Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models.
Although Studio provides all the tools you need to take your models from experimentation to production, you need a robust and secure model deployment process. This process must fulfill your organization’s operational and security requirements.
Amazon SageMaker and Studio provide a wide range of specialized functionality for building highly secure, scalable, and flexible MLOps platforms to cover your model deployment use cases and requirements. Three SageMaker services, SageMaker Pipelines, SageMaker Projects, and SageMaker Model Registry, build a foundation to implement enterprise-grade secure multi-account model deployment workflow.
In combination with other AWS services, such as Amazon Virtual Private Cloud (Amazon VPC), AWS CloudFormation, and AWS Identity and Access Management (IAM), SageMaker MLOps can deliver solutions for the most demanding security and governance requirements.
Using a multi-account data science environment to meet security, reliability, and operational needs is a good DevOps practice. A multi-account strategy is paramount to achieve strong workload and data isolation, support multiple unrelated teams and projects, ensure fine-grained security and compliance control, facilitate billing, and create cost transparency.
In this two-part post, we offer guidance for using AWS services and SageMaker functionalities, and recommend practices for implementing a production-grade ML platform and secure, automated, multi-account model deployment workflows.
Such ML platforms and workflows can fulfill stringent security requirements, even for regulated industries such as financial services. For example, customers in regulated industries often don’t allow any internet access in ML environments. They often use only VPC endpoints for AWS services. They implement end-to-end data encryption in transit and at rest, and enforce workload isolation for individual teams in a line of business in multi-account organizational structures.
Part 1 of this series focuses on providing a solution architecture overview, in which we explain the security controls employed and how they are implemented. We also look at MLOps automation workflows with SageMaker projects and Pipelines.
In Part 2, we walk through deploying the solution with hands-on SageMaker notebooks.
This is Part 1 in a two-part series on secure multi-account deployment on Amazon SageMaker
|
Solution overview
The post Multi-account model deployment with Amazon SageMaker Pipelines shows a conceptual setup of a multi-account MLOps environment based on Pipelines and SageMaker projects.
The solution presented in this post is built for an actual use case for an AWS customer in the financial services industry. It focuses on the security, automation, and governance aspects of multi-account ML environments. It provides a fully automated provisioning of Studio into your private VPC, subnets and security groups using CloudFormation templates, and stack sets. Compared to the previous post, this solution implements network traffic and access controls with VPC endpoints, security groups, and fine-grained permissions with designated IAM roles. To reflect the real-life ML environment requirements, the solution enforces end-to-end data encryption at rest and in transit.
The following diagram shows the overview of the solution architecture and the deployed components.
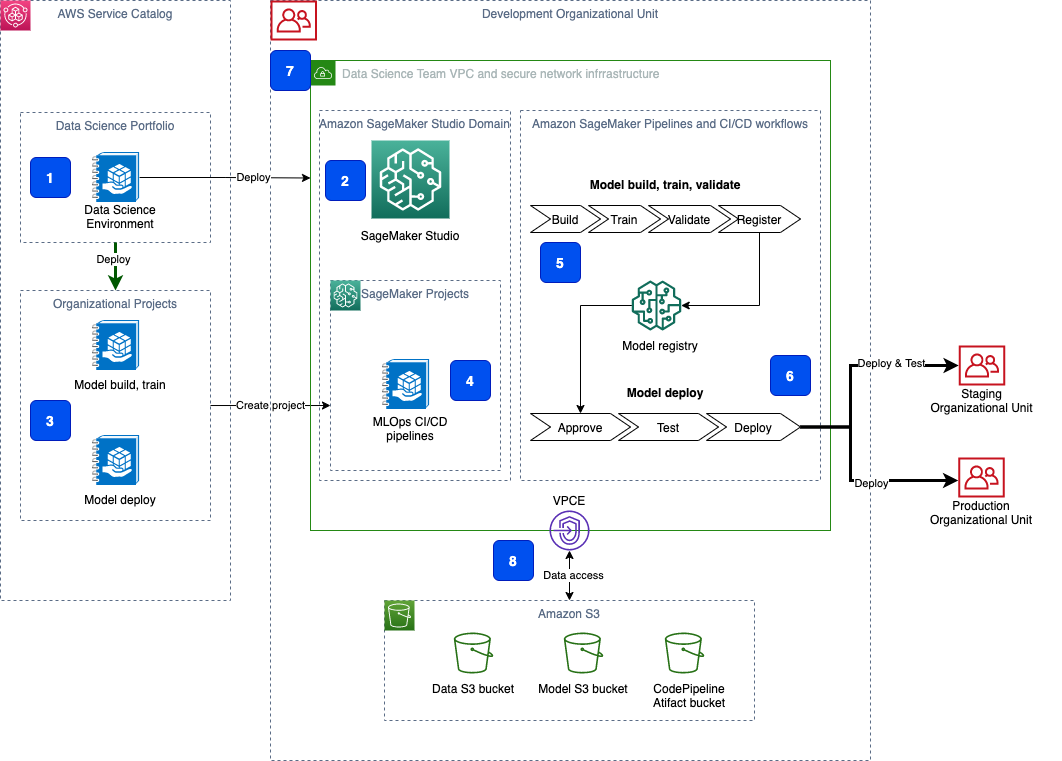
Let’s look at each group of components in more detail.
Component 1: AWS Service Catalog
The end-to-end deployment of the data science environment is delivered as an AWS Service Catalog self-provisioned product. One of the main advantages of using AWS Service Catalog for self-provisioning is that authorized users can configure and deploy available products and AWS resources on their own, without needing full privileges or access to AWS services. The deployment of all AWS Service Catalog products happens under a specified service role with the defined set of permissions, which are unrelated to the user’s permissions.
Component 2: Studio domain
The Data Science Environment product in the AWS Service Catalog creates a Studio domain. A Studio domain consists of a list of authorized users, configuration settings, and an Amazon Elastic File System (Amazon EFS) volume. The Amazon EFS volume contains data for the users, including notebooks, resources, and artifacts.
Components 3 and 4: SageMaker MLOps project templates
The solution delivers the customized versions of SageMaker MLOps project templates. Each MLOps template provides an automated model building and deployment pipeline using continuous integration and continuous delivery (CI/CD). The delivered templates are configured for the secure multi-account model deployment and are fully integrated in the provisioned data science environment. The project templates are provisioned in Studio via AWS Service Catalog. The templates include the seed code repository with Studio notebooks, which implements a secure setup of SageMaker workloads such as processing, training jobs, and pipelines.
Components 5 and 6: CI/CD workflows
The MLOps projects implement CI/CD using Pipelines and AWS CodePipeline, AWS CodeCommit, and AWS CodeBuild. SageMaker project templates also support a CI/CD workflow using Jenkins and GitHub as the source repository.
Pipelines is responsible for orchestrating workflows across each step of the ML process and task automation, including data loading, data transformation, training, tuning and validation, and deployment. Each model is tracked via SageMaker Model Registry, which stores the model metadata, such as training and validation metrics and data lineage, and retains model versions and the approval status of the model.
CodePipeline deploys the model to the designated target accounts with staging and production environments. The necessary resources are pre-created by CloudFormation templates during infrastructure creation.
This solution supports secure multi-account model deployment using AWS Organizations or via simple target account lists.
Component 7: Secure infrastructure
The Studio domain is deployed in a dedicated VPC. Each elastic network interface used by a SageMaker domain or workload is created within a private dedicated subnet and attached to the specified security groups. The data science environment VPC can be configured with internet access via an optional NAT gateway. You can also run this VPC in internet-free mode without any inbound or outbound internet access.
All access to the AWS public services is routed via AWS PrivateLink. Traffic between your VPC and the AWS services doesn’t leave the Amazon network and isn’t exposed to the public internet.
Component 8: Data security
All data in the data science environment, which is stored in Amazon Simple Storage Service (Amazon S3) buckets and Amazon Elastic Block Store (Amazon EBS) and EFS volumes, is encrypted at rest using customer managed CMKs. All data transfer between platform components, API calls, and inter-container communication is protected using the Transport Layer Security (TLS 1.2) protocol.
Data access from the Studio notebooks or any SageMaker workload to the environment’s S3 buckets is governed by the combination of the S3 bucket and user policies and S3 VPC endpoint policy.
Multi-account structure
With the goal of illustrating best practices, this solution implements the following three account groups:
- Development – This account is used by data scientists and ML engineers to perform experimentation and development. Data science tools such as Studio are used in the development account. S3 buckets with data and models, code repositories, and CI/CD pipelines are hosted in this account. Models are built, trained, validated, and registered in the model repository in this account.
- Testing/staging/UAT – Validated and approved models are first deployed to the staging account, where the automated unit and integration tests are run. Data scientists and ML engineers have read-only access to this account.
- Production – Fully tested and approved models from the staging accounts are deployed to the production account for both online and batch inference.
Depending on your specific security and governance requirements and your development organization, for the production setup, we recommend using two additional account groups:
- Shared services – This account hosts common resources like team code repositories, CI/CD pipelines for MLOps workflows, Docker image repositories, service catalog portfolios, model registries, and library package repositories.
- Data management – A dedicated AWS account to store and manage all data for the ML process. We recommend implementing strong data security and governance practices using AWS Data Lake and AWS Lake Formation.
Each of these account groups can have multiple AWS accounts and environments for developing and testing services and storing different types of data.
Environment layers
In the following sections, we look at the whole data science environment in terms of layers:
- Network and security infrastructure
- IAM roles and cross-account permission setup
- Application stack consisting of Studio and SageMaker MLOps projects
In Part 2 of this post, you deploy the solution into your AWS account for further experimentation.
Secure infrastructure
We use AWS foundational services such as VPC, security groups, subnets, and NAT gateways to create the secure infrastructure for the data science environment. The following diagram shows the deployment architecture for the solution.
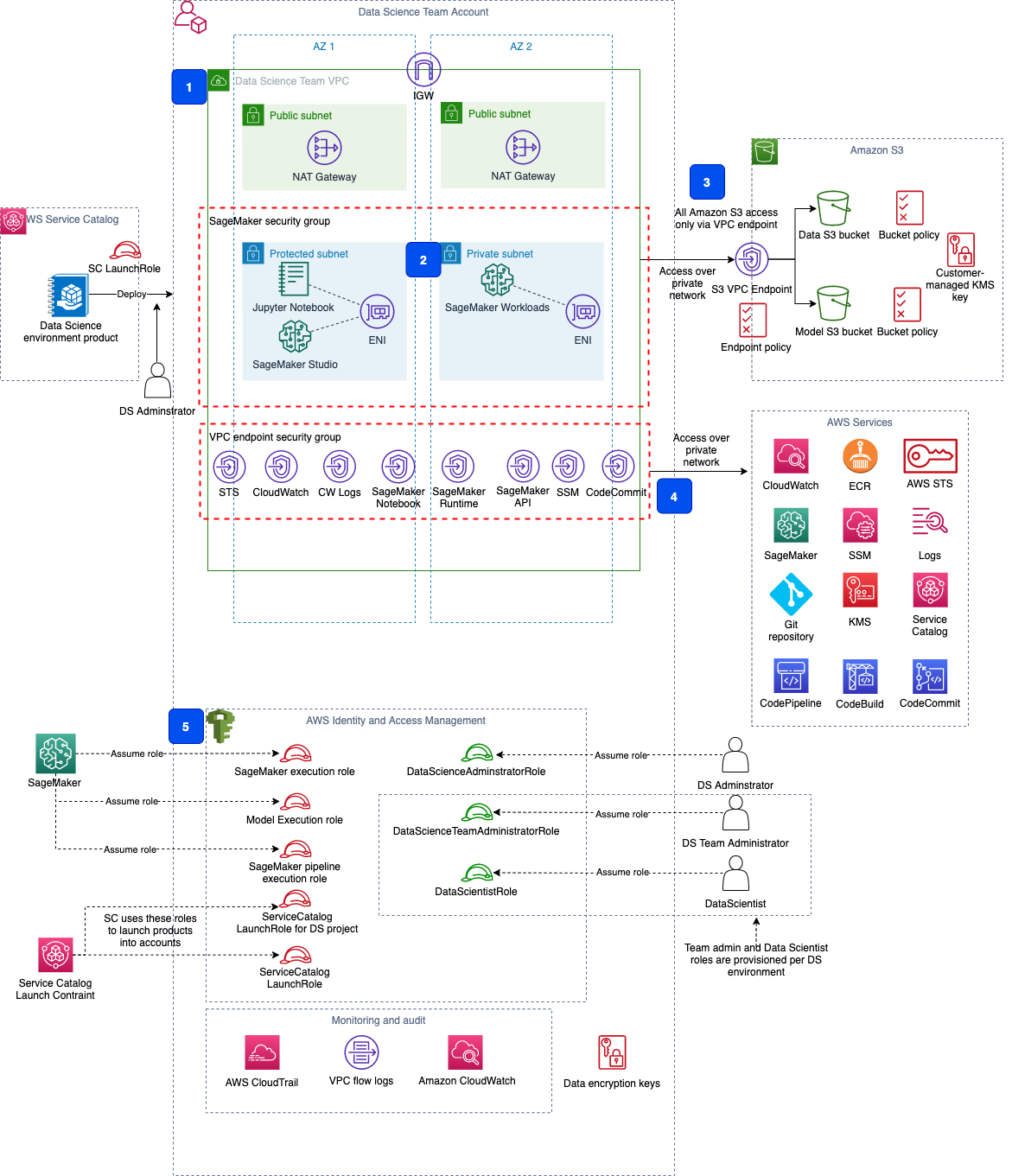
VPC, subnets, routes, and internet access
Our Studio domain is deployed into a dedicated data science VPC using VPC Only mode (Step 1 in the preceding architecture). In this mode, you use your own control flow for the internet traffic, like a NAT gateway or AWS Network Firewall. You can also create an internet-free VPC for your highly secure workloads. Any SageMaker workload launched in the VPC creates an elastic network interface in the specified subnet. You can apply all available layers of security controls—security groups, network ACLs, VPC endpoints, AWS PrivateLink, or Network Firewall endpoints—to the internal network and internet traffic to exercise fine-grained control of network access in Studio. For a detailed description of network configurations and security controls, refer to Securing Amazon SageMaker Studio connectivity using a private VPC. If you must control ingress and egress network traffic or apply any filtering rules, you can use Network Firewall as described in Securing Amazon SageMaker Studio internet traffic using AWS Network Firewall.
All SageMaker workloads, like Studio notebooks, processing or training jobs, and inference endpoints, are placed in the private subnets within the dedicated security group (2). This security group doesn’t allow any ingress from any network interface outside the group except for intra-group communications.
VPC endpoints
All access to Amazon S3 is routed via the gateway-type S3 VPC endpoint (3). You control access to the resources behind a VPC endpoint with a VPC endpoint policy. The combination of the VPC endpoint policy and the S3 bucket policy ensures that only specified buckets can be accessed, and these buckets can be accessed only via the designated VPC endpoints. The solution provisions two buckets: Data and Models. You can extend the CloudFormation templates to accommodate your data storage requirements, create additional S3 buckets, or tighten the data access permissions.
Studio and Studio notebooks communicate with various AWS services, such as the SageMaker backend and APIs, Amazon SageMaker Runtime, AWS Security Token Service (AWS STS), Amazon CloudWatch, AWS Key Management Service (AWS KMS), and others.
The solution uses a private connection over interface-type VPC endpoints (4) to access these AWS services. All VPC endpoints are placed in the dedicated security group to control the inbound and outbound network access. You can find a list with the recommended VPC endpoints to be set up for Studio in the following AWS technical guide.
IAM roles and preventive security controls
The solution uses IAM to set up personas and service execution roles (5). You can assign fine-grained permissions policies on the least privilege principle to various SageMaker execution roles, used to run different workloads, such as processing or training jobs, pipelines, or inference. You can implement preventive security controls using SageMaker-specific IAM condition keys. For example, the solution enforces usage of VPC isolation with private subnets and usage of the security groups for SageMaker notebook instances, processing, training, and tuning jobs, as well as for models for the SageMaker execution role:
{
"Action": [
"sagemaker:CreateNotebookInstance",
"sagemaker:CreateHyperParameterTuningJob",
"sagemaker:CreateProcessingJob",
"sagemaker:CreateTrainingJob",
"sagemaker:CreateModel"
],
"Resource": "*",
"Effect": "Deny",
"Condition": {
"Null": {
"sagemaker:VpcSubnets": "true",
"sagemaker:VpcSecurityGroupIds": "true"
}
}
}For a detailed discussion of the security controls and best practices, refer to Building secure machine learning environments with Amazon SageMaker.
Cross-account permission and infrastructure setup
When using a multi-account setup for your data science platform, you must focus on setting up and configuring IAM roles, resource policies, and cross-account trust and permissions polices with special attention to the following topics:
- How do you set up access to the resources in one account from authorized and authenticated roles and users from another accounts?
- What roles in one (target) account must be assumed by a role in another (source) account to perform a specific action in the target account?
- Does the assumed role in the target account have a trust policy for a role in the source account, and does the role in the source account have
iam:AssumeRolepermission in its permissions policy for the principal in the target account? For more information, see How to use trust policies with IAM roles. - Do your AWS CloudFormation deployment roles have
iam:PassRolepermission for the execution roles they assign to the created resources? - How do you configure access control and resource isolation for teams or groups within Studio? For an overview and recipes for the implementation, see Configuring Amazon SageMaker Studio for teams and groups with complete resource isolation.
The solution implements the following IAM roles in its multi-account setup, as shown in the diagram.

User persona IAM roles and various execution roles are created in the development account as we run Studio and perform development work there. We must create the following IAM roles in the staging and production accounts:
- Stack set execution roles – Used to deploy various resources into target accounts during the initial environment provision and for multi-account CI/CD MLOps workflows
- Model execution roles – Assumed by SageMaker to access model artifacts and the Docker image for deployment on ML compute instances (SageMaker inference)
These roles are assumed by the roles in the development account.
Configure permissions for multi-account model deployment
In this section, we look closer at the permission setup for multi-account model deployment.
First, we must understand how the multi-account CI/CD model pipeline deploys the model to SageMaker endpoints in the target accounts. The following diagram shows the model deployment process.
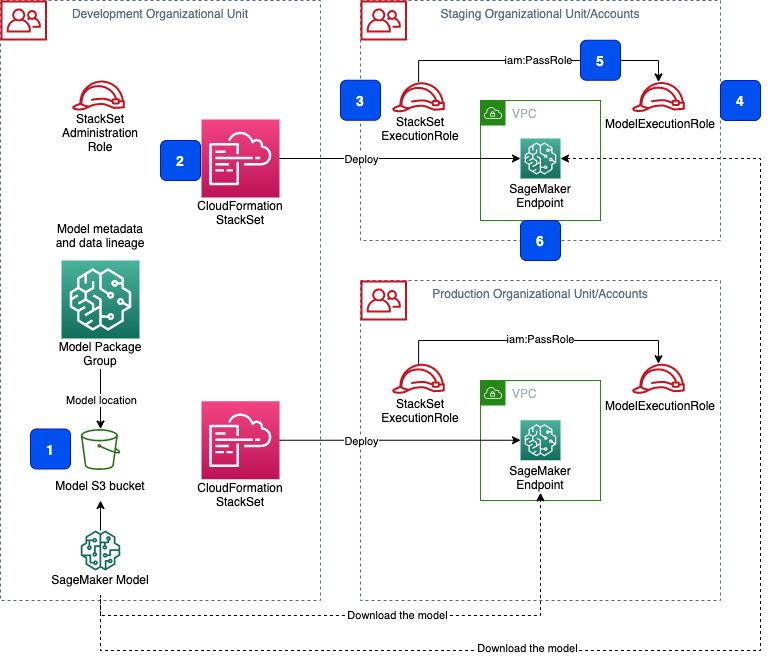
After model training and validation, the model is registered in the model registry. The model registry stores the model metadata, and all model artifacts are stored in an S3 bucket (Step 1 in the preceding diagram). The CI/CD pipeline uses CloudFormation stack sets (2) to deploy the model in the target accounts. The CloudFormation service assumes the role StackSetExecutionRole (3) in the target account to perform the deployment. SageMaker also assumes the role ModelExecutionRole (4) to access the model metadata and download the model artifacts from the S3 bucket. The StackSetExecutionRole role must have iam:PassRole permission (5) for ModelExecutionRole to be able to pass the role successfully at stack provisioning time. Finally, the model is deployed to a SageMaker endpoint (6).
For a successful deployment, ModelExecutionRole needs access to the model, which is saved in an S3 bucket, and to the corresponding AWS KMS encryption keys in the development account, because the data in the S3 bucket is encrypted.
Both the S3 bucket and AWS KMS key resource policies have an explicit deny statement if any access request doesn’t arrive via a designated VPC endpoint (following is AWS KMS key policy example):
- Sid: DenyNoVPC
Effect: Deny
Principal: '*'
Action:
- kms:Encrypt
- kms:Decrypt
- kms:ReEncrypt*
- kms:GenerateDataKey*
- kms:DescribeKey
Resource: '*'
Condition:
StringNotEquals:
'aws:sourceVpce': !Ref VPCEndpointKMSIdTo access the S3 bucket and AWS KMS key with ModelExecutionRole, the following conditions must be met:
ModelExecutionRolemust have permissions to access the S3 bucket and AWS KMS key in the development account- Both S3 bucket and AWS KMS key policies must allow cross-account access from
ModelExecutionRolein the corresponding target account - The S3 bucket and AWS KMS key must be accessed only via a designated VPC endpoint in the target account
- The VPC endpoint ID must be explicitly allowed in both S3 bucket and AWS KMS key policies in the
Conditionstatement
The following diagram shows the infrastructure and IAM configuration for a development, staging, and production account that fulfills these requirements.
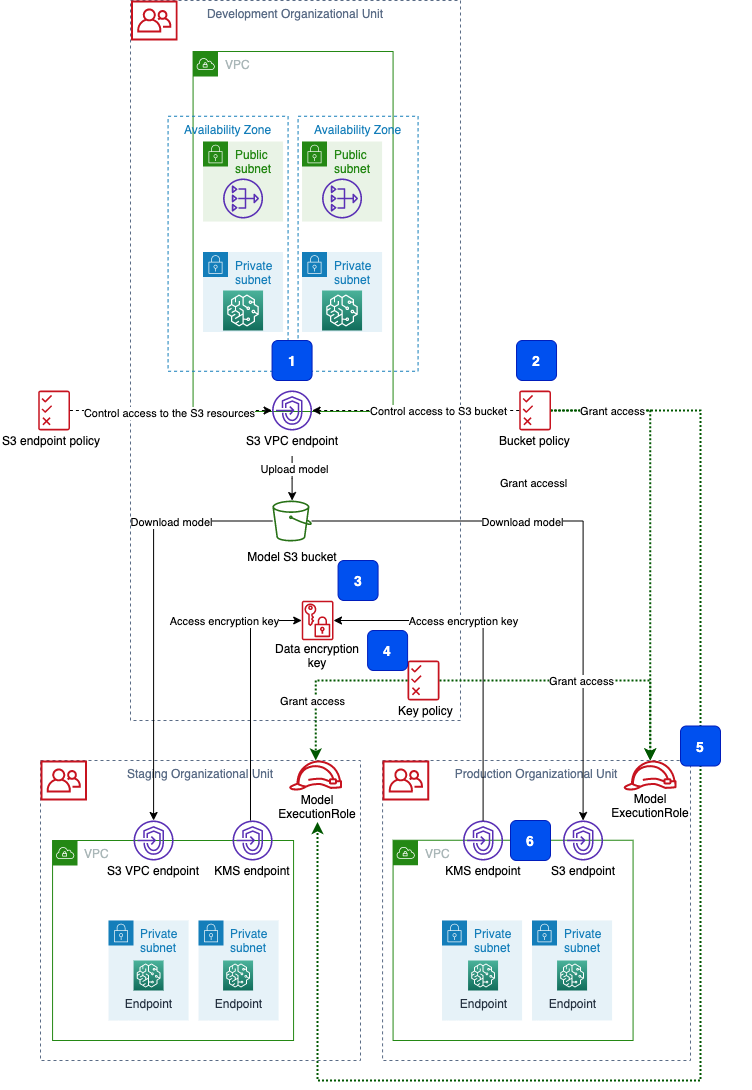
All access to the model artifacts is made via the S3 VPC endpoint (Step 1 in the preceding architecture). This VPC endpoint allows access to the model and data in your S3 buckets. The bucket policy (2) for the bucket where the models are stored grants access to the ModelExecutionRole principals (5) in each of the target accounts:
"Sid": "AllowCrossAccount",
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::<staging-account>:role/SageMakerModelExecutionRole",
"arn:aws:iam::<prod-account>:role/SageMakerModelExecutionRole",
"arn:aws:iam::<dev-account>:root"
]
}We apply the same setup for the data encryption key (3), whose policy (4) grants access to the principals in the target accounts.
SageMaker model-hosting endpoints are placed in the VPC (6) in each of the target accounts. Any access to S3 buckets and AWS KMS keys is made via the corresponding VPC endpoints. The IDs of these VPC endpoints are added to the Condition statement of the bucket and the AWS KMS key’s resource policies:
"Sid": "DenyNoVPC",
"Effect": "Deny",
"Principal": "*",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket",
"s3:GetBucketAcl",
"s3:GetObjectAcl",
"s3:PutBucketAcl",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::sm-mlops-dev-us-east-1-models/*",
"arn:aws:s3:::sm-mlops-dev-us-east-1-models"
],
"Condition": {
"StringNotEquals": {
"aws:sourceVpce": [
"vpce-0b82e29a828790da2",
"vpce-07ef65869ca950e14",
"vpce-03d9ed0a1ba396ff5"
]
}
}SageMaker MLOps projects: Automation pipelines
This solution delivers two MLOps projects as SageMaker project templates:
- Model build, train, and validate pipeline
- Multi-account model deploy pipeline
These projects are fully functional examples that are integrated with the solution infrastructure and multi-layer security controls such as VPC, subnets, security groups, AWS account boundaries, and the dedicated IAM execution roles.
You can find a detailed description of the SageMaker MLOps projects in Building, automating, managing, and scaling ML workflows using Amazon SageMaker Pipelines.
MLOps project template to build, train, validate model
This project is based on the SageMaker project template but has been adapted for this particular solution infrastructure and security controls. The following diagram shows the functional setup of the CI/CD pipeline.
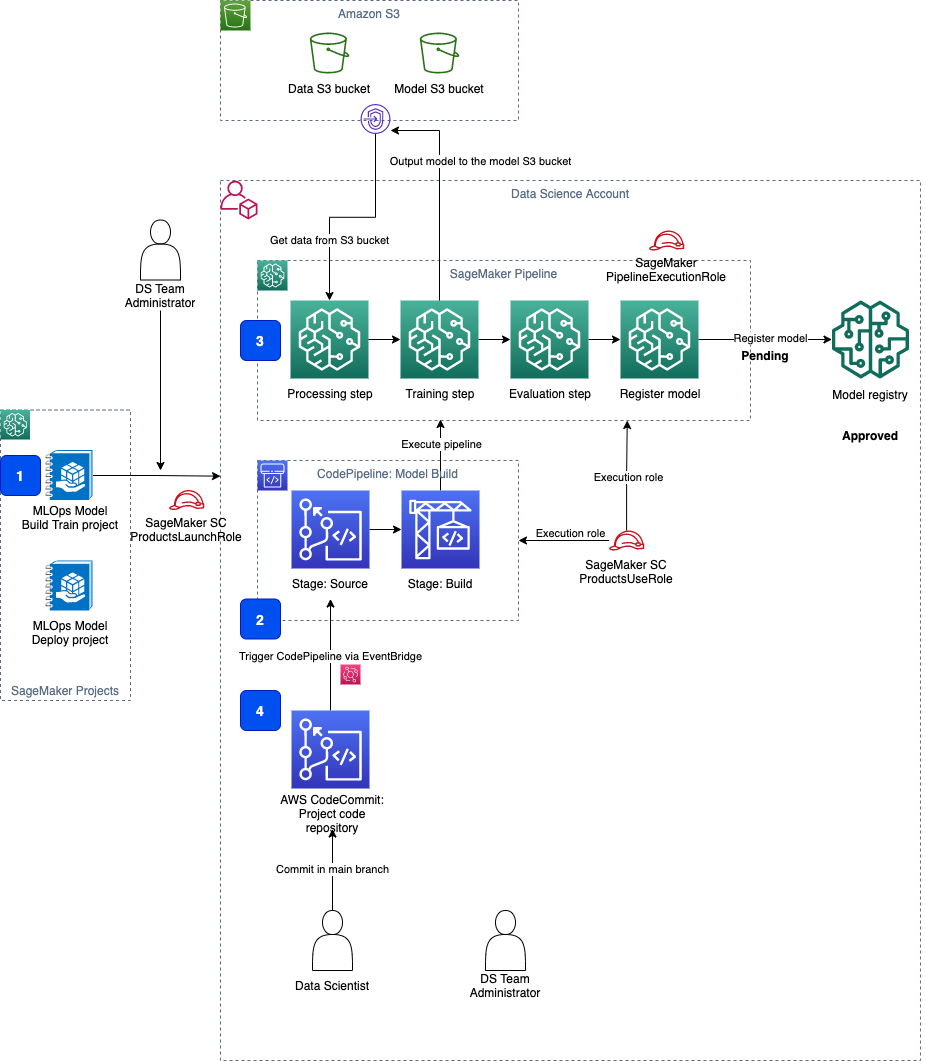
The project creates the following resources comprising the MLOps pipeline:
- An MLOps template, made available through SageMaker projects and provided via an AWS Service Catalog portfolio.
- A CodePipeline pipeline with two stages:
Sourceto get the source code of the ML pipeline, andBuildto build and run the pipeline. - A pipeline to implement a repeatable DAG workflow with individual steps for processing, training, validation, and model registration.
- A seed code repository in CodeCommit.
The seed code repository contains code to create a multi-step model building pipeline that includes data processing, model training, model evaluation, and conditional model registration (depending on model accuracy) steps. The pipeline implementation in the pipeline.py file trains a linear regression model using the XGBoost algorithm on the well-known UCI Abalone dataset. This repository also includes a build specification file, used by CodePipeline and CodeBuild to run the pipeline automatically.
MLOps project template for multi-account model deployment
This project is based on the SageMaker MLOps template for model deployment, but implements secure multi-account deployment from SageMaker Model Registry to SageMaker hosted endpoints for real-time inference in the staging and production accounts.
The following diagram shows the functional components of the project.
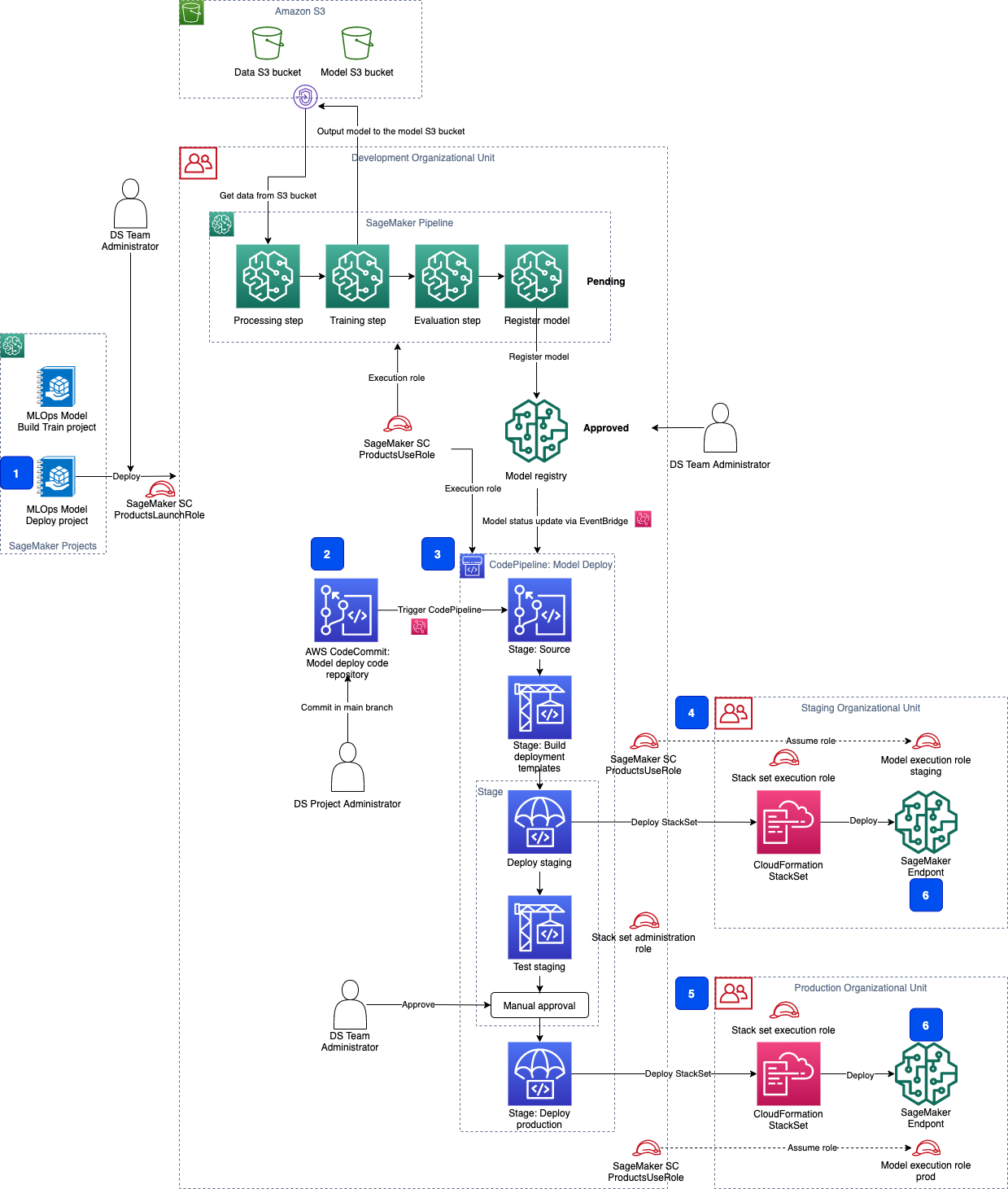
The components are as follows:
- The MLOps project template, which is deployable as a SageMaker project in Studio.
- A CodeCommit repository with seed code.
- The model deployment multi-stage CI/CD CodePipeline pipeline.
- A staging AWS account or accounts where the model is deployed and tested.
- A production AWS account or accounts where the model is deployed for production serving.
- SageMaker endpoints with the approved model hosted in your private VPC.
You can use the delivered seed code to implement your own customized model deployment pipelines with additional tests or approval steps.
Multi-account ML development best practices
In addition to the already discussed MLOps approaches, security controls, and infrastructure setup, the following resources provide a detailed description and overview of the ML development and deployment best practices:
- Build a Secure Enterprise Machine Learning Platform on AWS – Gives a fundamental overview of all parts of an enterprise ML platform
- Building secure machine learning environments with Amazon SageMaker – Delivers a hands-on workshop on building secure environments, and you can use the associated code on GitHub.
- Setting up secure, well-governed machine learning environments on AWS – Describes a common operational model and organizational unit setup patterns for creating secure ML platforms.
Conclusion
In this post, we presented the main building blocks and patterns for implementing a multi-account, secure, and governed ML environment. In Part 2 of this series, you deploy the solution from the source code GitHub repository into your account and experiment with the hands-on SageMaker notebooks.
About the Author
 Yevgeniy Ilyin is a Solutions Architect at AWS. He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to .NET, Java, and Python. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.
Yevgeniy Ilyin is a Solutions Architect at AWS. He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to .NET, Java, and Python. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.