Posted by Rishabh Singh, Research Scientist and Max Lin, Software Engineer, Google Research
Hundreds of millions of people use spreadsheets, and formulas in those spreadsheets allow users to perform sophisticated analyses and transformations on their data. Although formula languages are simpler than general-purpose programming languages, writing these formulas can still be tedious and error-prone, especially for end-users. We’ve previously developed tools to understand patterns in spreadsheet data to automatically fill missing values in a column, but they were not built to support the process of writing formulas.
In “SpreadsheetCoder: Formula Prediction from Semi-structured Context“, published at ICML 2021, we describe a new model that learns to automatically generate formulas based on the rich context around a target cell. When a user starts writing a formula with the “=” sign in a target cell, the system generates possible relevant formulas for that cell by learning patterns of formulas in historical spreadsheets. The model uses the data present in neighboring rows and columns of the target cell as well as the header row as context. It does this by first embedding the contextual structure of a spreadsheet table, consisting of neighboring and header cells, and then generates the desired spreadsheet formula using this contextual embedding. The formula is generated as two components: 1) the sequence of operators (e.g., SUM, IF, etc.), and 2) the corresponding ranges on which the operators are applied (e.g., “A2:A10”). The feature based on this model is now generally available to Google Sheets users.
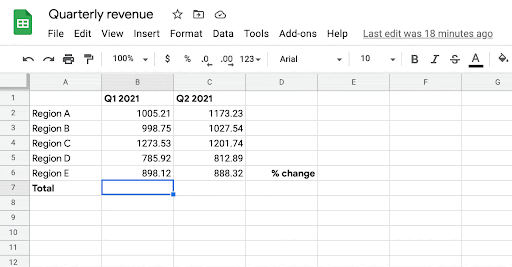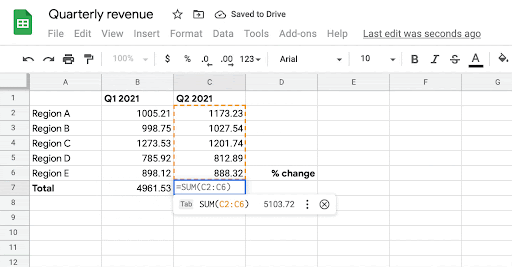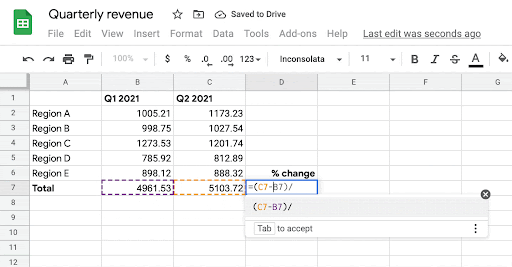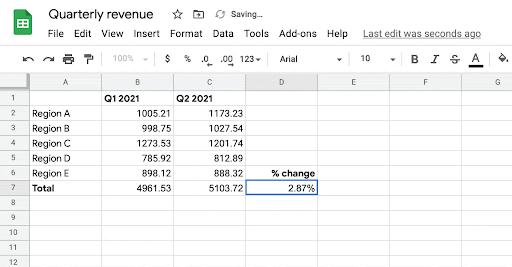 |
| Given the user’s intent to enter a formula in cells B7, C7, and D7, the system automatically infers the most likely formula the user might want to write in those cells. |
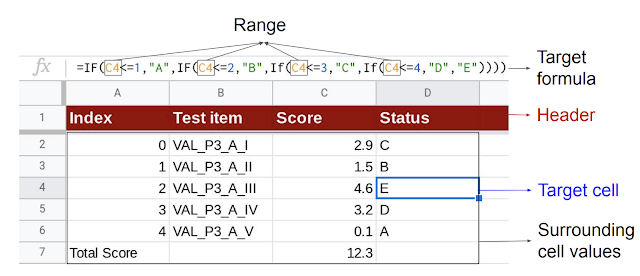 |
| Given the target cell (D4), the model uses the header and surrounding cell values as context to generate the target formula consisting of the corresponding sequence of operators and range. |
Model Architecture
The model uses an encoder-decoder architecture that allows the flexibility to embed multiple types of contextual information (such as that contained in neighboring rows, columns, headers, etc.) in the encoder, which the decoder can use to generate desired formulas. To compute the embedding of the tabular context, it first uses a BERT-based architecture to encode several rows above and below the target cell (together with the header row). The content in each cell includes its data type (such as numeric, string, etc.) and its value, and the cell contents present in the same row are concatenated together into a token sequence to be embedded using the BERT encoder. Similarly, it encodes several columns to the left and to the right of the target cell. Finally, it performs a row-wise and column-wise convolution on the two BERT encoders to compute an aggregated representation of the context.
The decoder uses a long short-term memory (LSTM) architecture to generate the desired target formula as a sequence of tokens by first predicting a formula-sketch (consisting of formula operators without ranges) and then generating the corresponding ranges using cell addresses relative to the target cell. It additionally leverages an attention mechanism to compute attention vectors over the header and cell data, which are concatenated to the LSTM output layer before making the predictions.
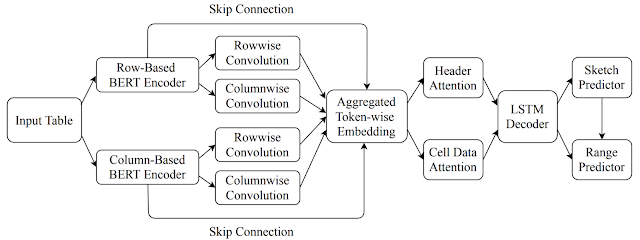 |
| The overall architecture of the formula prediction model. |
In addition to the data present in neighboring rows and columns, the model also leverages additional information from the high-level sheet structure, such as headers. Using TPUs for model predictions, we ensure low latency on generating formula suggestions and are able to handle more requests on fewer machines.
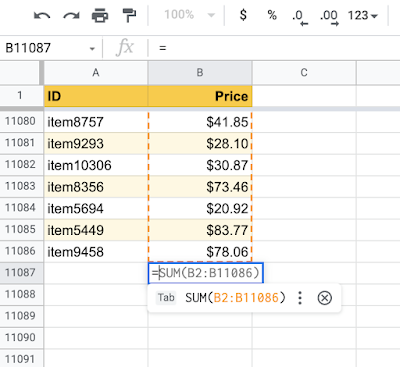 |
| Leveraging the high-level spreadsheet structure, the model can learn ranges that span thousands of rows. |
Results
In the paper, we trained the model on a corpus of spreadsheets created by and shared with Googlers. We split 46k Google Sheets with formulas into 42k for training, 2.3k for validation, and 1.7k for testing. The model achieves a 42.5% top-1 full-formula accuracy, and 57.4% top-1 formula-sketch accuracy, both of which we find high enough to be practically useful in our initial user studies. We perform an ablation study, in which we test several simplifications of the model by removing different components, and find that having row- and column-based context embedding as well as header information is important for models to perform well.
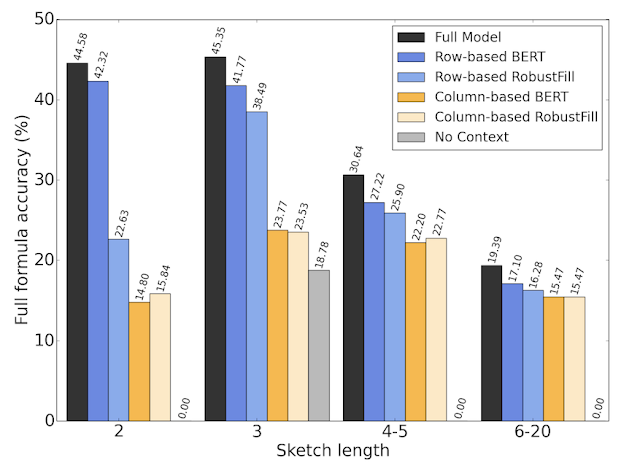 |
| The performance of different ablations of our model with increasing lengths of the target formula. |
Conclusion
Our model illustrates the benefits of learning to represent the two-dimensional relational structure of the spreadsheet tables together with high-level structural information, such as table headers, to facilitate formula predictions. There are several exciting research directions, both in terms of designing new model architectures to incorporate more tabular structure as well as extending the model to support more applications such as bug detection and automated chart creation in spreadsheets. We are also looking forward to seeing how users use this feature and learning from feedback for future improvements.
Acknowledgements
We gratefully acknowledge the key contributions of the other team members, including Alexander Burmistrov, Xinyun Chen, Hanjun Dai, Prashant Khurana, Petros Maniatis, Rahul Srinivasan, Charles Sutton, Amanuel Taddesse, Peilun Zhang, and Denny Zhou.
