Key takeaways:
- PyTorch and vLLM are both critical to the AI ecosystem and are increasingly being used together for cutting-edge generative AI applications, including inference, post-training, and agentic systems at scale.
- With the shift of the PyTorch Foundation to an umbrella foundation, we are excited to see projects being both used and supported by a wide range of customers, from hyperscalers to startups and everyone in between.
- vLLM is leveraging the broader PyTorch ecosystem to accelerate innovation, benefiting from projects such as torch.compile, TorchAO, FlexAttention, and collaborating to support heterogeneous hardware and complex parallelism.
- The teams (and others) are collaborating to build out PyTorch native support and integration for large-scale inference and post-training.
Even prior to vLLM joining the PyTorch Foundation, we’ve seen organic and widespread adoption of PyTorch and vLLM together in some of the top companies deploying LLMs at scale in the world. Interestingly, the projects share many commonalities, including: strong visionary leaders; a broad organically-attained multilateral governance structure with committers from several entities, including both industry and academia; and an overwhelming focus on the developer experience.
Additionally, over the last year plus, we’ve seen the two projects underpin many of the most popular open source LLMs, including the various Llama and DeepSeek models. With such similarities and how complementary the projects are, it’s really exciting to see all of the different integration points.
PyTorch → vLLM Integrations
The overall goal for integrating at various points is to unlock performance and bring new capabilities to users. This includes optimization and support for Llama models, but also broader open models.
torch.compile: torch.compile is a compiler that optimizes PyTorch code, delivering fast performance with minimal user effort. While manually tuning a model’s performance can take days, weeks, or even months, this approach becomes impractical for a large number of models. Instead, torch.compile provides a convenient solution for optimizing model performance. vLLM uses torch.compile by default to generate optimized kernels for the majority of its models. Recent benchmarks show significant speedups with torch.compile, ranging from 1.05x to 1.9x speedups on CUDA for popular models like Llama4, Qwen3, and Gemma3.
TorchAO: We’re excited to announce that TorchAO is now officially supported as a quantization solution in vLLM. This integration brings high-performance inference capabilities using Int4, Int8, and FP8 data types, with upcoming support for MXFP8, MXFP4, and NVFP4 optimizations specifically designed for B200 GPUs. Additionally, we’re working on planned FP8 inference support for AMD GPUs, expanding hardware compatibility for high-performance quantized inference.
TorchAO’s quantization APIs are powered by a robust collection of high-performance kernels, including those from PyTorch Core, FBGEMM, and gemlite. TorchAO techniques are designed to compose torch.compile. This means simpler implementations and automatic performance gains from PT2. Write less code, get better performance
One of the most exciting aspects of this integration is the seamless workflow it enables: vLLM users can now perform float8 training using TorchTitan, Quantization-Aware Training (QAT) using TorchTune, then directly load and deploy their quantized models through vLLM for production inference. This end-to-end pipeline significantly streamlines the path from model training and fine-tuning to deployment, making advanced quantization techniques more accessible to developers.
FlexAttention: vLLM now includes FlexAttention – a new attention backend designed for flexibility. FlexAttention provides a programmable attention framework that allows developers to define custom attention patterns, making it easier to support novel model designs without extensive backend modifications.
This backend, enabled by torch.compile, produces JIT fused kernels. This allows for flexibility while maintaining performance for non-standard attention patterns. FlexAttention is currently in early development within vLLM and not yet ready for production use. We’re continuing to invest in this integration and plan to make it a robust part of vLLM’s modeling toolkit. The goal is to simplify support for emerging attention patterns and model architectures, making it easier to bridge the gap between research innovations and deployment-ready inference.
Heterogeneous hardware: The PyTorch team worked with different hardware vendors and provided solid support for different types of hardware backends, including NVIDIA GPU, AMD GPU, Intel GPU, Google TPU, etc. vLLM inference engine leverages PyTorch as a proxy talking to different hardware, and this significantly simplified the support for heterogeneous hardware.
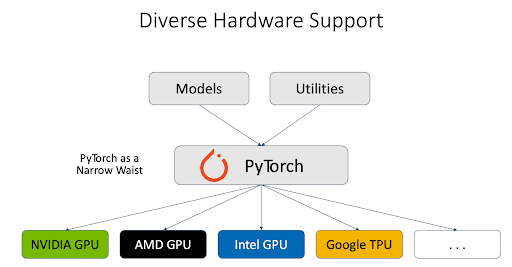
In addition, PyTorch engineers work closely with other vLLM contributors to support the next generation of NVIDIA GPUs. For example, we have thoroughly tested FlashInfer support in vLLM on Blackwell, conducted performance comparison, and debugged accuracy issues.
The PyTorch team also worked with AMD to enhance the support for vLLM + Llama4, such as day 0 llama 4 support on AMD as well as Llama4 perf optimization on MI300x.
Parallelism: At Meta, we leverage different types of parallelism and their combination in production. Pipeline parallelism (PP) is one important type. The original PP in vLLM has hard dependencies on Ray. However, not all the users leverage Ray to manage their service and coordinate different hosts. The PyTorch team developed the PP with plain torchrun support, and further optimized its approach to overlap the computation between microbatches. In addition, PyTorch engineers also developed the Data Parallelism for vision encoder, which is critical to the multi-modal models’ performance.
Continuous integration (CI): With vLLM critical for the PyTorch ecosystem, we are collaborating to ensure that CI between the projects has good test coverage, is well funded and overall the community can rely on all of these integrations. Just integrating APIs isn’t enough; it’s also important that CI is in place to ensure that nothing breaks over time as vLLM and PyTorch both release new versions and features. More concretely, we are testing the combination of vLLM main and PyTorch nightlies, which we believe will give us and the community the signal needed to monitor the state of the integration between the two projects. At Meta, we started moving some of our development effort on top of vLLM main to stress test various correctness and performance aspects of vLLM. As well, performance dashboards for vLLM v1 are now available on hud.pytorch.org.
What’s next..
This is just the beginning. We are working together to build out the following advanced capabilities:
1. Large Scale Model Inference: The primary goal is to ensure vLLM runs efficiently at scale on cloud offerings, demonstrates key capabilities (prefill-decode disagg, multi-node parallelism, performant kernels and comms, context-aware routing and fault-tolerance) to scale to thousands of nodes, and becomes a stable foundation for enterprises to build on. In Q2, Meta engineers have prototyped disagg integration on top of the vLLM engine and KV connector APIs. The team is working with the community to try out new strategies and will plan to upstream the most successful ones to push further what can be done with vLLM.
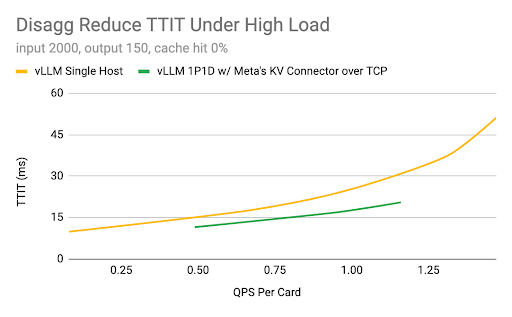
Hardware: H100 GPUs, 96 GB HBM2e, AMD Genoa CPUs, CUDA 12.4
2. Post-training with reinforcement learning: Inference time compute is quickly becoming critical for LLMs and agentic systems. We are working on end-to-end native post-training that incorporates RL at large scale with vLLM as the inference backbone of the system.
Cheers!
-Team PyTorch (at Meta) & Team vLLM