In our earlier post, diffusion-fast, we showed how the Stable Diffusion XL (SDXL) pipeline can be optimized up to 3x using native PyTorch code. Back then, SDXL was an open SoTA pipeline for image generation. Quite unsurprisingly, a lot has changed since then, and it’s safe to say that Flux is now one of the most capable open-weight models in the space.
In this post, we’re excited to show how we enabled ~2.5x speedup on Flux.1-Schnell and Flux.1-Dev using (mainly) pure PyTorch code and a beefy GPU like H100.
If you cannot wait to get started with the code, you can find the repository here.
Overview of the optimizations
The pipelines shipped in the Diffusers library try to be as `torch.compile`-friendly as possible. This means:
- No graph breaks wherever possible
- No recompilations wherever possible
- None-to-minimal CPU<->GPU syncs to reduce inductor cache lookup overhead
Therefore, it already gives us a reasonable starting point. For this project, we took the same underlying principles used in the diffusion-fast project and applied them to the FluxPipeline. Below, we share an overview of the optimizations we applied (details in the repository):
- `torch.compile` with “fullgraph=True” and “max-autotune” mode, ensuring the use of CUDAgraphs
- Combining q,k,v projections for attention computation. This is particularly helpful during quantization as it thickens the dimensionality, improving compute density
- `torch.channels_last` memory format for the decoder output
- Flash Attention v3 (FA3) with (unscaled) conversion of inputs to `torch.float8_e4m3fn`
- Dynamic float8 activation quantization and quantization of Linear layer weights via torchao’s `float8_dynamic_activation_float8_weight`
- Some flags for tuning Inductor performance on this model:
- conv_1x1_as_mm = True
- epilogue_fusion = False
- coordinate_descent_tuning = True
- coordinate_descent_check_all_directions = True
- torch.export + Ahead-of-time Inductor (AOTI) + CUDAGraphs
Most of these optimizations are self-explanatory, barring these two:
- Inductor flags. Interested readers can check out this blog post for more details.
- With AoT compilation, we aim to eliminate the framework overhead and obtain a compiled binary that can be exported through `torch.export`. With CUDAGraphs, we want to enable optimization of kernel launches. More details are available in this post.
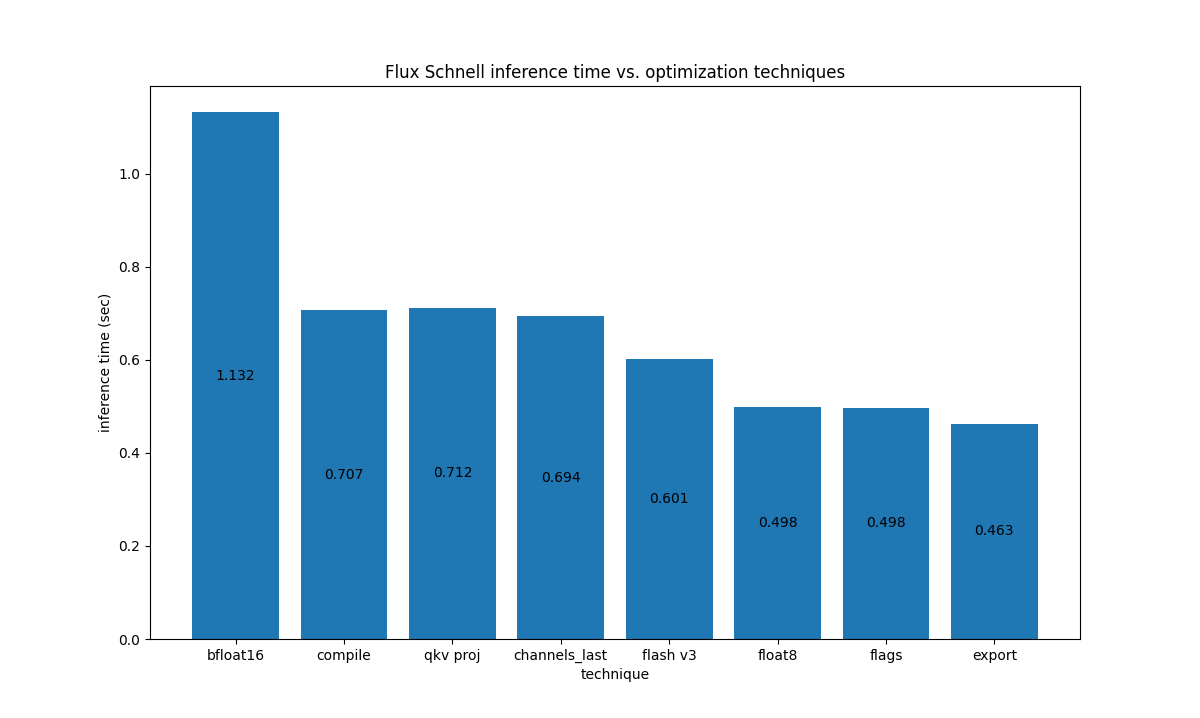
Unlike LLMs, diffusion models are heavily compute-bound, so optimizations from gpt-fast don’t exactly carry over here. The figure below shows the impact of each of the optimizations (applied incrementally from left-right) to Flux.1-Schnell on an H100 700W GPU:
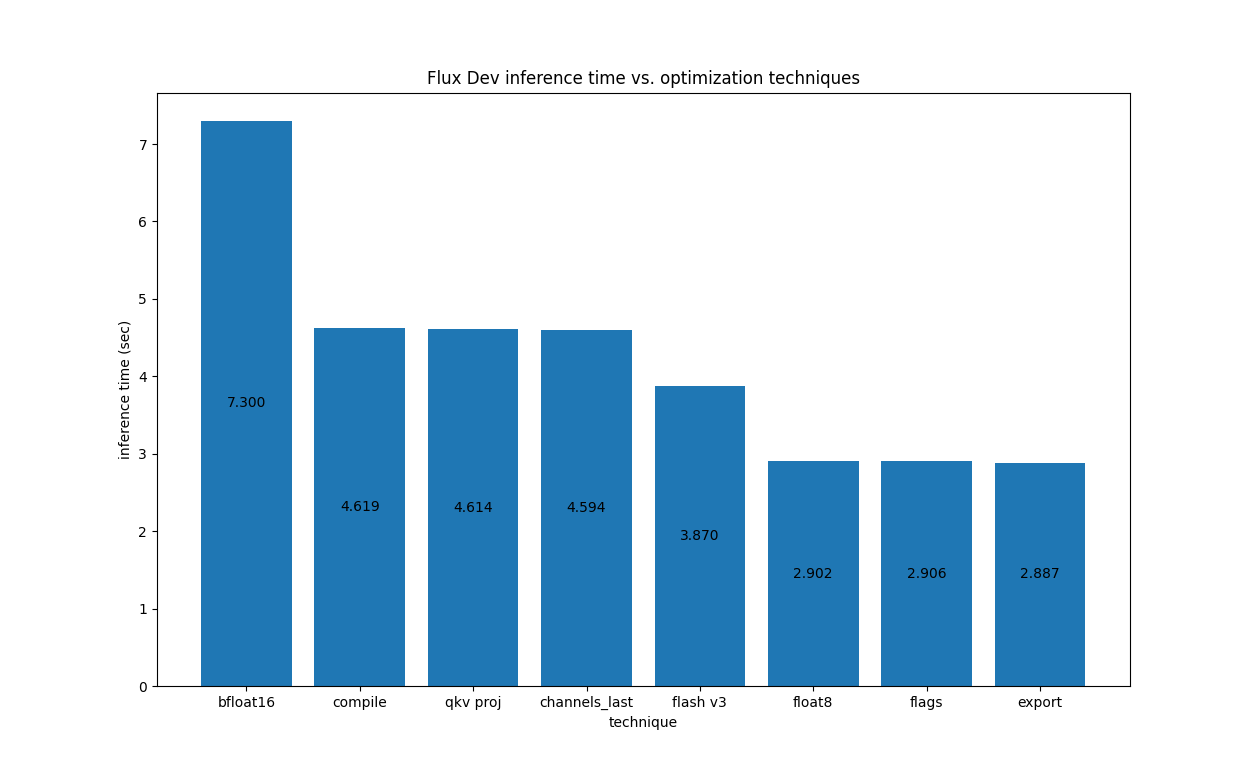
 For Flux.1-Dev on H100, we have the following
For Flux.1-Dev on H100, we have the following
 Below is a visual comparison of the images obtained with different optimizations applied to Flux.1-Dev:
Below is a visual comparison of the images obtained with different optimizations applied to Flux.1-Dev:

It should be noted that only FP8 quantization is lossy in nature so, for most of these optimizations, the image quality should stay identical. However, in this case, we see very negligible differences in the case of FP8.
Note on CUDA syncs
During our investigations, we found out that at the first step of the denoising loop, there’s a CPU<->GPU sync point caused by this step in the scheduler. We could get rid of it by adding `self.scheduler.set_begin_index(0)` at the beginning of the denoising loop (PR).
It actually makes a bigger deal when torch.compile is used, since the CPU has to wait for the sync before it can do a Dynamo cache lookup and then launch instructions on the GPU, and this cache lookup is a bit slow. Hence, the takeaway message is that it’s always wise to profile your pipeline implementation and to try to eliminate these syncs as much as possible to benefit compilation.
Conclusion
The post went over a recipe to optimize Flux for Hopper architectures using native PyTorch code. The recipe tries to balance between simplicity and performance. Other kinds of optimizations are also likely possible (such as using fused MLP kernels and fused adaptive LayerNorm kernels), but for the purpose of simplicity, we didn’t go over them.
Another crucial point is that GPUs with the Hopper architecture are generally costly. So, to provide reasonable speed-memory trade-offs on consumer GPUs, there are other (often `torch.compile`-compatible) options available in the Diffusers library, too. We invite you to check them here and here.
We invite you to try these techniques out on other models and share the results. Happy optimizing!