Amazon Kendra offers highly accurate semantic and natural language search powered by machine learning (ML).
Many organizations use GitHub as a code hosting platform for version control and to redefine collaboration of open-source software projects. A GitHub account repository might include many content types, such as files, issues, issue comments, issue comment attachments, pull requests, pull request comments, pull request comment attachments, and more. This corpus data is scattered across multiple locations and content repositories (public, private, and internal) within an organization. However, surfacing the relevant information in a traditional keyword search is ineffective. You can now use the new Amazon Kendra data source for GitHub to index specific content types and easily find information from this data. The GitHub data source syncs the data in your GitHub repositories to your Amazon Kendra index.
This post guides you through the step-by-step process to configure the Amazon Kendra connector for GitHub. We also show you how to configure for the connector both GitHub Enterprise Cloud (SaaS) and GitHub Enterprise Server (on premises) services.
Solution overview
The solution consists of the following high-level steps:
- Set up your GitHub enterprise account.
- Set up a GitHub repo.
- Create a GitHub data source connector.
- Search the indexed content.
Prerequisites
You need the following prerequisites to set up the Amazon Kendra connector for GitHub:
- An AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies. For more information, see Overview of access management: Permissions and policies.
- Basic knowledge of AWS and working knowledge of GitHub enterprise products. For more details, see Getting started with GitHub Enterprise Cloud and Getting started with GitHub Enterprise Server.
- Enterprise owner or administrator access to a GitHub enterprise account.
- Personal access tokens for authentication to GitHub. For more information, refer to Creating an OAuth App, Authorizing OAuth Apps, and Scopes for OAuth Apps.
- An AWS Secrets Manager secret to store your GitHub authentication credentials. For more information, see Using a GitHub data source.
Set up your GitHub enterprise account
Create an enterprise account before proceeding to the next steps. For authentication, you can specify two types of tokens while configuring the GitHub connector:
- Personal access token – Direct API requests that you authenticate with a personal access token are user-to-server requests. User-to-server requests are limited to 5,000 requests per hour and per authenticated user. Your personal access token is also an OAuth token.
- OAuth token – With this token, the requests are subject to a higher limit of 15,000 requests per hour and per authenticated user.
Our recommendation is to use an OAuth token for better API throttle limits and connector performance.
For this post, we assume you have an enterprise account and generated OAuth token.
Set up your GitHub repo
To configure your GitHub repo, complete the following steps:
- Create a new repository, and specify its owner and name.
- Choose if the repository is public, internal, or private.
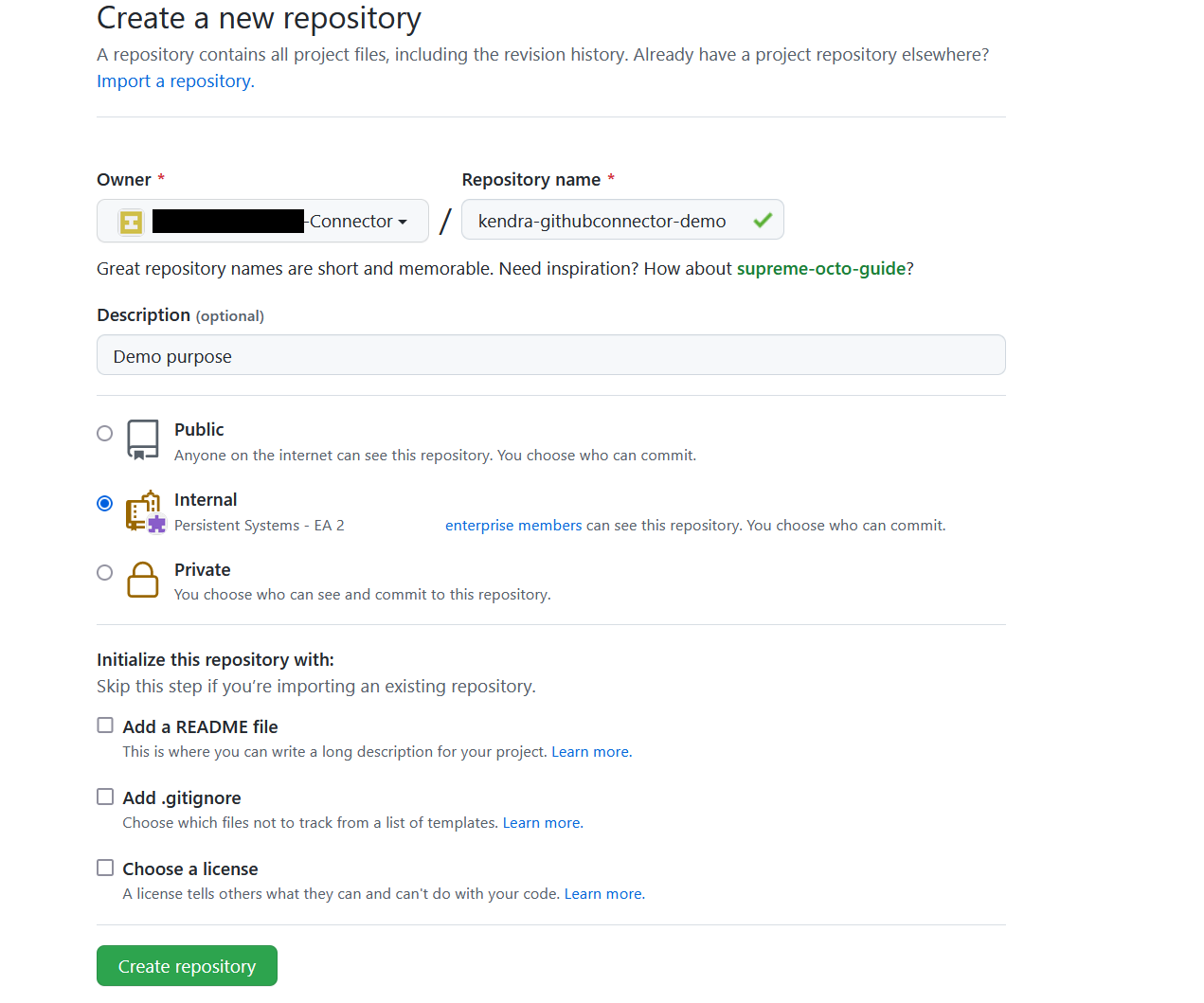
- For this post, update the README file with the following text:
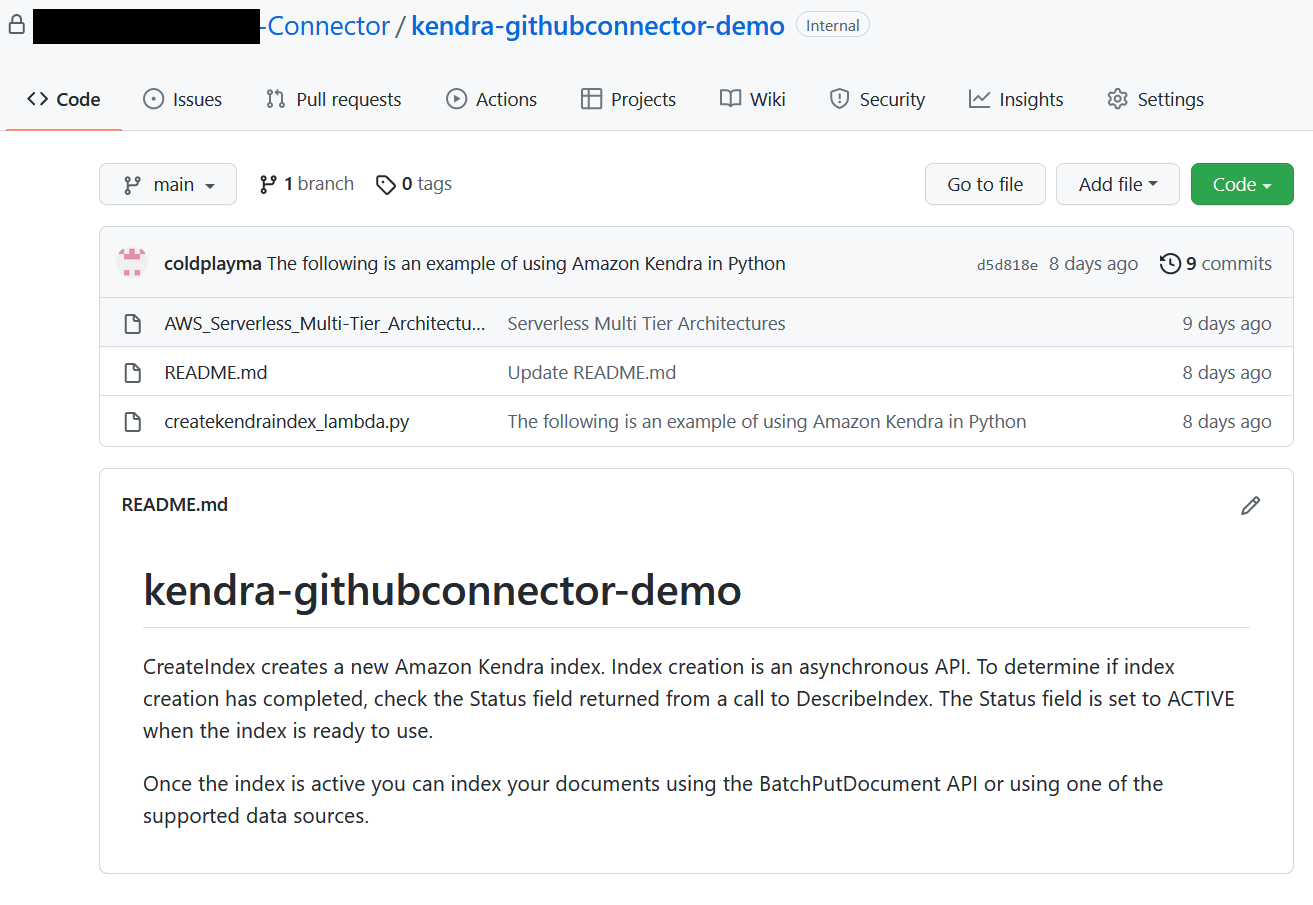
- You can add a sample file to your repository with commit changes. The following is an example of using Amazon Kendra in Python:
- Download AWS_Whitepapers.zip to your computer, and extract the files into a folder called
AWS_Whitepapers. - Upload
AWS_Whitepapers/Best_Practices/AWS_Serverless_Multi-Tier_Architecturesto your repository.
Your repository should look like the following screenshot.
Your organization’s code repositories might hold hundreds of thousands of documents, README notes, code comments, webpages, and other items. In the next section, we showcase the document comprehension capability of Amazon Kendra to find the relevant information contained in these repositories.
Create a GitHub data source connector
For this post, we assume you have already created an Amazon Kendra index. If you don’t have an index, create a new index before proceeding with the following steps.
- On the Amazon Kendra console, choose the index that you want to add the data source to.
- Choose Add data sources.
- From the list of data source connectors, choose Add connector under GitHub.

- On the Specify data source details page, enter a data source name and an optional description.
- To assign metadata to your AWS resources in the form of tags, choose Add tags and enter a key and value.
- Choose Next.

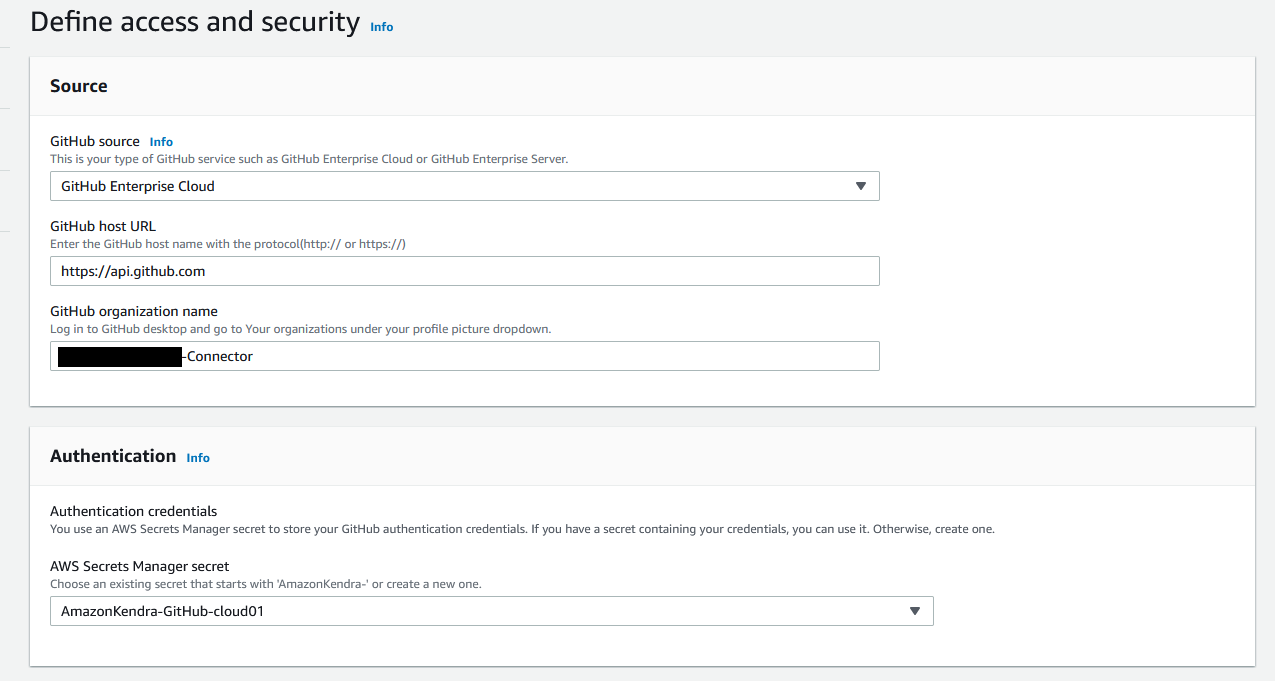
- On the Define access and security page, choose your GitHub source. Amazon Kendra supports two types of GitHub services:
-
GitHub Enterprise Cloud – If you choose this option, specify the GitHub host URL and GitHub organization name. Configure your Secrets Manager secret with the authentication credentials in the form of an OAuth2 access token of the GitHub enterprise owner. The Oauth2 token scope should be authorized for
repo:status,public_repo,repo:invite,read:org,user:email, andread:user.
-
GitHub Enterprise Server – If you choose this option, specify the GitHub host URL and GitHub organization name you created in the previous section. Configure your Secrets Manager secret with the authentication credentials in the form of an OAuth2 access token of the GitHub enterprise owner. The Oauth2 token scope should be authorized for
repo:status,public_repo,repo:invite,read:org,user:email,read:user, andsite_admin. To configure the SSL certificate, you can create a self-signed certificate for this post usingopenssl x509 -in sample.pem -out new_github.cerand add this certificate to an S3 bucket.

-
GitHub Enterprise Cloud – If you choose this option, specify the GitHub host URL and GitHub organization name. Configure your Secrets Manager secret with the authentication credentials in the form of an OAuth2 access token of the GitHub enterprise owner. The Oauth2 token scope should be authorized for
- For Virtual Private Cloud (VPC), choose the default option (No VPC).
- For IAM role, choose Create a new role (recommended) and enter a role name.
Whenever you modify the Secrets Manager secret, make sure you also modify the IAM role, because it requires permission to access your secret to authenticate your GitHub account. For more information on the required permissions to include in the IAM role, see IAM roles for data sources. - Choose Next.

On the Configure sync settings page, you provide details about the sync scope and run schedule. - For Select repositories to crawl, select Select repositories to configure a specific list.
- Choose the repository
kendra-githubconnector-demothat you created earlier. - Optionally, you can adjust the crawl mode. The GitHub connector supports the two modes:
- Full crawl mode – It crawls the entire GitHub organization as configured whenever there is a data source sync. By default, the connector runs in this mode.
- Change log mode – It crawls the specified changed GitHub content (added, deleted, modified, permission changes) of the organization whenever there is a data source sync.
- Optionally, you can filter on the specific content types to index, and configure inclusion and exclusion filters on the file name, type, and path.

- Under Sync run schedule, for Frequency, choose Run on demand.
- Choose Next.

- In the Set fields mapping section, define the mappings between GitHub fields to Amazon Kendra field names.
You can configure for each content type and enable these GitHub fields as facets to further refine your search results. For this post, we use the default options. - Choose Next.

- On the Review and create page, review your options for the GitHub data source.
- Choose Add data source.
- After the data source is created, choose Sync now to index the data from GitHub.
Search indexed content
After about 10 minutes, the data source sync is complete and the GitHub content is ingested into the index. The GitHub connector crawls the following entities:
- Repositories on GitHub Enterprise Cloud:
- Repository with its description
- Code and their branches with folders and subfolders
- Issues and pull request files for public repositories
- Issues and pull request comments and their replies for public and private repositories
- Issues and pull request comment attachments and their replies’ attachments for public repositories
- Repositories on GitHub Enterprise Server:
- Repository with its description
- Code and their branches with folders and subfolders
- Issues and pull request comments and their replies for public, private, and internal repositories
Now you can test some queries on the Amazon Kendra Search console.
- Choose Search indexed content.
- Enter the sample text
How to check the status of the index creation?

- Run another query and enter the sample text
What are most popular usecases for AWS Lambda?

Amazon Kendra accurately surfaces relevant information based on the content indexed from the GitHub repositories. Access control to all the information is still enforced by the original repository.
Clean up
To avoid incurring unnecessary charges, clean up the resources you created for testing this connector.
- Delete the Amazon Kendra index if you created one specifically for testing this solution.
- Delete the GitHub connector data source if you added a new data source to an existing index.
- Delete the content you added for your GitHub account.
Conclusion
In this post, we covered the process of setting up the new Amazon Kendra connector for GitHub. Organizations can empower their software developers by providing secure and intelligent search of content spread across many different GitHub repositories.
This post illustrates the basic connector capabilities. You can also customize the search by enabling facets based on GitHub fields and map to Amazon Kendra index fields. With the GitHub connector, you can control access to the data because it can crawl orgname-reponame and set a group as the principle and collaborators of the repository as members of the group. Furthermore, Amazon Kendra provides features such as Custom Document Enrichment and Experience Builder to enhance the search experience.
For more details about Amazon Kendra, refer to the Amazon Kendra Developer Guide.
About the Authors
 Manjula Nagineni is a Solutions Architect with AWS based in New York. She works with major Financial service institutions, architecting, and modernizing their large-scale applications while adopting AWS cloud services. She is passionate about designing big data workloads cloud-natively. She has over 20 years of IT experience in Software Development, Analytics and Architecture across multiple domains such as finance, manufacturing and telecom.
Manjula Nagineni is a Solutions Architect with AWS based in New York. She works with major Financial service institutions, architecting, and modernizing their large-scale applications while adopting AWS cloud services. She is passionate about designing big data workloads cloud-natively. She has over 20 years of IT experience in Software Development, Analytics and Architecture across multiple domains such as finance, manufacturing and telecom.
 Arjun Agrawal is Software Development Engineer at AWS Kendra.
Arjun Agrawal is Software Development Engineer at AWS Kendra.