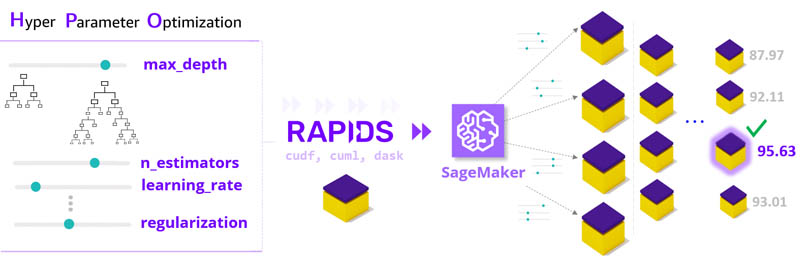
In this post, we combine the powers of NVIDIA RAPIDS and Amazon SageMaker to accelerate hyperparameter optimization (HPO). HPO runs many training jobs on your dataset using different settings to find the best-performing model configuration.
HPO helps data scientists reach top performance, and is applied when models go into production, or to periodically refresh deployed models as new data arrives. However, HPO can feel out of reach on non-accelerated platforms as dataset sizes continue to grow.
With RAPIDS and SageMaker working together, workloads like HPO are GPU scaled up (multi-GPU) within a node and cloud scaled out over parallel instances. With this collaboration of technologies, machine learning (ML) jobs like HPO complete in hours instead of days, while also reducing costs.
The Amazon Packaging Experience Team (CPEX) recently found similar speedups using our HPO demo framework on their gradient boosted models for selecting minimal packaging materials based on product features. For more information about their relentless quest to shrink packaging and reduce waste with AI, see Inside Amazon’s quest to use less cardboard.
Getting started
We encourage you to get hands-on and launch a SageMaker notebook so you can replicate this demo or use your own dataset. This RAPIDS with SageMaker HPO example is part of the amazon-sagemaker-examples GitHub repository, which is integrated into the SageMaker UX, making it very simple to launch. We also have a video walkthrough of this material.
The key ingredients for cloud HPO are a dataset, a RAPIDS ML workflow containerized as a SageMaker estimator, and a SageMaker HPO tuner definition. We go through each element in order and provide benchmarking results.
Dataset
Our hope is that you can use your own dataset for this walkthrough, so we’ve tried to make this easy by supporting any tabular dataset as input, such as Parquet or CSV format, stored on Amazon Simple Storage Service (Amazon S3).
For this post, we use the dataset to set up a classification workflow for whether a flight will arrive more than 15 minutes late. This dataset has been collected by the US Bureau of Transportation for over 30 years and includes 14 features (such as distance, source, origin, carrier ID, and scheduled vs. actual departure and arrival).
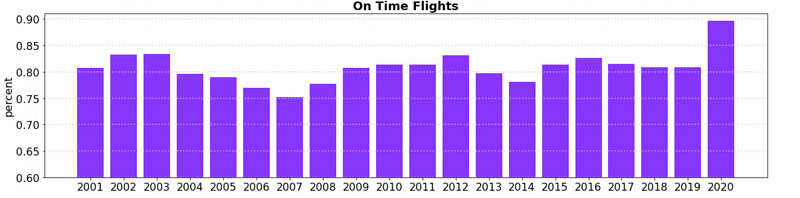
The following graph shows that for the past 20 years, 81% of flights arrived on time—meaning less than 15 minutes late to arrive at their destination. 2020 is at 90% due to less congestion in the sky.
The following graph shows the number of domestic US flights (in millions) for the last 20 years. We can see that although 2020 counts have only been reported through September, the year is going to come in below the running average.

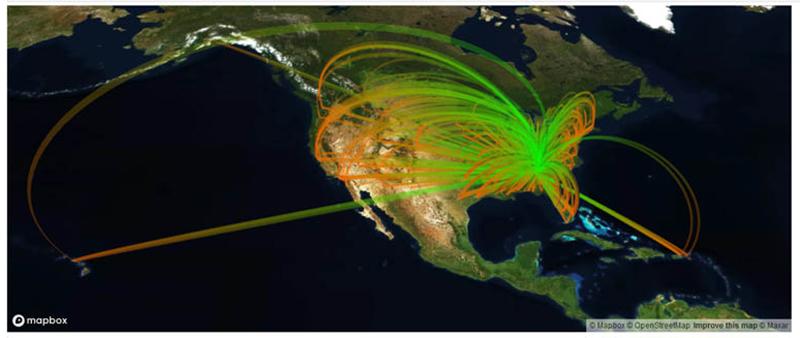
The following image shows 10,000 flights out of Atlanta. The arch height represents delays. Flights out of most airports arrive late when covering a great distance. Atlanta is an outlier, with delays common even for short flights.
SageMaker estimator
Now that we have our dataset, we build a RAPIDS ML workflow and package it using the SageMaker Training API into an interface called an estimator. Our estimator is essentially a container image that holds our code as well as some additional software (sagemaker-training-toolkit), which helps make sure everything is correctly hooking up to the AWS Cloud. SageMaker uses our estimator image as a way to deploy the same logic to all the parallel instances that participate in the HPO search process.
RAPIDS ML workflow
For this post, we built a lightweight RAPIDS ML workflow that doesn’t delve into data augmentation or feature engineering, but rather offers the bare essentials so that everything is simple and the focus remains on HPO. The steps of the workflow include data ingestion, model training, prediction, and scoring.
We offer four variations of the workflow, which unlock increasing amounts of parallelism and allow for experimentation with different libraries and instance types. The curious reader is welcome to dive into the code for each option:
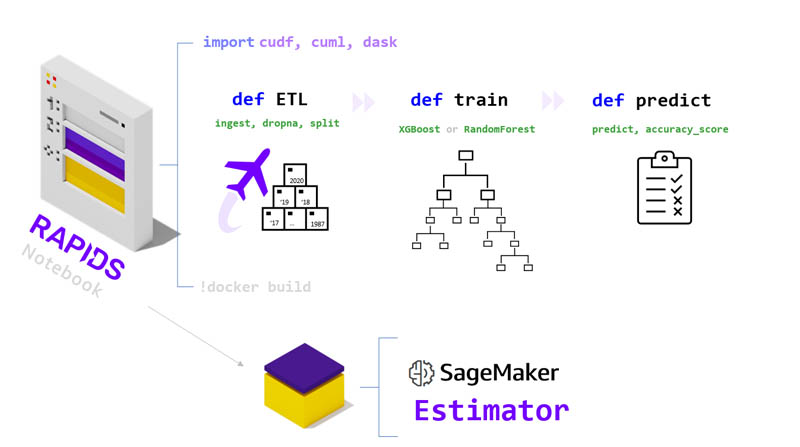
At a high level, all the workflows accomplish the same goal, however in the GPU case, we replace the CPU Pandas and CPU SKLearn libraries with RAPIDS cuDF and cuML, respectively. Because the dataset scales into very large numbers of samples (over 10 years of airline data), we recommend using the multi-CPU and multi-GPU workflows, which add Dask and enable data and computation to be distributed among parallel workers. Our recommendations are captured in the notebook, which offers an on-the-fly instance type recommendation based on the choice of CPU vs. GPU as well as dataset size.
HPO tuning
Now that we have our dataset and estimator prepared, we can turn our attention to defining how we want the hyperparameter optimization process to unfold. Specifically, we should now decide on the following:
- Hyperparameter ranges
- The strategy for searching through the ranges
- How many experiments to run in parallel and the total experiments to run
Hyperparameter ranges
The hyperparameter ranges are at the heart of HPO. Choosing large ranges for parameters allows the search to consider many model configurations and increase its probability of finding a champion model.
In this post, we focus on tuning model size and complexity by varying the maximum depth and the number of trees for XGBoost and Random Forest. To guard against overfitting, we use cross-validation so that each configuration is retested with different splits of the train and test data.
Search strategy
In terms of HPO search strategy, SageMaker offers Bayesian and random search. For more information, see How Hyperparameter Tuning Works. For this post, we use the random search strategy.
HPO sizing
Lastly, in terms of sizing, we set the notebook defaults to a relatively small HPO search of 10 experiments, running two at a time so that everything runs quickly end-to-end. For a more realistic use case, we used the same code but ramped up the number of experiments to 100, which is what we have benchmarked in the next section.
Results and benchmarks
In our benchmarking, we tested 100 XGBoost HPO runs with 10 years of the airline dataset (approximately 60 million flights). On the ml.p3.8xlarge 4x Volta100 GPU instances, we see a 14 times reduction (over 3 days vs. 6 hours) and a 4.5 times cost reduction vs. the ml.m5.24xlarge instances.
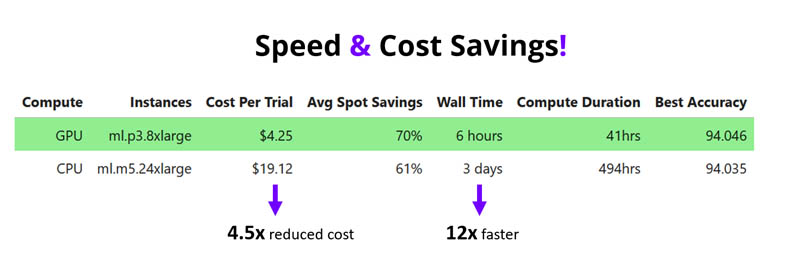
Production grade HPO jobs running on the CPU may time out because they exceed the 24-hour runtime limit we added as a safeguard (in our run, 12 out of 100 CPU jobs were stopped).
As a final benchmarking exercise to showcase what’s happening on each training run, we show an example of a single fold of cross-validation on the entire airline dataset (33 years going back to 1987) for both XGBoost and Random Forest with a middle-of-the-pack model complexity (max_depth is 15, n_estimators is 500).

We can see the computational advantage of the GPU for model training and how this advantage grows along with the parallelism inherent in the algorithm used (Random Forest is embarrassingly parallel, whereas XGBoost builds trees sequentially).

Deploying our best model with the Forest Inference Library
As a final touch, we also offer model serving. This is done in the serve.py code, where a Flask server loads the best model found during HPO and uses the Forest Inference Library (FIL) for GPU-accelerated large batch inference. The FIL works for both XGBoost and Random Forest, and can be 28 times faster relative to CPU-based inference.
Conclusion
We hope that after reading this post, you’re inspired to try combining RAPIDS and SageMaker for HPO. We’re sure you’ll benefit from the tremendous acceleration made possible by GPUs at cloud scale. AWS also recently launched the Ampere100 GPUs in the form of p4d instances, which are the fastest ML nodes in the cloud, and should be coming to SageMaker soon.
At NVIDIA and AWS, we hope to continue working to democratize high performance computing both in terms of ease of use (such as SageMaker notebooks that spawn large compute workloads) and in terms of total cost of ownership. If you run into any issues, let us know via GitHub. You can also get in touch with us via Slack, Google Groups, or Twitter. We look forward to hearing from you!
About the Authors
Wenming Ye is an AI and ML specialist architect at Amazon Web Services, helping researchers and enterprise customers use cloud-based machine learning services to rapidly scale their innovations. Previously, Wenming had a diverse R&D experience at Microsoft Research, SQL engineering team, and successful startups.
Miro Enev, PhD is a Principal Solution Architect at NVIDIA.