Posted by Michael Brooks, Coral
For over 3 years, Coral has been focused on enabling privacy-preserving Edge ML with low-power, high performance products. We’ve released many examples and projects designed to help you quickly accelerate ML for your specific needs. One of the most common requests we get after exploring the Coral models and projects is: How do we move to production?
With this in mind we’re introducing the first of our use-case specific demos. These demos are intended to to take full advantage of the Coral Edge TPU™ with high performance, production-quality code that is easily customizable to meet your ML requirements. In this demo we focus on use cases that are specific to manufacturing; worker safety and quality grading / visual inspection.
Demo Overview
The Coral manufacturing demo targets a x86 or powerful ARM64 system with OpenGL acceleration that processes and displays two simultaneous inputs. The default demo, using the included example videos, looks like this:

The two examples being run are:
- Worker Safety: Performs generic person detection (powered by COCO-trained SSDLite MobileDet) and then runs a simple algorithm to detect bounding box collisions to see if a person is in an unsafe region.
- Visual Inspection: Performs apple detection (using the same COCO-trained SSDLite MobileDet from Worker Safety) and then crops the frame to the detected apple and runs a retrained MobileNetV2 that classifies fresh vs rotten apples.
By combining these two examples, we are able to demonstrate multiple Coral features that can enable this processing, including:
- Co-compilation
- Cascading models (using the output of one model to feed another)
- Classification retraining
- Real time processing of multiple inputs
Creating The Demo
When designing a new ML application, it is critical to ensure that you can meet your latency and accuracy requirements. With the two applications described here, we went through the following process to choose models, train these models, and deploy to the EdgeTPU – this process should be used when beginning any Coral application.
Choosing the Models
When deciding on a model to use, the new Coral Model Page is the best place to start. For this demo, we know that we need a detection model (which will be used for detection of both people and apples) as well as a classification model.
Detection
When picking a detection model from the Detection Model Page, there are four aspects to a model we want to look for:
- Training Dataset: In the case of the models page, all of our normal detection models use the COCO dataset. Referring to the labels, we can find both apples and people, so we can use just the one model for both detection tasks.
- Latency: We will need to run at least 3 inferences per frame and need this to keep up with our input (30 FPS). This means we need our detection to be as fast as possible. From the models page, we can see two good options: SSD MobileNet v2 (7.4 ms) and MobileDet (8.0 ms). This is the first point where we see the clear advantage of Coral – looking at the benchmarks at the bottom of our x86+USB CTS Output we can see even on a powerful workstation this would be 90 ms and 123 ms respectively.
- Accuracy/Precision: We also want as accurate a model as possible. This is evaluated using the primary challenge metric from COCO evaluation metrics. We see here MobileDet (32.8%) clearly outpeforms MobileNet V2 (25.7%).
- Size: In order to fully co-compile this detection model with the classification model below, we need to ensure that we can fit both models in the 8MB of cache on the Edge TPU. This means we want as small a model as possible. MobileDet is 5.1 MB vs MobileNet V2 is 6.6 MB.
With the above considerations, we chose SSDLite MobileDet.
Classification
For the fresh-or-rotten apple classification, there are many more options on the Coral Classification Page. What we want to check is the same:
- Training Dataset: We’ll be retraining on our new dataset, so this isn’t critical in this application.
- Latency: We want the classification to be as fast as possible. Luckily many of the models on our page are extremely fast relative to the 30 FPS frame rate we demand. With this in mind we can eliminate all the Inception models and ResNet-50.
- Accuracy: Accuracy for Top-1 and Top-5 is provided. We want to be as accurate as possible for Top-1 (since we are only checking fresh vs rotten) – but still need to consider latency. With this in mind we eliminate MobileNet v1.
- Size: As mentioned above, we want to ensure we can fit both the detection and classification models (or as much as possible) so we can easily eliminate the EfficientNet options.
This leaves us with MobileNet v2 and MobileNet v3. We opted for v2 due to existing tutorials on retraining this model.
Retraining Classification
With the model decisions taken care of, now we need to retain the classification model to identify fresh and rotten apples. Coral.ai offers training tutorials in CoLab (uses post-training quantization) and Docker (uses quantization aware training) formats – but we’ve also included the retraining python script in this demo’s repo.
Our Fresh/Rotten data comes from the “Fruits fresh and rotten for classification” dataset – we simply omit everything but apples.
In our script, we first load the standard Keras MobileNetV2 – freezing the first 100 layers and adding a few extra layers at the end:
base_model = tf.keras.applications.MobileNetV2(input_shape=input_shape,
include_top=False,
classifier_activation='softmax',
weights='imagenet')
# Freeze first 100 layers
base_model.trainable = True
for layer in base_model.layers[:100]:
layer.trainable = False
model = tf.keras.Sequential([
base_model,
tf.keras.layers.Conv2D(filters=32, kernel_size=3, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(units=2, activation='softmax')
])
model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.RMSprop(lr=1e-5),
metrics=['accuracy'])
print(model.summary())Next, with the dataset download into ./dataset we train our model:
train_datagen = ImageDataGenerator(rescale=1./255,
zoom_range=0.3,
rotation_range=50,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
dataset_path = './dataset'
train_set_path = os.path.join(dataset_path, 'train')
val_set_path = os.path.join(dataset_path, 'test')
batch_size = 64
train_generator = train_datagen.flow_from_directory(train_set_path,
target_size=input_size,
batch_size=batch_size,
class_mode='categorical')
val_generator = val_datagen.flow_from_directory(val_set_path,
target_size=input_size,
batch_size=batch_size,
class_mode='categorical')
epochs = 15
history = model.fit(train_generator,
steps_per_epoch=train_generator.n // batch_size,
epochs=epochs,
validation_data=val_generator,
validation_steps=val_generator.n // batch_size,
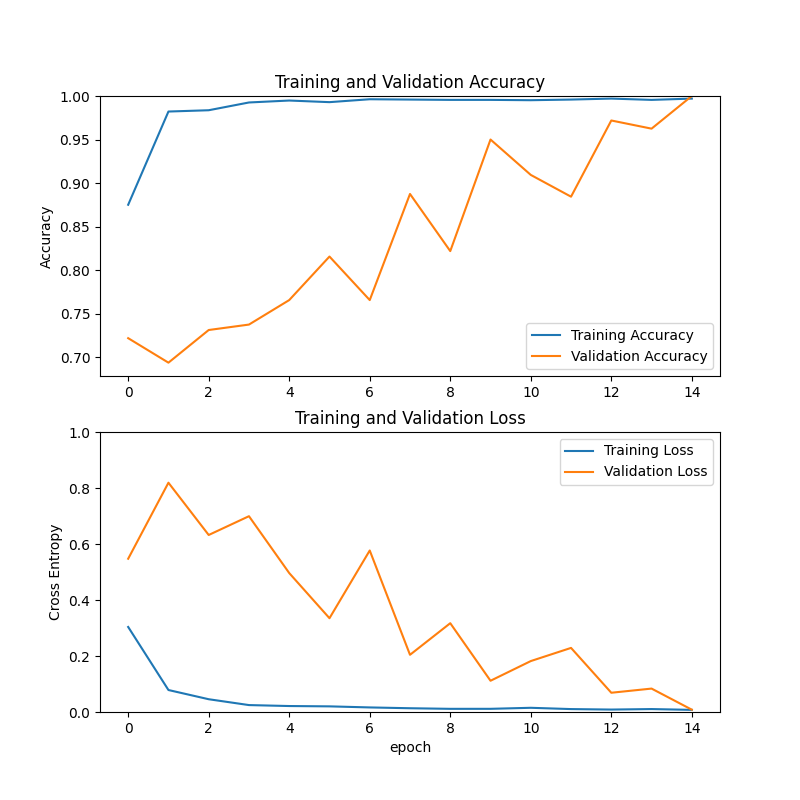
verbose=1)Note that we’re only using 15 epochs. When retraining on another dataset it is very likely more will be required. With the apple dataset, we can see this model quickly hits very high accuracy numbers:
For your own dataset and model more epochs will likely be needed (the script will generate the above plots for validation).
We now have a Keras model that works for our apple quality inspector. In order to run this on a Coral Edge TPU, the model must be quantized and converted to TF Lite. We’ll do this using post-training quantization – quantizing based on a representative dataset after training:
def representative_data_gen():
dataset_list = tf.data.Dataset.list_files('./dataset/test/*/*')
for i in range(100):
image = next(iter(dataset_list))
image = tf.io.read_file(image)
image = tf.io.decode_jpeg(image, channels=3)
image = tf.image.resize(image, input_size)
image = tf.cast(image / 255., tf.float32)
image = tf.expand_dims(image, 0)
yield [image]
model.input.set_shape((1,) + model.input.shape[1:])
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_data_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = [tf.int8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_model = converter.convert()The script will then compile the model and evaluate both the Keras and TF Lite models – but we’ll need to take one extra step beyond the script: We must use the Edge TPU Compiler to co-compile the classification model with our detection model.
Co-compiling the models
We now have two quantized TF Lite models: classifier.tflite and the default CPU model for MobileDet taken from the Coral model page. We can compile them together to ensure that they share the same caching token – when either model is requested the parameter data will already be cached. This simply requires passing both models to the compiler:
edgetpu_compiler ssdlite_mobiledet_coco_qat_postprocess.tflite classifier.tflite
Edge TPU Compiler version 15.0.340273435
Models compiled successfully in 1770 ms.
Input model: ssdlite_mobiledet_coco_qat_postprocess.tflite
Input size: 4.08MiB
Output model: ssdlite_mobiledet_coco_qat_postprocess_edgetpu.tflite
Output size: 5.12MiB
On-chip memory used for caching model parameters: 4.89MiB
On-chip memory remaining for caching model parameters: 2.74MiB
Off-chip memory used for streaming uncached model parameters: 0.00B
Number of Edge TPU subgraphs: 1
Total number of operations: 125
Operation log: ssdlite_mobiledet_coco_qat_postprocess_edgetpu.log
Model successfully compiled but not all operations are supported by the Edge TPU. A percentage of the model will instead run on the CPU, which is slower. If possible, consider updating your model to use only operations supported by the Edge TPU. For details, visit g.co/coral/model-reqs.
Number of operations that will run on Edge TPU: 124
Number of operations that will run on CPU: 1
See the operation log file for individual operation details.
Input model: classifier.tflite
Input size: 3.07MiB
Output model: classifier_edgetpu.tflite
Output size: 3.13MiB
On-chip memory used for caching model parameters: 2.74MiB
On-chip memory remaining for caching model parameters: 0.00B
Off-chip memory used for streaming uncached model parameters: 584.06KiB
Number of Edge TPU subgraphs: 1
Total number of operations: 72
Operation log: classifier_edgetpu.log
See the operation log file for individual operation details.There are two things to note in this log. First is that we see one operation is run on the CPU for the detection model – this is expected. The TF Lite SSD PostProcess will always run on CPU. Second, we couldn’t quite fit everything on the on-chip memory, the classifier has 584 kB of off-chip memory needed. This is fine – we’ve substantially reduced the amount of IO time needed. Both models will now be in the same folder, but because we co-compiled them they are aware of each other and the cache will persist parameters for both models.
Customizing For Your Application
The demo is optimized and ready for customization and deployment. It can be cross compiled for other architectures (currently it’s only for x86 or ARM64) and statically links libedgetpu to allow this binary to be deployed to many different Linux systems with an Edge TPU.
There are many things that can be done to customize the model to your application:
- The quickest changes are the inputs, which can be adjusted via the
--visual_inspection_inputand--worker_safety_inputflags. The demo accepts mp4 files and V4L2 camera devices. - The worker safety demo can be further improved with more complicated keepout algorithms (including consideration of angle/distance from camera) as well as retraining on overhead data. Currently the demo checks only the bottom of the bounding box, but the flag
--safety_check_whole_boxcan be used to compare to the whole box (for situations like overhead cameras). - The apple inspection demonstrates simple quality grading / inspection – this cascaded model approach (using detection to determine bounding boxes and feeding into another model) can be applied to many different uses. By retraining the detection and classification model this can be customized for your application.
Conclusion
The Coral Manufacturing Demo demonstrates how Coral can be used in a production environment to solve multiple ML needs. The Coral accelerator provides a low-cost and low-power way to add enough ML compute to run both tasks in parallel without over-burdening the host. We hope that you can use the Coral Manufacturing Demo as a starting point to bringing Coral intelligence into your own manufacturing environment.
To learn more about ways edge ML can be used to benefit day to day operations across a variety of industries, visit our Industries page. For more information about Coral Products and Partner products with Coral integrated, please visit us at Coral.ai.