We are excited to announce the release of PyTorch 1.9. The release is composed of more than 3,400 commits since 1.8, made by 398 contributors. The release notes are available here. Highlights include:
- Major improvements to support scientific computing, including torch.linalg, torch.special, and Complex Autograd
- Major improvements in on-device binary size with Mobile Interpreter
- Native support for elastic-fault tolerance training through the upstreaming of TorchElastic into PyTorch Core
- Major updates to the PyTorch RPC framework to support large scale distributed training with GPU support
- New APIs to optimize performance and packaging for model inference deployment
- Support for Distributed training, GPU utilization and SM efficiency in the PyTorch Profiler
Along with 1.9, we are also releasing major updates to the PyTorch libraries, which you can read about in this blog post.
We’d like to thank the community for their support and work on this latest release. We’d especially like to thank Quansight and Microsoft for their contributions.
Features in PyTorch releases are classified as Stable, Beta, and Prototype. You can learn more about the definitions in this blog post.
Frontend APIs
(Stable) torch.linalg
In 1.9, the torch.linalg module is moving to a stable release. Linear algebra is essential to deep learning and scientific computing, and the torch.linalg module extends PyTorch’s support for it with implementations of every function from NumPy’s linear algebra module (now with support for accelerators and autograd) and more, like torch.linalg.matrix_norm and torch.linalg.householder_product. This makes the module immediately familiar to users who have worked with NumPy. Refer to the documentation here.
We plan to publish another blog post with more details on the torch.linalg module next week!
(Stable) Complex Autograd
The Complex Autograd feature, released as a beta in PyTorch 1.8, is now stable. Since the beta release, we have extended support for Complex Autograd for over 98% operators in PyTorch 1.9, improved testing for complex operators by adding more OpInfos, and added greater validation through TorchAudio migration to native complex tensors (refer to this issue).
This feature provides users the functionality to calculate complex gradients and optimize real valued loss functions with complex variables. This is a required feature for multiple current and downstream prospective users of complex numbers in PyTorch like TorchAudio, ESPNet, Asteroid, and FastMRI. Refer to the documentation for more details.
(Stable) torch.use_deterministic_algorithms()
To help with debugging and writing reproducible programs, PyTorch 1.9 includes a torch.use_determinstic_algorithms option. When this setting is enabled, operations will behave deterministically, if possible, or throw a runtime error if they might behave nondeterministically. Here are a couple examples:
>>> a = torch.randn(100, 100, 100, device='cuda').to_sparse()
>>> b = torch.randn(100, 100, 100, device='cuda')
# Sparse-dense CUDA bmm is usually nondeterministic
>>> torch.bmm(a, b).eq(torch.bmm(a, b)).all().item()
False
>>> torch.use_deterministic_algorithms(True)
# Now torch.bmm gives the same result each time, but with reduced performance
>>> torch.bmm(a, b).eq(torch.bmm(a, b)).all().item()
True
# CUDA kthvalue has no deterministic algorithm, so it throws a runtime error
>>> torch.zeros(10000, device='cuda').kthvalue(1)
RuntimeError: kthvalue CUDA does not have a deterministic implementation...
PyTorch 1.9 adds deterministic implementations for a number of indexing operations, too, including index_add, index_copy, and index_put with accum=False. For more details, refer to the documentation and reproducibility note.
(Beta) torch.special
A torch.special module, analogous to SciPy’s special module, is now available in beta. This module contains many functions useful for scientific computing and working with distributions such as iv, ive, erfcx, logerfc, and logerfcx. Refer to the documentation for more details.
(Beta) nn.Module parameterization
nn.Module parameterization allows users to parametrize any parameter or buffer of an nn.Module without modifying the nn.Module itself. It allows you to constrain the space in which your parameters live without the need for special optimization methods.
This also contains a new implementation of the spectral_norm parametrization for PyTorch 1.9. More parametrization will be added to this feature (weight_norm, matrix constraints and part of pruning) for the feature to become stable in 1.10. For more details, refer to the documentation and tutorial.
PyTorch Mobile
(Beta) Mobile Interpreter
We are releasing Mobile Interpreter, a streamlined version of the PyTorch runtime, in beta. The Interpreter will execute PyTorch programs in edge devices, with reduced binary size footprint.
Mobile Interpreter is one of the top requested features for PyTorch Mobile. This new release will significantly reduce binary size compared with the current on-device runtime. In order for you to get the binary size improvements with our interpreter (which can reduce the binary size up to ~75% for a typical application) follow these instructions. As an example, using Mobile Interpreter, we can reach 2.6 MB compressed with MobileNetV2 in arm64-v7a Android. With this latest release we are making it much simpler to integrate the interpreter by providing pre-built libraries for iOS and Android.
TorchVision Library
Starting from 1.9, users can use the TorchVision library on their iOS/Android apps. The Torchvision library contains the C++ TorchVision ops and needs to be linked together with the main PyTorch library for iOS, for Android it can be added as a gradle dependency. This allows using TorchVision prebuilt MaskRCNN operators for object detections and segmentation. To learn more about the library, please refer to our tutorials and demo apps.
Demo apps
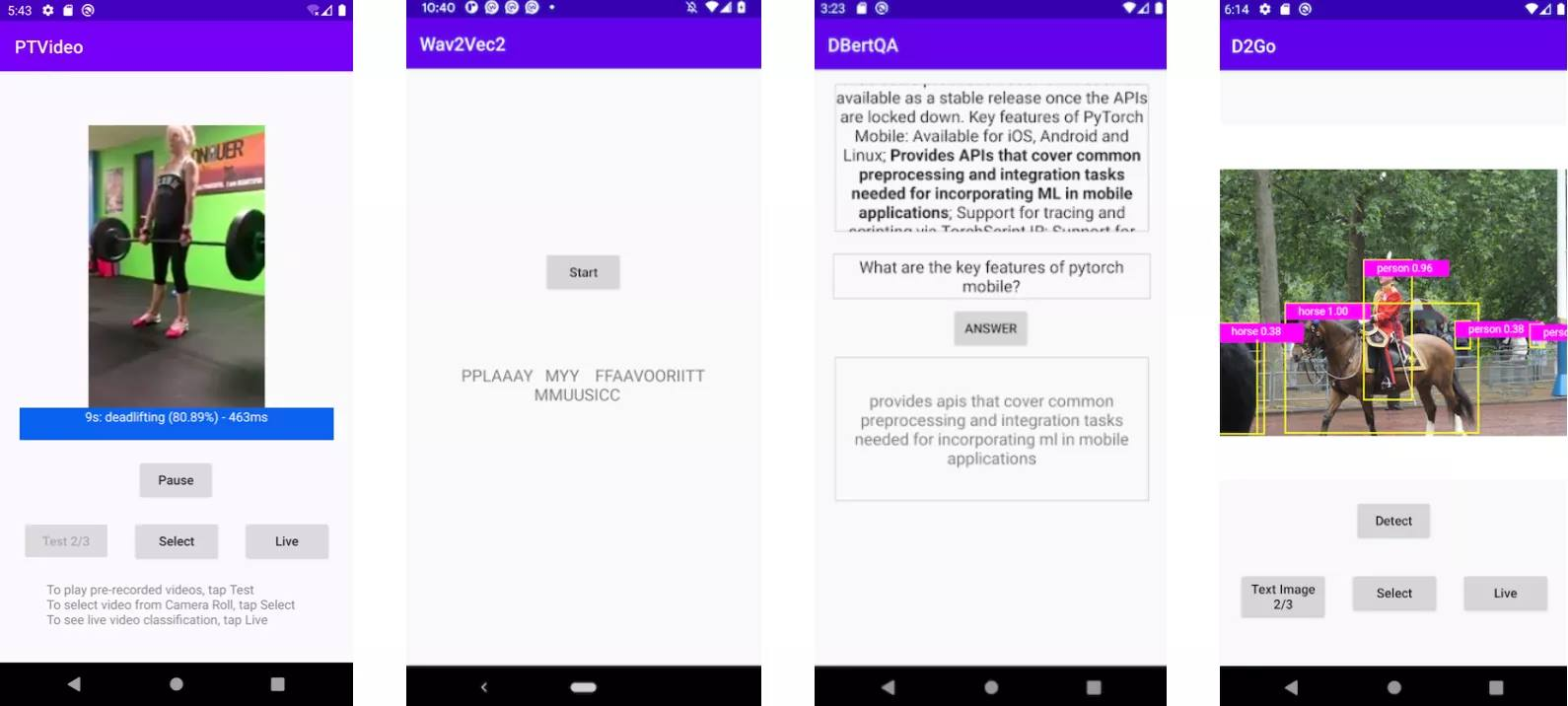
We are releasing a new video app based on PyTorch Video library and an updated speech recognition app based on the latest torchaudio, wave2vec model. Both are available on iOS and Android. In addition, we have updated the seven Computer Vision and three Natural Language Processing demo apps, including the HuggingFace DistilBERT, and the DeiT vision transformer models, with PyTorch Mobile v1.9. With the addition of these two apps, we now offer a full suite of demo apps covering image, text, audio, and video. To get started check out our iOS demo apps and Android demo apps.
Distributed Training
(Beta) TorchElastic is now part of core
TorchElastic, which was open sourced over a year ago in the pytorch/elastic github repository, is a runner and coordinator for PyTorch worker processes. Since then, it has been adopted by various distributed torch use-cases: 1) deepspeech.pytorch 2) pytorch-lightning 3) Kubernetes CRD. Now, it is part of PyTorch core.
As its name suggests, the core function of TorcheElastic is to gracefully handle scaling events. A notable corollary of elasticity is that peer discovery and rank assignment are built into TorchElastic enabling users to run distributed training on preemptible instances without requiring a gang scheduler. As a side note, etcd used to be a hard dependency of TorchElastic. With the upstream, this is no longer the case since we have added a “standalone” rendezvous based on c10d::Store. For more details, refer to the documentation.
(Beta) Distributed Training Updates
In addition to TorchElastic, there are a number of beta features available in the distributed package:
-
(Beta) CUDA support is available in RPC: Compared to CPU RPC and general-purpose RPC frameworks, CUDA RPC is a much more efficient way for P2P Tensor communication. It is built on top of TensorPipe which can automatically choose a communication channel for each Tensor based on Tensor device type and channel availability on both the caller and the callee. Existing TensorPipe channels cover NVLink, InfiniBand, SHM, CMA, TCP, etc. See this recipe for how CUDA RPC helps to attain 34x speedup compared to CPU RPC.
-
(Beta) ZeroRedundancyOptimizer: ZeroRedundancyOptimizer can be used in conjunction with DistributedDataParallel to reduce the size of per-process optimizer states. The idea of ZeroRedundancyOptimizer comes from DeepSpeed/ZeRO project and Marian, where the optimizer in each process owns a shard of model parameters and their corresponding optimizer states. When running
step(), each optimizer only updates its own parameters, and then uses collective communication to synchronize updated parameters across all processes. Refer to this documentation and this tutorial to learn more. -
(Beta) Support for profiling distributed collectives: PyTorch’s profiler tools, torch.profiler and torch.autograd.profiler, are able to profile distributed collectives and point to point communication primitives including allreduce, alltoall, allgather, send/recv, etc. This is enabled for all backends supported natively by PyTorch: gloo, mpi, and nccl. This can be used to debug performance issues, analyze traces that contain distributed communication, and gain insight into performance of applications that use distributed training. To learn more, refer to this documentation.
Performance Optimization and Tooling
(Stable) Freezing API
Module Freezing is the process of inlining module parameters and attributes values as constants into the TorchScript internal representation. This allows further optimization and specialization of your program, both for TorchScript optimizations and lowering to other backends. It is used by optimize_for_mobile API, ONNX, and others.
Freezing is recommended for model deployment. It helps TorchScript JIT optimizations optimize away overhead and bookkeeping that is necessary for training, tuning, or debugging PyTorch models. It enables graph fusions that are not semantically valid on non-frozen graphs – such as fusing Conv-BN. For more details, refer to the documentation.
(Beta) PyTorch Profiler
The new PyTorch Profiler graduates to beta and leverages Kineto for GPU profiling, TensorBoard for visualization and is now the standard across our tutorials and documentation.
PyTorch 1.9 extends support for the new torch.profiler API to more builds, including Windows and Mac and is recommended in most cases instead of the previous torch.autograd.profiler API. The new API supports existing profiler features, integrates with CUPTI library (Linux-only) to trace on-device CUDA kernels and provides support for long-running jobs, e.g.:
def trace_handler(p):
output = p.key_averages().table(sort_by="self_cuda_time_total", row_limit=10)
print(output)
p.export_chrome_trace("/tmp/trace_" + str(p.step_num) + ".json")
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
# schedule argument specifies the iterations on which the profiler is active
schedule=torch.profiler.schedule(
wait=1,
warmup=1,
active=2),
# on_trace_ready argument specifies the handler for the traces
on_trace_ready=trace_handler
) as p:
for idx in range(8):
model(inputs)
# profiler will trace iterations 2 and 3, and then 6 and 7 (counting from zero)
p.step()
More usage examples can be found on the profiler recipe page.
The PyTorch Profiler Tensorboard plugin has new features for:
- Distributed Training summary view with communications overview for NCCL
- GPU Utilization and SM Efficiency in Trace view and GPU operators view
- Memory Profiling view
- Jump to source when launched from Microsoft VSCode
- Ability for load traces from cloud object storage systems
(Beta) Inference Mode API
Inference Mode API allows significant speed-up for inference workloads while remaining safe and ensuring no incorrect gradients can ever be computed. It offers the best possible performance when no autograd is required. For more details, refer to the documentation for inference mode itself and the documentation explaining when to use it and the difference with no_grad mode.
(Beta) torch.package
torch.package is a new way to package PyTorch models in a self-contained, stable format. A package will include both the model’s data (e.g. parameters, buffers) and its code (model architecture). Packaging a model with its full set of Python dependencies, combined with a description of a conda environment with pinned versions, can be used to easily reproduce training. Representing a model in a self-contained artifact will also allow it to be published and transferred throughout a production ML pipeline while retaining the flexibility of a pure-Python representation. For more details, refer to the documentation.
(Prototype) prepare_for_inference
prepare_for_inference is a new prototype feature that takes in a module and performs graph-level optimizations to improve inference performance, depending on the device. It is meant to be a PyTorch-native option that requires minimal changes to user’s workflows. For more details, see the documentation for the Torchscript version here or the FX version here.
(Prototype) Profile-directed typing in TorchScript
TorchScript has a hard requirement for source code to have type annotations in order for compilation to be successful. For a long time, it was only possible to add missing or incorrect type annotations through trial and error (i.e., by fixing the type-checking errors generated by torch.jit.script one by one), which was inefficient and time consuming. Now, we have enabled profile directed typing for torch.jit.script by leveraging existing tools like MonkeyType, which makes the process much easier, faster, and more efficient. For more details, refer to the documentation.
Thanks for reading. If you’re interested in these updates and want to join the PyTorch community, we encourage you to join the discussion forums and open GitHub issues. To get the latest news from PyTorch, follow us on Facebook, Twitter, Medium, YouTube, or LinkedIn.
Cheers!
Team PyTorch