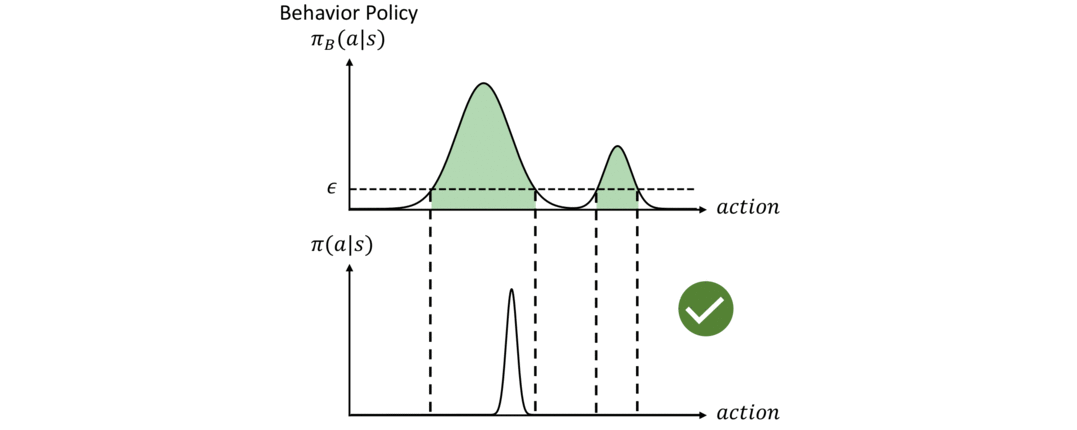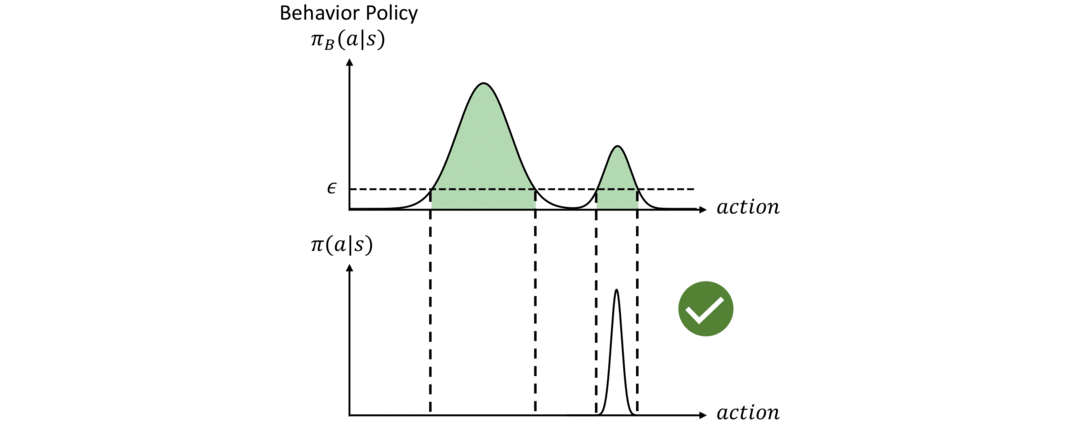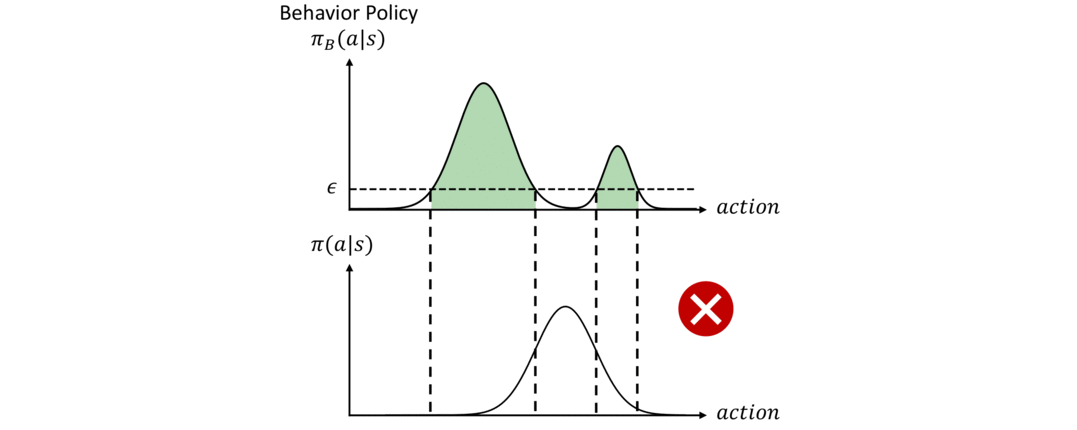
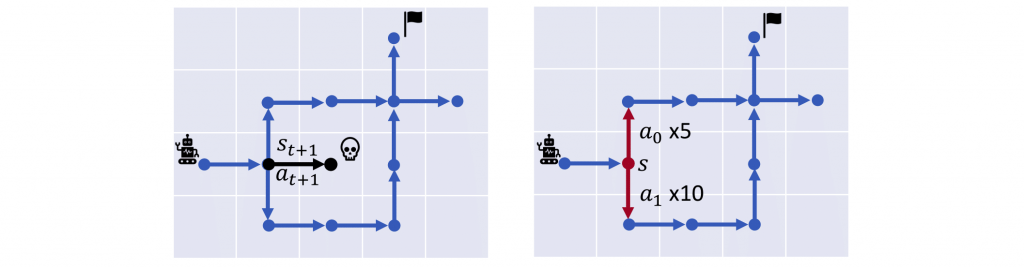
Figure 4 below shows a more intuitive example. Consider an agent in a grid world. Suppose that the agent has a dataset of transitions marked as blue dots and arrows. The agent aims to find a path to get to the goal without the information of the other parts of the map. As shown on the left figure, it cannot select out-of-distribution actions because it might be dangerous. As shown on the right figure, if action (a_1) appears 10 times in the dataset, and action (a_0) appears 5 times in the dataset, it should not choose action (a_1) just because it appears more often in the dataset; as shown, this might be a suboptimal action for the task.
Previous methods struggled with achieving both of these objectives. For example, BCQ (Fujimoto 2018b) proposes to sample from the behavior policy, perturb around it and then take the action that maximizes the Q-value. This method will be restricted by the density of the behavior policy distribution if the sample size 𝑁 is not large enough. Another line of work uses explicit policy constraints in the optimization process (Jaques 2019, Kumar 2019, Wu 2019). They try to force the agent policy to be close to the behavior policy in terms of different measures of distance, such as KL or MMD (Figure 1). The explicit constraints create difficulties in the optimization and distance metrics such as KL will be affected by the density (see Appendix E in our paper).
Proposed Method: Policy in Latent Action Space (PLAS)
In our paper, PLAS: Latent Action Space for Offline Reinforcement Learning (CoRL 2020), we propose a method that can satisfy both the objectives discussed above by simply modifying the action space of the policy – i.e., the policy will only select actions when ( pi_B(a|s) > epsilon), but will not be restricted by the density of the distribution ( pi_B(a|s)). In our method, we first model the behavior policy using a Conditional Variational Autoencoder (CVAE) as in previous work (Fujimoto 2018b, Kumar 2019). The CVAE is trained to reconstruct actions conditioned on the states. The decoder of the CVAE creates a mapping from the latent space to the action space. Instead of training a policy in the action space of the environment, we propose to learn a Policy in the Latent Action Space (PLAS) of the CVAE and then use the pretrained decoder to output an action in the original action space.
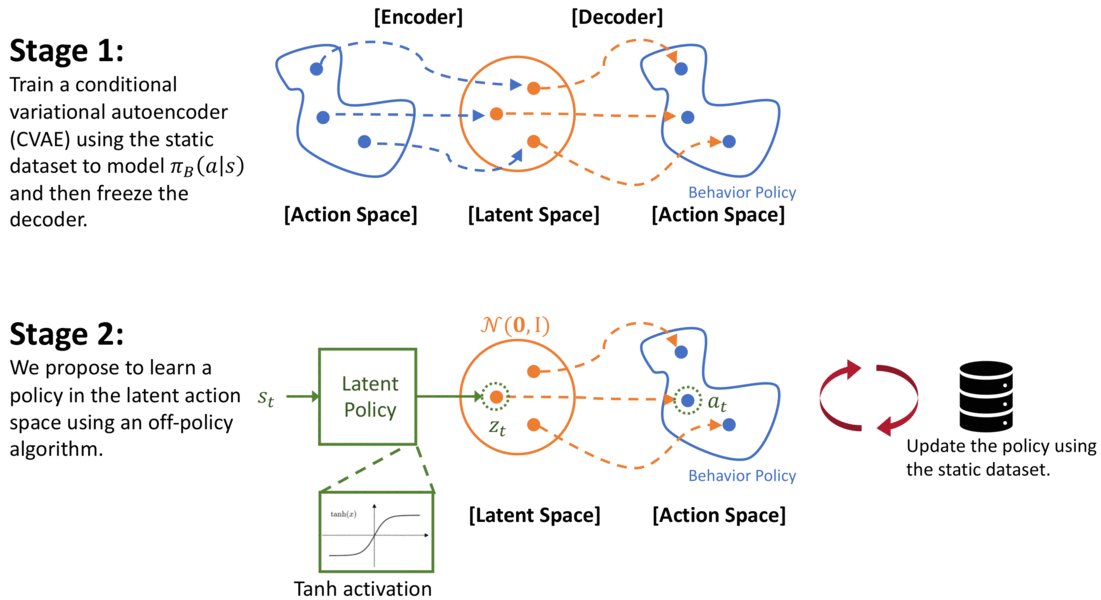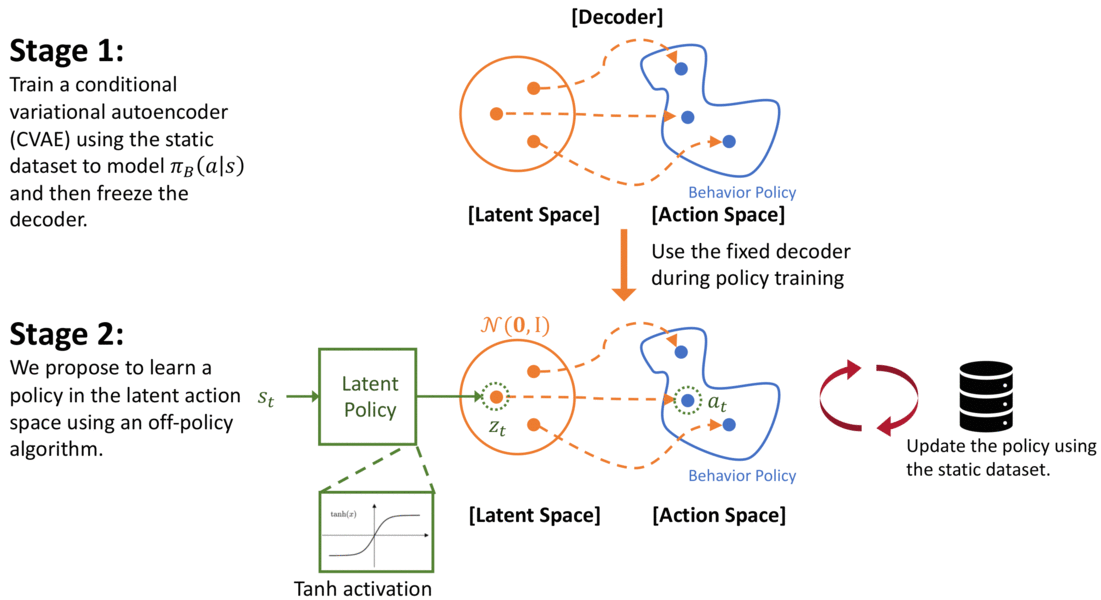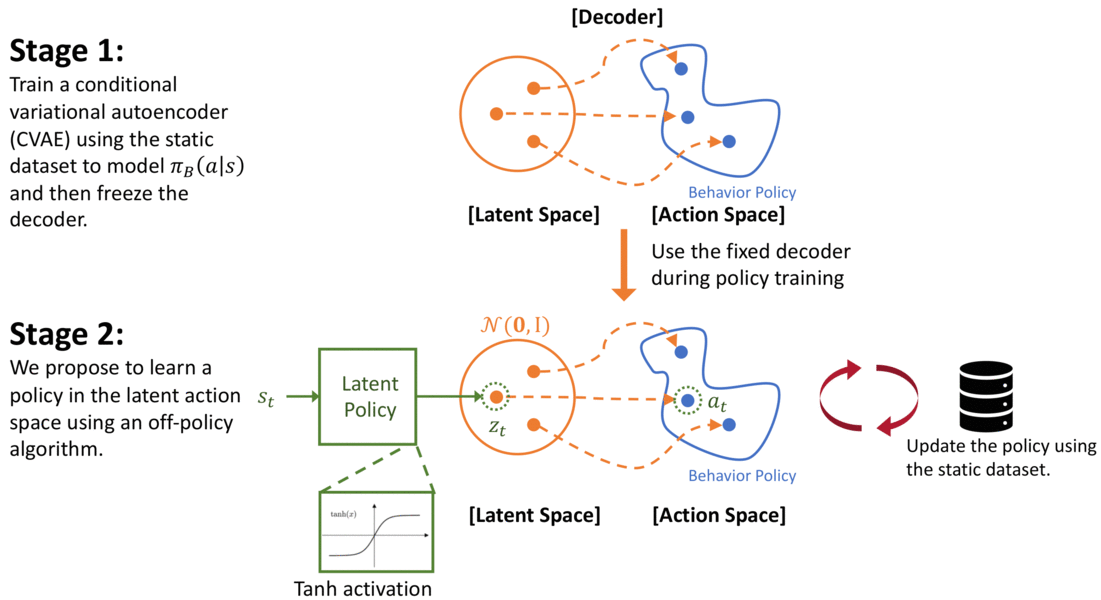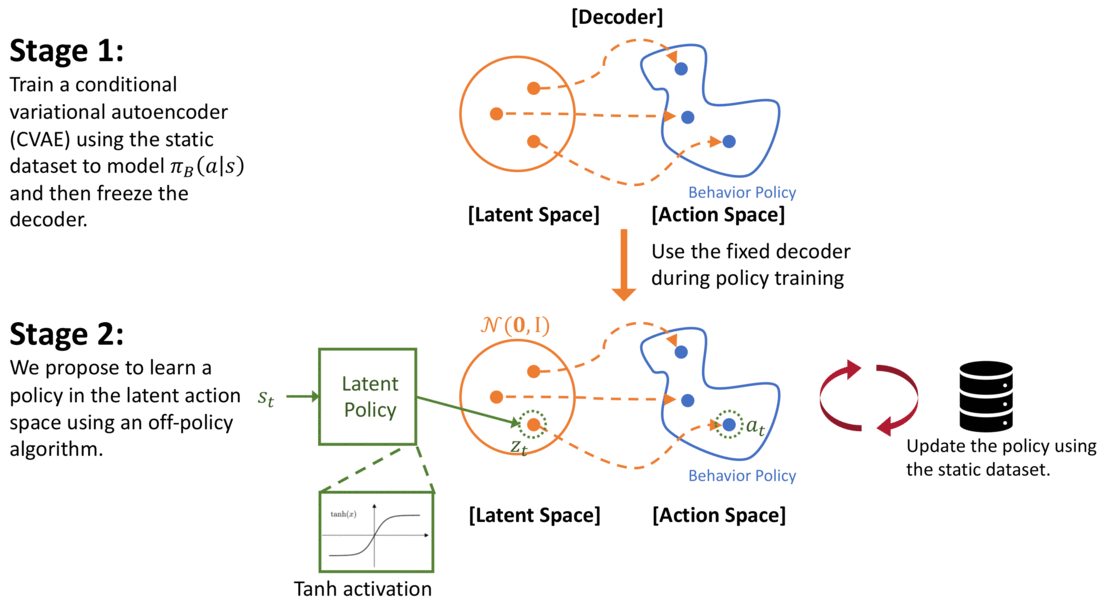
Using the above approach, we can naturally constrain the policy to select actions within the dataset because the action is chosen from the latent space. The prior of the latent variable of CVAE is set to be a normal distribution for simplicity, following the common practice. To constrain the latent policy from selecting actions that are too “far away” from this prior, we use a tanH activation at the output of the policy; this implicitly constrains the policy to select within a fixed number of standard deviations of the mean of the latent prior. It is important to note that the action output from the decoder should be conditioned on the state because we care about (pi_B(a|s) > epsilon) instead of (pi_B(a)>epsilon). This approach also satisfies the second objective because the policy can select any action within the latent space and will not be affected by the density of the behavior policy.
Experiments: Cloth Sliding and D4RL benchmark
This modification over the action space can be built on top of any off-policy algorithm with either a stochastic or deterministic policy. In our experiment, we use TD3 (Fujimoto 2018a) with a deterministic latent policy. We evaluate our algorithm on a wide range of continuous control tasks, including a real robot experiment on cloth sliding and the D4RL benchmark.
The task for the real-robot experiment is to slide along the edge of the cloth without dropping it. The dataset we use consists of a replay buffer from a previous experiment (around 7000 timesteps) and 5 episodes of expert trajectories (around 300 timesteps). Our method outperforms all the baselines and achieves similar performance as the expert.

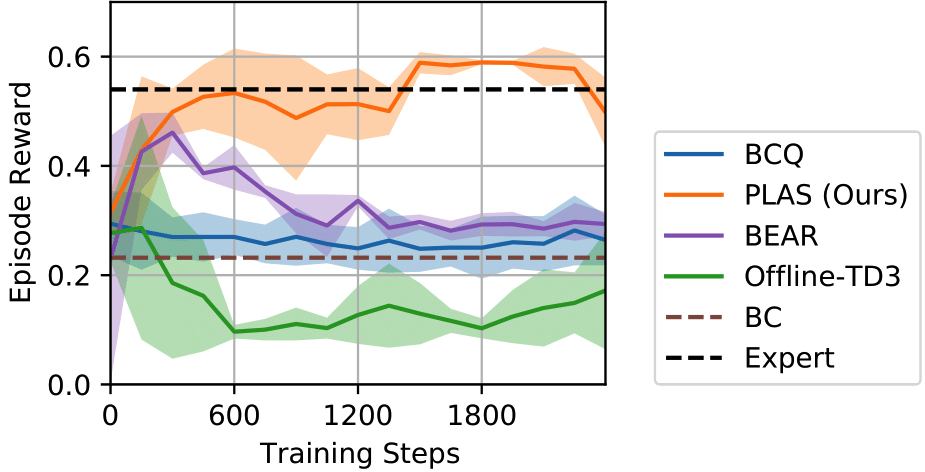
Figure 6: Results from the real robot experiment. Left: Performance of PLAS on the cloth-sliding task. More videos can be found here. Right: Training curves of PLAS and the baselines. PLAS outperforms the other baselines and achieves similar performance as the expert.
On the D4RL benchmark, our method also achieves consistent performance across a wide range of datasets with different environments and qualities despite its simplicity. We provide some of the qualitative and quantitative results below in Figures 7 and 8. Check out the full results on the D4RL benchmark in the paper. More videos can be found on our website.
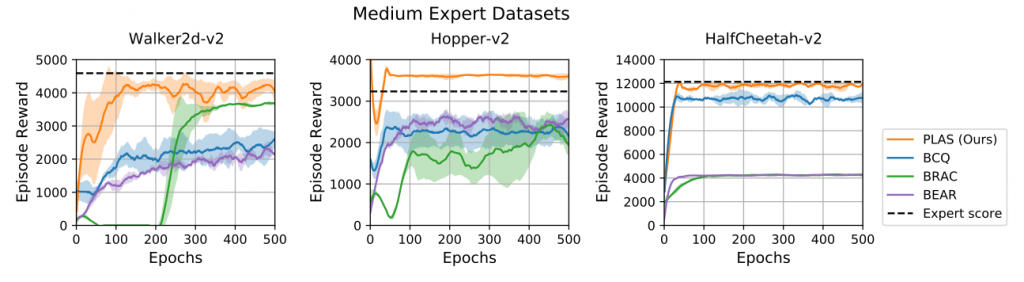
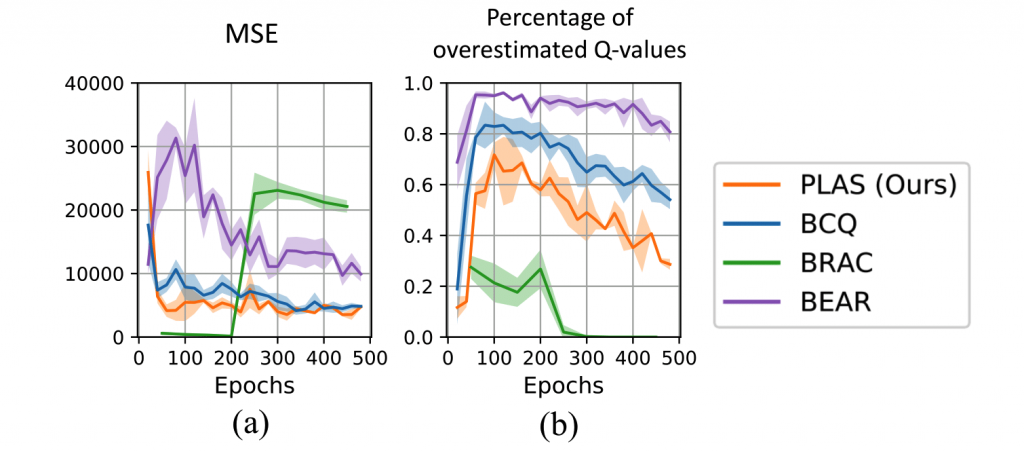
To further analyze the result, we plot the estimation error of the learned Q-functions in Figure 9. During the evaluation, we compare the estimated Q-value of the state-action pairs with their true return from the rollouts. Our method has the lowest mean squared error (MSE) while the baselines have either more significant overestimation or underestimation.
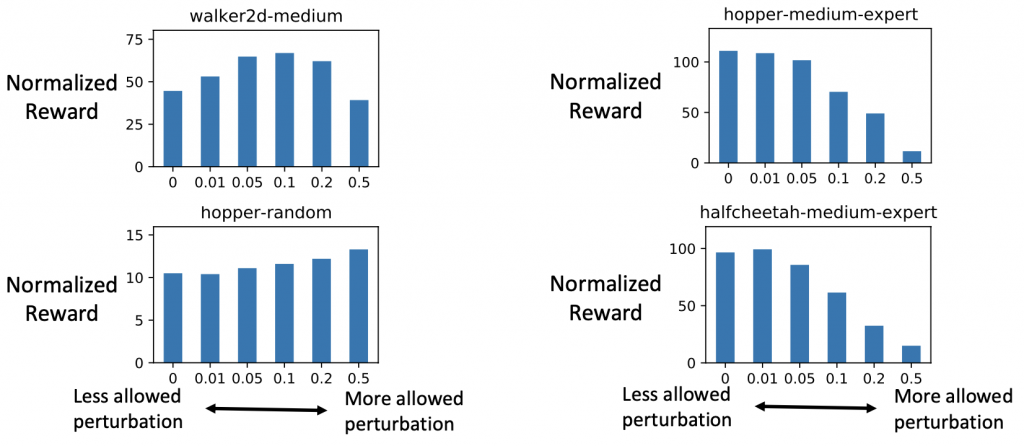
As mentioned earlier in the objectives, our method focuses on avoiding out-of-distribution actions. In our experiment, we analyze the effect of out-of-distribution actions by introducing an additional component: we add a perturbation layer that is trained together with the latent policy, inspired by Fujimoto 2018b. The perturbation layer outputs a residual over the action output of the decoder. This allows the final policy output to deviate from the support of the dataset in a controlled way. More precisely, restricting the range of the output of the perturbation layer is essentially constraining the action output to be close to the dataset in terms of the L-infinity norm. In Figure 10, we plot the performance of our method with different ranges of allowed perturbation. We found that out-of-distribution actions introduced by the perturbation layer are usually harmful to datasets with high-quality rollouts such as the medium-expert datasets. However, it could be helpful for some of the random or medium datasets depending on the environment. The full analysis of the perturbation layer can be found in Appendix D. The results shed light on the disentangled contributions of in-distribution generalization and out-of-distribution generalization in offline reinforcement learning.
Conclusion and Discussion
We propose a simple and straightforward approach to offline RL: Policy in the Latent Action Space (PLAS). To summarize:
- Our approach naturally avoids out-of-distribution actions while allowing the flexibility for improvement over the performance of the dataset through implicit constraints.
- It achieves competitive performance in both simulated environments and a real robot experiment on cloth manipulation.
- We provided the analyses on Q-function estimation error and the separation of in-distribution vs. out-of-distribution generalization in Offline RL.
Please visit our website for the paper, code, and more videos.
Our method can be extended in different ways. First, it will benefit from a better generative model. For example, using normalizing flow to replace VAE could potentially lead to theoretical guarantees and better evaluation performance. Second, it can also be extended to allow better “out-of-distribution” generalization. We hope that our method will pave the way for future possibilities of applying reinforcement learning algorithms to real-world applications by using the static datasets more efficiently.
Acknowledgements
This material is based upon work supported by the United States Air Force and DARPA under Contract No. FA8750-18-C-0092, LG Electronics and the National Science Foundation under Grant No. IIS-1849154. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of United States Air Force and DARPA and the National Science Foundation.
DISCLAIMER: All opinions expressed in this post are those of the author and do not represent the views of Carnegie Mellon University.