Posted by Penporn Koanantakool and Pankaj Kanwar.
As the number of accelerators (GPUs, TPUs) in the ML ecosystem has exploded, there has been a strong need for seamless integration of new accelerators with TensorFlow. In this post, we introduce the PluggableDevice architecture which offers a plugin mechanism for registering devices with TensorFlow without the need to make changes in TensorFlow code.
This PluggableDevice architecture has been designed & developed collaboratively within the TensorFlow community. It leverages the work done for Modular TensorFlow, and is built using the StreamExecutor C API. The PluggableDevice mechanism is available in TF 2.5.
The need for Seamless integration
Prior to this, any integration of a new device required changes to the core TensorFlow. This was not scalable because of several issues, for example:
- Complex build dependencies and compiler toolchains. Onboarding a new compiler is nontrivial and adds to the technical complexity of the product.
- Slow development time. Changes need code reviews from the TensorFlow team, which can take time. Added technical complexity also adds to the development and testing time for new features.
- Combinatorial number of build configurations to test for. The changes made for a particular device might affect other devices or other components of TensorFlow. Each new device could increase the number of test configurations in a multiplicative manner.
- Easy to break. The lack of a contract via a well defined API means that it’s easier to break a particular device.
What is PluggableDevice?
The PluggableDevice mechanism requires no device-specific changes in the TensorFlow code. It relies on C APIs to communicate with the TensorFlow binary in a stable manner. Plug-in developers maintain separate code repositories and distribution packages for their plugins and are responsible for testing their devices. This way, TensorFlow’s build dependencies, toolchains, and test process are not affected. The integration is also less brittle since only changes to the C APIs or PluggableDevice components could affect the code.
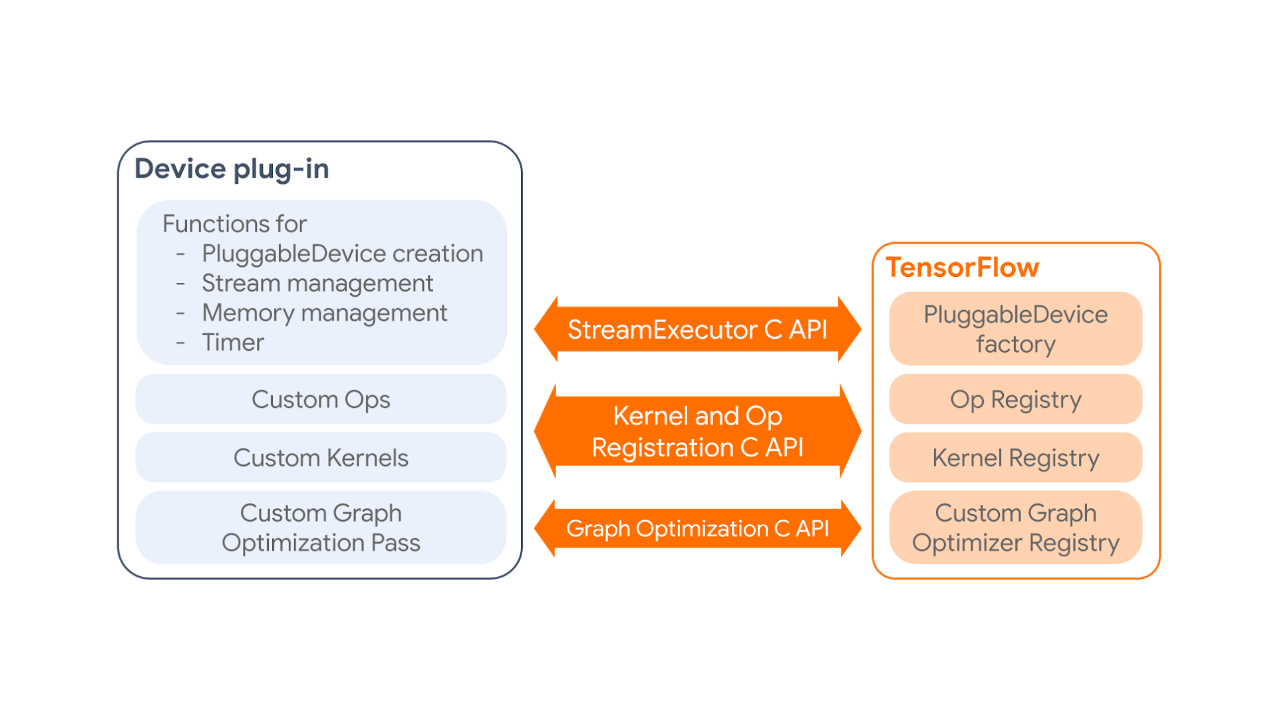
The PluggableDevice mechanism has four main components:
- PluggableDevice type: A new device type in TensorFlow which allows device registration from plug-in packages. It takes priority over native devices during the device placement phase.
- Custom operations and kernels: Plug-ins register their own operations and kernels to TensorFlow through the Kernel and Op Registration C API.
- Device execution and memory management: TensorFlow manages plug-in devices through the StreamExecutor C API.
- Custom graph optimization pass: Plug-ins can register one custom graph optimization pass, which will be run after all standard Grappler passes, through the Graph Optimization C API.
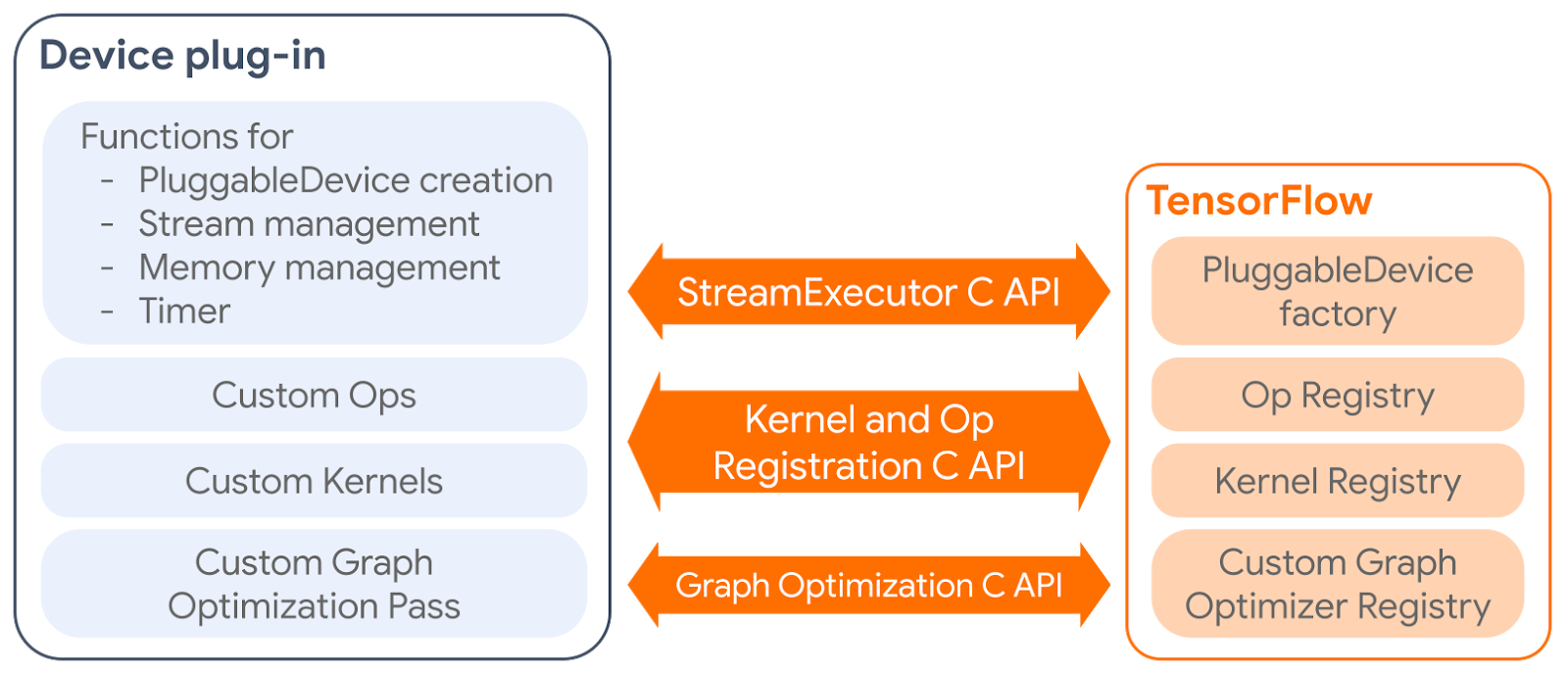 |
| How a device plug-in interacts with TensorFlow. |
Using PluggableDevice
To be able to use a particular device, like one would a native device in TensorFlow, users only have to install the device plug-in package for that device. The following code snippet shows how the plugin for a new device, say Awesome Processing Unit (APU), would be installed and used. For simplicity, let this APU plug-in only have one custom kernel for ReLU.
$ pip install tensorflow-apu-0.0.1-cp36-cp36m-linux_x86_64.whl
…
Successfully installed tensorflow-apu-0.0.1
$ python
Python 3.6.9 (default, Oct 8 2020, 12:12:24)
[GCC 8.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf # TensorFlow registers PluggableDevices here
>>> tf.config.list_physical_devices()
[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:APU:0', device_type='APU')]
>>> a = tf.random.normal(shape=[5], dtype=tf.float32) # Runs on CPU
>>> b = tf.nn.relu(a) # Runs on APU
>>> with tf.device("/APU:0"): # Users can also use 'with tf.device' syntax
... c = tf.nn.relu(a) # Runs on APU
>>> @tf.function # Defining a tf.function
... def run():
... d = tf.random.uniform(shape=[100], dtype=tf.float32) # Runs on CPU
... e = tf.nn.relu(d) # Runs on APU
>>> run() # PluggableDevices also work with tf.function and graph mode.Upcoming PluggableDevices
We are excited to announce that Intel will be one of our first partners to release a PluggableDevice. Intel has made significant contributions to this effort, submitting over 3 RFCs implementing the overall mechanism. They will release an Intel extension for TensorFlow (ITEX) plugin package to bring Intel XPU to TensorFlow for AI workload acceleration. We also expect other partners to take advantage of PluggableDevice and release additional plug-ins.
We will publish a detailed tutorial on how to develop a PluggableDevice plug-in for partners who might be interested in leveraging this infrastructure. For questions on the PluggableDevices, engineers can post questions directly on the RFC PRs [1, 2, 3, 4, 5, 6], or on the TensorFlow Forum with the tag pluggable_device.