This is the second post in a two-part series in which I propose a practical guide for organizations so you can assess the quality of text summarization models for your domain.
For an introduction to text summarization, an overview of this tutorial, and the steps to create a baseline for our project (also referred to as section 1), refer back to the first post.
This post is divided into three sections:
- Section 2: Generate summaries with a zero-shot model
- Section 3: Train a summarization model
- Section 4: Evaluate the trained model
Section 2: Generate summaries with a zero-shot model
In this post, we use the concept of zero-shot learning (ZSL), which means we use a model that has been trained to summarize text but hasn’t seen any examples of the arXiv dataset. It’s a bit like trying to paint a portrait when all you have been doing in your life is landscape painting. You know how to paint, but you might not be too familiar with the intricacies of portrait painting.
For this section, we use the following notebook.
Why zero-shot learning?
ZSL has become popular over the past years because it allows you to use state-of-the-art NLP models with no training. And their performance is sometimes quite astonishing: the Big Science Research Workgroup has recently released their T0pp (pronounced “T Zero Plus Plus”) model, which has been trained specifically for researching zero-shot multitask learning. It can often outperform models six times larger on the BIG-bench benchmark, and can outperform the GPT-3 (16 times larger) on several other NLP benchmarks.
Another benefit of ZSL is that it takes just two lines of code to use it. By trying it out, we create a second baseline, which we use to quantify the gain in model performance after we fine-tune the model on our dataset.
Set up a zero-shot learning pipeline
To use ZSL models, we can use Hugging Face’s Pipeline API. This API enables us to use a text summarization model with just two lines of code. It takes care of the main processing steps in an NLP model:
- Preprocess the text into a format the model can understand.
- Pass the preprocessed inputs to the model.
- Postprocess the predictions of the model, so you can make sense of them.
It uses the summarization models that are already available on the Hugging Face model hub.
To use it, run the following code:
That’s it! The code downloads a summarization model and creates summaries locally on your machine. If you’re wondering which model it uses, you can either look it up in the source code or use the following command:
When we run this command, we see that the default model for text summarization is called sshleifer/distilbart-cnn-12-6:

We can find the model card for this model on the Hugging Face website, where we can also see that the model has been trained on two datasets: the CNN Dailymail dataset and the Extreme Summarization (XSum) dataset. It’s worth noting that this model is not familiar with the arXiv dataset and is only used to summarize texts that are similar to the ones it has been trained on (mostly news articles). The numbers 12 and 6 in the model name refer to the number of encoder layers and decoder layers, respectively. Explaining what these are is outside the scope of this tutorial, but you can read more about it in the post Introducing BART by Sam Shleifer, who created the model.
We use the default model going forward, but I encourage you to try out different pre-trained models. All the models that are suitable for summarization can be found on the Hugging Face website. To use a different model, you can specify the model name when calling the Pipeline API:
Extractive vs. abstractive summarization
We haven’t spoken yet about two possible but different approaches to text summarization: extractive vs. abstractive. Extractive summarization is the strategy of concatenating extracts taken from a text into a summary, whereas abstractive summarization involves paraphrasing the corpus using novel sentences. Most of the summarization models are based on models that generate novel text (they’re natural language generation models, like, for example, GPT-3). This means that the summarization models also generate novel text, which makes them abstractive summarization models.
Generate zero-shot summaries
Now that we know how to use it, we want to use it on our test dataset—the same dataset we used in section 1 to create the baseline. We can do that with the following loop:
We use the min_length and max_length parameters to control the summary the model generates. In this example, we set min_length to 5 because we want the title to be at least five words long. And by estimating the reference summaries (the actual titles for the research papers), we determine that 20 could be a reasonable value for max_length. But again, this is just a first attempt. When the project is in the experimentation phase, these two parameters can and should be changed to see if the model performance changes.
Additional parameters
If you’re already familiar with text generation, you might know there are many more parameters to influence the text a model generates, such as beam search, sampling, and temperature. These parameters give you more control over the text that is being generated, for example make the text more fluent and less repetitive. These techniques are not available in the Pipeline API—you can see in the source code that min_length and max_length are the only parameters that are considered. After we train and deploy our own model, however, we have access to those parameters. More on that in section 4 of this post.
Model evaluation
After we have the generated the zero-shot summaries, we can use our ROUGE function again to compare the candidate summaries with the reference summaries:
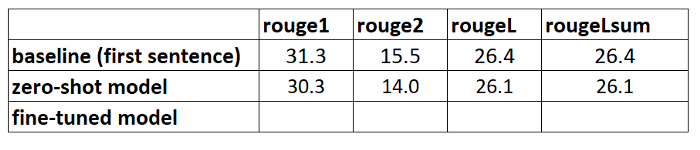
Running this calculation on the summaries that were generated with the ZSL model gives us the following results:

When we compare those with our baseline, we see that this ZSL model is actually performing worse that our simple heuristic of just taking the first sentence. Again, this is not unexpected: although this model knows how to summarize news articles, it has never seen an example of summarizing the abstract of an academic research paper.
Baseline comparison
We have now created two baselines: one using a simple heuristic and one with an ZSL model. By comparing the ROUGE scores, we see that the simple heuristic currently outperforms the deep learning model.
In the next section, we take this same deep learning model and try to improve its performance. We do so by training it on the arXiv dataset (this step is also called fine-tuning). We take advantage of the fact that it already knows how to summarize text in general. We then show it lots of examples of our arXiv dataset. Deep learning models are exceptionally good at identifying patterns in datasets after they get trained on it, so we expect the model to get better at this particular task.
Section 3: Train a summarization model
In this section, we train the model we used for zero-shot summaries in section 2 (sshleifer/distilbart-cnn-12-6) on our dataset. The idea is to teach the model what summaries for abstracts of research papers look like by showing it many examples. Over time the model should recognize the patterns in this dataset, which will allow it to create better summaries.
It’s worth noting once more that if you have labeled data, namely texts and corresponding summaries, you should use those to train a model. Only by doing so can the model learn the patterns of your specific dataset.
The complete code for the model training is in the following notebook.
Set up a training job
Because training a deep learning model would take a few weeks on a laptop, we use Amazon SageMaker training jobs instead. For more details, refer to Train a Model with Amazon SageMaker. In this post, I briefly highlight the advantage of using these training jobs, besides the fact that they allow us to use GPU compute instances.
Let’s assume we have a cluster of GPU instances we can use. In that case, we likely want to create a Docker image to run the training so that we can easily replicate the training environment on other machines. We then install the required packages and because we want to use several instances, we need to set up distributed training as well. When the training is complete, we want to quickly shut down these computers because they are costly.
All these steps are abstracted away from us when using training jobs. In fact, we can train a model in the same way as described by specifying the training parameters and then just calling one method. SageMaker takes care of the rest, including stopping the GPU instances when the training is complete so to not incur any further costs.
In addition, Hugging Face and AWS announced a partnership earlier in 2022 that makes it even easier to train Hugging Face models on SageMaker. This functionality is available through the development of Hugging Face AWS Deep Learning Containers (DLCs). These containers include Hugging Face Transformers, Tokenizers and the Datasets library, which allows us to use these resources for training and inference jobs. For a list of the available DLC images, see available Hugging Face Deep Learning Containers Images. They are maintained and regularly updated with security patches. We can find many examples of how to train Hugging Face models with these DLCs and the Hugging Face Python SDK in the following GitHub repo.
We use one of those examples as a template because it does almost everything we need for our purpose: train a summarization model on a specific dataset in a distributed manner (using more than one GPU instance).
One thing, however, we have to account for is that this example uses a dataset directly from the Hugging Face dataset hub. Because we want to provide our own custom data, we need to amend the notebook slightly.
Pass data to the training job
To account for the fact that we bring our own dataset, we need to use channels. For more information, refer to How Amazon SageMaker Provides Training Information.
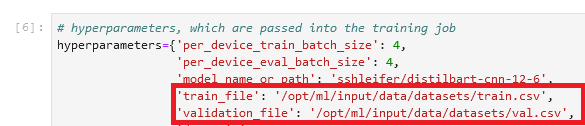
I personally find this term a bit confusing, so in my mind I always think mapping when I hear channels, because it helps me better visualize what happens. Let me explain: as we already learned, the training job spins up a cluster of Amazon Elastic Compute Cloud (Amazon EC2) instances and copies a Docker image onto it. However, our datasets are stored in Amazon Simple Storage Service (Amazon S3) and can’t be accessed by that Docker image. Instead, the training job needs to copy the data from Amazon S3 to a predefined path locally in that Docker image. The way it does that is by us telling the training job where the data resides in Amazon S3 and where on the Docker image the data should be copied to so that the training job can access it. We map the Amazon S3 location with the local path.
We set the local path in the hyperparameters section of the training job:
Then we tell the training job where the data resides in Amazon S3 when calling the fit() method, which starts the training:
![]()
Note that the folder name after /opt/ml/input/data matches the channel name (datasets). This enables the training job to copy the data from Amazon S3 to the local path.
Start the training
We’re now ready to start the training job. As mentioned before, we do so by calling the fit() method. The training job runs for about 40 minutes. You can follow the progress and see additional information on the SageMaker console.
When the training job is complete, it’s time to evaluate our newly trained model.
Section 4: Evaluate the trained model
Evaluating our trained model is very similar to what we did in section 2, where we evaluated the ZSL model. We call the model and generate candidate summaries and compare them to the reference summaries by calculating the ROUGE scores. But now, the model sits in Amazon S3 in a file called model.tar.gz (to find the exact location, you can check the training job on the console). So how do we access the model to generate summaries?
We have two options: deploy the model to a SageMaker endpoint or download it locally, similar to what we did in section 2 with the ZSL model. In this tutorial, I deploy the model to a SageMaker endpoint because it’s more convenient and by choosing a more powerful instance for the endpoint, we can shorten the inference time significantly. The GitHub repo contains a notebook that shows how to evaluate the model locally.
Deploy a model
It’s usually very easy to deploy a trained model on SageMaker (see again the following example on GitHub from Hugging Face). After the model has been trained, we can call estimator.deploy() and SageMaker does the rest for us in the background. Because in our tutorial we switch from one notebook to the next, we have to locate the training job and the associated model first, before we can deploy it:

After we retrieve the model location, we can deploy it to a SageMaker endpoint:
Deployment on SageMaker is straightforward because it uses the SageMaker Hugging Face Inference Toolkit, an open-source library for serving Transformers models on SageMaker. We normally don’t even have to provide an inference script; the toolkit takes care of that. In that case, however, the toolkit utilizes the Pipeline API again, and as we discussed in section 2, the Pipeline API doesn’t allow us to use advanced text generation techniques such as beam search and sampling. To avoid this limitation, we provide our custom inference script.
First evaluation
For the first evaluation of our newly trained model, we use the same parameters as in section 2 with the zero-shot model to generate the candidate summaries. This allows to make an apple-to-apples comparison:
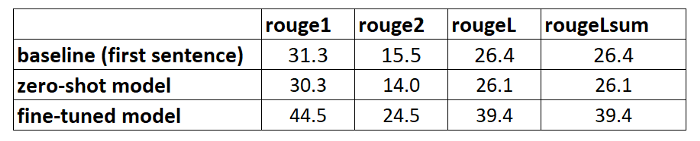
We compare the summaries generated by the model with the reference summaries:

This is encouraging! Our first attempt to train the model, without any hyperparameter tuning, has improved the ROUGE scores significantly.
Second evaluation
Now it’s time to use some more advanced techniques such as beam search and sampling to play around with the model. For a detailed explanation what each of these parameters does, refer to How to generate text: using different decoding methods for language generation with Transformers. Let’s try it with a semi-random set of values for some of these parameters:
When running our model with these parameters, we get the following scores:

That didn’t work out quite as we hoped—the ROUGE scores have actually gone down slightly. However, don’t let this discourage you from trying out different values for these parameters. In fact, this is the point where we finish with the setup phase and transition into the experimentation phase of the project.
Conclusion and next steps
We have concluded the setup for the experimentation phase. In this two-part series, we downloaded and prepared our data, created a baseline with a simple heuristic, created another baseline using zero-shot learning, and then trained our model and saw a significant increase in performance. Now it’s time to play around with every part we created in order to create even better summaries. Consider the following:
- Preprocess the data properly – For example, remove stopwords and punctuation. Don’t underestimate this part—in many data science projects, data preprocessing is one of the most important aspects (if not the most important), and data scientists typically spend most of their time with this task.
-
Try out different models – In our tutorial, we used the standard model for summarization (
sshleifer/distilbart-cnn-12-6), but many more models are available that you can use for this task. One of those might better fit your use case. - Perform hyperparameter tuning – When training the model, we used a certain set of hyperparameters (learning rate, number of epochs, and so on). These parameters aren’t set in stone—quite the opposite. You should change these parameters to understand how they affect your model performance.
- Use different parameters for text generation – We already did one round of creating summaries with different parameters to utilize beam search and sampling. Try out different values and parameters. For more information, refer to How to generate text: using different decoding methods for language generation with Transformers.
I hope you made it to the end and found this tutorial useful.
About the Author
 Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning and leads the Natural Language Processing (NLP) community within AWS. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers being successful in their AI/ML journey on AWS and has worked with organizations in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. In his spare time Heiko travels as much as possible.
Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning and leads the Natural Language Processing (NLP) community within AWS. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers being successful in their AI/ML journey on AWS and has worked with organizations in many industries, including Insurance, Financial Services, Media and Entertainment, Healthcare, Utilities, and Manufacturing. In his spare time Heiko travels as much as possible.