Amazon SageMaker Data Wrangler reduces the time to aggregate and prepare data for machine learning (ML) from weeks to minutes in Amazon SageMaker Studio. Data Wrangler can simplify your data preparation and feature engineering processes and help you with data selection, cleaning, exploration, and visualization. Data Wrangler has over 300 built-in transforms written in PySpark, so you can process datasets up to hundreds of gigabytes efficiently on the default instance, ml.m5.4xlarge.
However, when you work with datasets up to terabytes of data using built-in transforms, you might experience longer processing time or potential out-of-memory errors. Based on your data requirements, you can now use additional Amazon Elastic Compute Cloud (Amazon EC2) M5 instances and R5 instances. For example, you can start with a default instance (ml.m5.4xlarge) and then switch to ml.m5.24xlarge or ml.r5.24xlarge. You have the option of picking different instance types and finding the best trade-off of running cost and processing times. The next time you’re working on time series transformation and running heavy transformers to balance your data, you can right-size your Data Wrangler instance to run these processes faster.
When processing tens of gigabytes or even more with a custom Pandas transform, you might experience out-of-memory errors. You can switch from the default instance (ml.m5.4xlarge) to ml.m5.24xlarge, and the transform will finish without any errors. We thoroughly benchmarked and observed linear speedup as we increased instance size across a portfolio of datasets.
In this post, we share our findings from two benchmark tests to demonstrate how you can process larger and wider datasets with Data Wrangler.
Data Wrangler benchmark tests
Let’s review two tests we ran, aggregation queries and one-hot encoding, with different instance types using PySpark built-in transformers and custom Pandas transforms. Transformations that don’t require aggregation finish quickly and work well with the default instance type, so we focused on aggregation queries and transformations with aggregation. We stored our test dataset on Amazon Simple Storage Service (Amazon S3). This dataset’s expanded size is around 100 GB with 80 million rows and 300 columns. We used UI metrics to time benchmark tests and measure end-to-end customer-facing latency. When importing our test dataset, we disabled sampling. Sampling is enabled by default, and Data Wrangler only processes the first 100 rows when enabled.x

As we increased the Data Wrangler instance size, we observed a roughly linear speedup of Data Wrangler built-in transforms and custom Spark SQL. Pandas aggregation query tests only finished when we used instances larger than ml.m5.16xl, and Pandas needed 180 GB of memory to process aggregation queries for this dataset.
The following table summarizes the aggregation query test results.
| Instance | vCPU | Memory (GiB) | Data Wrangler built-in Spark transform time |
Pandas Time (Custom Transform) |
| ml.m5.4xl | 16 | 64 | 229 seconds | Out of memory |
| ml.m5.8xl | 32 | 128 | 130 seconds | Out of memory |
| ml.m5.16xl | 64 | 256 | 52 seconds | 30 minutes |
The following table summarizes the one-hot encoding test results.
| Instance | vCPU | Memory (GiB) | Data Wrangler built-in Spark transform time |
Pandas Time (Custom Transform) |
| ml.m5.4xl | 16 | 64 | 228 seconds | Out of memory |
| ml.m5.8xl | 32 | 128 | 130 seconds | Out of memory |
| ml.m5.16xl | 64 | 256 | 52 seconds | Out of memory |
Switch the instance type of a data flow
To switch the instance type of your flow, complete the following steps:
- On the Amazon SageMaker Data Wrangler console, navigate to the data flow that you’re currently using.
- Choose the instance type on the navigation bar.
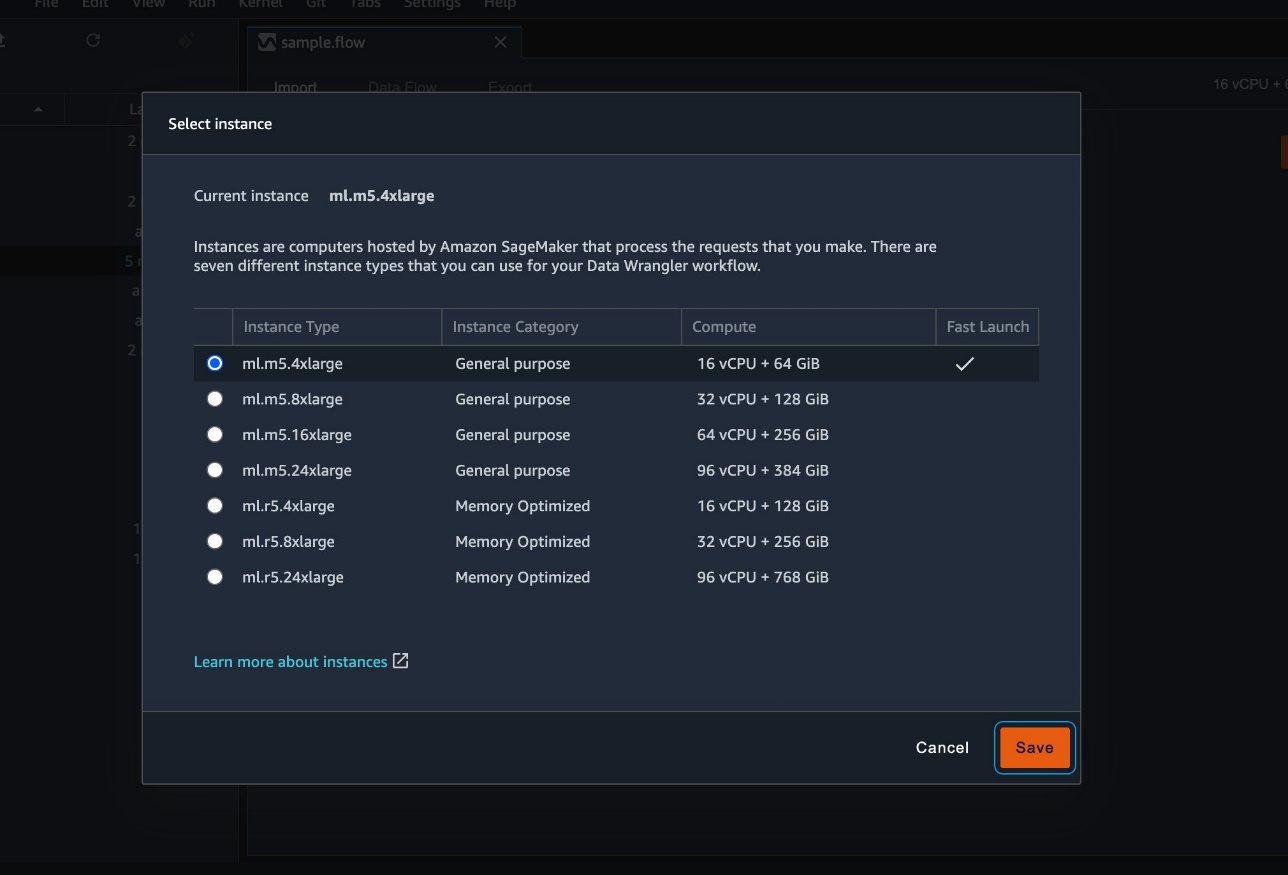
- Select the instance type that you want to use.
- Choose Save.
A progress message appears.

When the switch is complete, a success message appears.

Data Wrangler uses the selected instance type for data analysis and data transformations. The default instance and the instance you switched to (ml.m5.16xlarge) are both running. You can change the instance type or switch back to the default instance before running a specific transformation.
Shut down unused instances
You are charged for all running instances. To avoid incurring additional charges, shut down the instances that you aren’t using manually. To shut down an instance that is running, complete the following steps:
- On your data flow page, choose the instance icon in the left pane of the UI under Running instances.

- Choose Shut down.
If you shut down an instance used to run a flow, you can’t access the flow temporarily. If you get an error in opening the flow running an instance you previously shut down, wait for approximately 5 minutes and try opening it again.
Conclusion
In this post, we demonstrated how to process larger and wider datasets with Data Wrangler by switching instances to larger M5 or R5 instance types. M5 instances offer a balance of compute, memory, and networking resources. R5 instances are memory-optimized instances. Both M5 and R5 provide instance types to optimize cost and performance for your workloads.
To learn more about using data flows with Data Wrangler, refer to Create and Use a Data Wrangler Flow and Amazon SageMaker Pricing. To get started with Data Wrangler, see Prepare ML Data with Amazon SageMaker Data Wrangler.
About the Authors
 Haider Naqvi is a Solutions Architect at AWS. He has extensive software development and enterprise architecture experience. He focuses on enabling customers to achieve business outcomes with AWS. He is based out of New York.
Haider Naqvi is a Solutions Architect at AWS. He has extensive software development and enterprise architecture experience. He focuses on enabling customers to achieve business outcomes with AWS. He is based out of New York.
 Huong Nguyen is a Sr. Product Manager at AWS. She is leading the data ecosystem integration for SageMaker, with 14 years of experience building customer-centric and data-driven products for both enterprise and consumer spaces.
Huong Nguyen is a Sr. Product Manager at AWS. She is leading the data ecosystem integration for SageMaker, with 14 years of experience building customer-centric and data-driven products for both enterprise and consumer spaces.
 Meenakshisundaram Thandavarayan is a Senior AI/ML specialist with AWS. He helps hi-tech strategic accounts on their AI and ML journey. He is very passionate about data-driven AI.
Meenakshisundaram Thandavarayan is a Senior AI/ML specialist with AWS. He helps hi-tech strategic accounts on their AI and ML journey. He is very passionate about data-driven AI.
 Sriharsha M Sr is an AI/ML Specialist Solutions Architect in the Strategic Specialist team at Amazon Web Services. He works with strategic AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement AI/ML applications at scale. His expertise spans application architecture, big data, analytics, and machine learning.
Sriharsha M Sr is an AI/ML Specialist Solutions Architect in the Strategic Specialist team at Amazon Web Services. He works with strategic AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement AI/ML applications at scale. His expertise spans application architecture, big data, analytics, and machine learning.
 Nikita Ivkin is an Applied Scientist, Amazon SageMaker Data Wrangler.
Nikita Ivkin is an Applied Scientist, Amazon SageMaker Data Wrangler.