Posted by Neil Zeghidour, Research Scientist and Marco Tagliasacchi, Staff Research Scientist, Google Research
Audio codecs are used to efficiently compress audio to reduce either storage requirements or network bandwidth. Ideally, audio codecs should be transparent to the end user, so that the decoded audio is perceptually indistinguishable from the original and the encoding/decoding process does not introduce perceivable latency.
Over the past few years, different audio codecs have been successfully developed to meet these requirements, including Opus and Enhanced Voice Services (EVS). Opus is a versatile speech and audio codec, supporting bitrates from 6 kbps (kilobits per second) to 510 kbps, which has been widely deployed across applications ranging from video conferencing platforms, like Google Meet, to streaming services, like YouTube. EVS is the latest codec developed by the 3GPP standardization body targeting mobile telephony. Like Opus, it is a versatile codec operating at multiple bitrates, 5.9 kbps to 128 kbps. The quality of the reconstructed audio using either of these codecs is excellent at medium-to-low bitrates (12–20 kbps), but it degrades sharply when operating at very low bitrates (⪅3 kbps). While these codecs leverage expert knowledge of human perception as well as carefully engineered signal processing pipelines to maximize the efficiency of the compression algorithms, there has been recent interest in replacing these handcrafted pipelines by machine learning approaches that learn to encode audio in a data-driven manner.
Earlier this year, we released Lyra, a neural audio codec for low-bitrate speech. In “SoundStream: an End-to-End Neural Audio Codec”, we introduce a novel neural audio codec that extends those efforts by providing higher-quality audio and expanding to encode different sound types, including clean speech, noisy and reverberant speech, music, and environmental sounds. SoundStream is the first neural network codec to work on speech and music, while being able to run in real-time on a smartphone CPU. It is able to deliver state-of-the-art quality over a broad range of bitrates with a single trained model, which represents a significant advance in learnable codecs.
Learning an Audio Codec from Data
The main technical ingredient of SoundStream is a neural network, consisting of an encoder, decoder and quantizer, all of which are trained end-to-end. The encoder converts the input audio stream into a coded signal, which is compressed using the quantizer and then converted back to audio using the decoder. SoundStream leverages state-of-the-art solutions in the field of neural audio synthesis to deliver audio at high perceptual quality, by training a discriminator that computes a combination of adversarial and reconstruction loss functions that induce the reconstructed audio to sound like the uncompressed original input. Once trained, the encoder and decoder can be run on separate clients to efficiently transmit high-quality audio over a network.
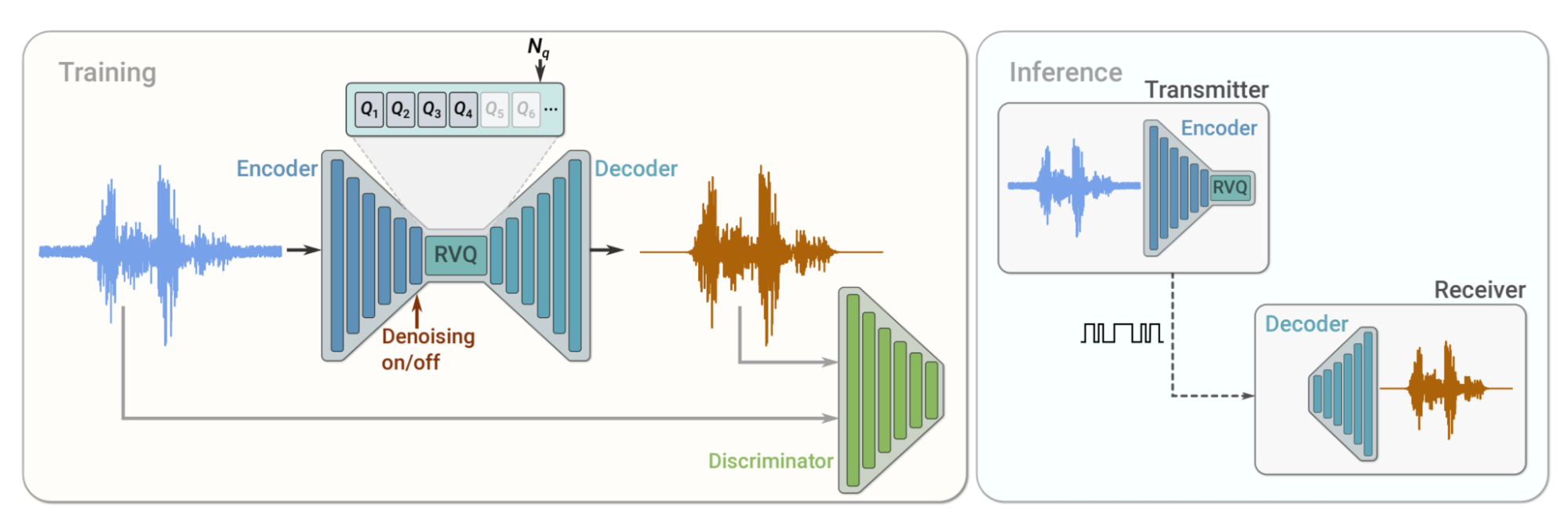 |
| SoundStream training and inference. During training, the encoder, quantizer and decoder parameters are optimized using a combination of reconstruction and adversarial losses, computed by a discriminator, which is trained to distinguish between the original input audio and the reconstructed audio. During inference, the encoder and quantizer on a transmitter client send the compressed bitstream to a receiver client that can then decode the audio signal. |
Learning a Scalable Codec with Residual Vector Quantization
The encoder of SoundStream produces vectors that can take an indefinite number of values. In order to transmit them to the receiver using a limited number of bits, it is necessary to replace them by close vectors from a finite set (called a codebook), a process known as vector quantization. This approach works well at bitrates around 1 kbps or lower, but quickly reaches its limits when using higher bitrates. For example, even at a bitrate as low as 3 kbps, and assuming the encoder produces 100 vectors per second, one would need to store a codebook with more than 1 billion vectors, which is infeasible in practice.
In SoundStream, we address this issue by proposing a new residual vector quantizer (RVQ), consisting of several layers (up to 80 in our experiments). The first layer quantizes the code vectors with moderate resolution, and each of the following layers processes the residual error from the previous one. By splitting the quantization process in several layers, the codebook size can be reduced drastically. As an example, with 100 vectors per second at 3 kbps, and using 5 quantizer layers, the codebook size goes from 1 billion to 320. Moreover, we can easily increase or decrease the bitrate by adding or removing quantizer layers, respectively.
Because network conditions can vary while transmitting audio, ideally a codec should be “scalable” so that it can change its bitrate from low to high depending on the state of the network. While most traditional codecs are scalable, previous learnable codecs need to be trained and deployed specifically for each bitrate.
To circumvent this limitation, we leverage the fact that the number of quantization layers in SoundStream controls the bitrate, and propose a new method called “quantizer dropout”. During training, we randomly drop some quantization layers to simulate a varying bitrate. This pushes the decoder to perform well at any bitrate of the incoming audio stream, and thus helps SoundStream to become “scalable” so that a single trained model can operate at any bitrate, performing as well as models trained specifically for these bitrates.
 |
| Comparison of SoundStream models (higher is better) that are trained at 18 kbps with quantizer dropout (bitrate scalable), without quantizer dropout (not bitrate scalable) and evaluated with a variable number of quantizers, or trained and evaluated at a fixed bitrate (bitrate specific). The bitrate-scalable model (a single model for all bitrates) does not lose any quality when compared to bitrate-specific models (a different model for each bitrate), thanks to quantizer dropout. |
A State-of-the-Art Audio Codec
SoundStream at 3 kbps outperforms Opus at 12 kbps and approaches the quality of EVS at 9.6 kbps, while using 3.2x–4x fewer bits. This means that encoding audio with SoundStream can provide a similar quality while using a significantly lower amount of bandwidth. Moreover, at the same bitrate, SoundStream outperforms the current version of Lyra, which is based on an autoregressive network. Unlike Lyra, which is already deployed and optimized for production usage, SoundStream is still at an experimental stage. In the future, Lyra will incorporate the components of SoundStream to provide both higher audio quality and reduced complexity.
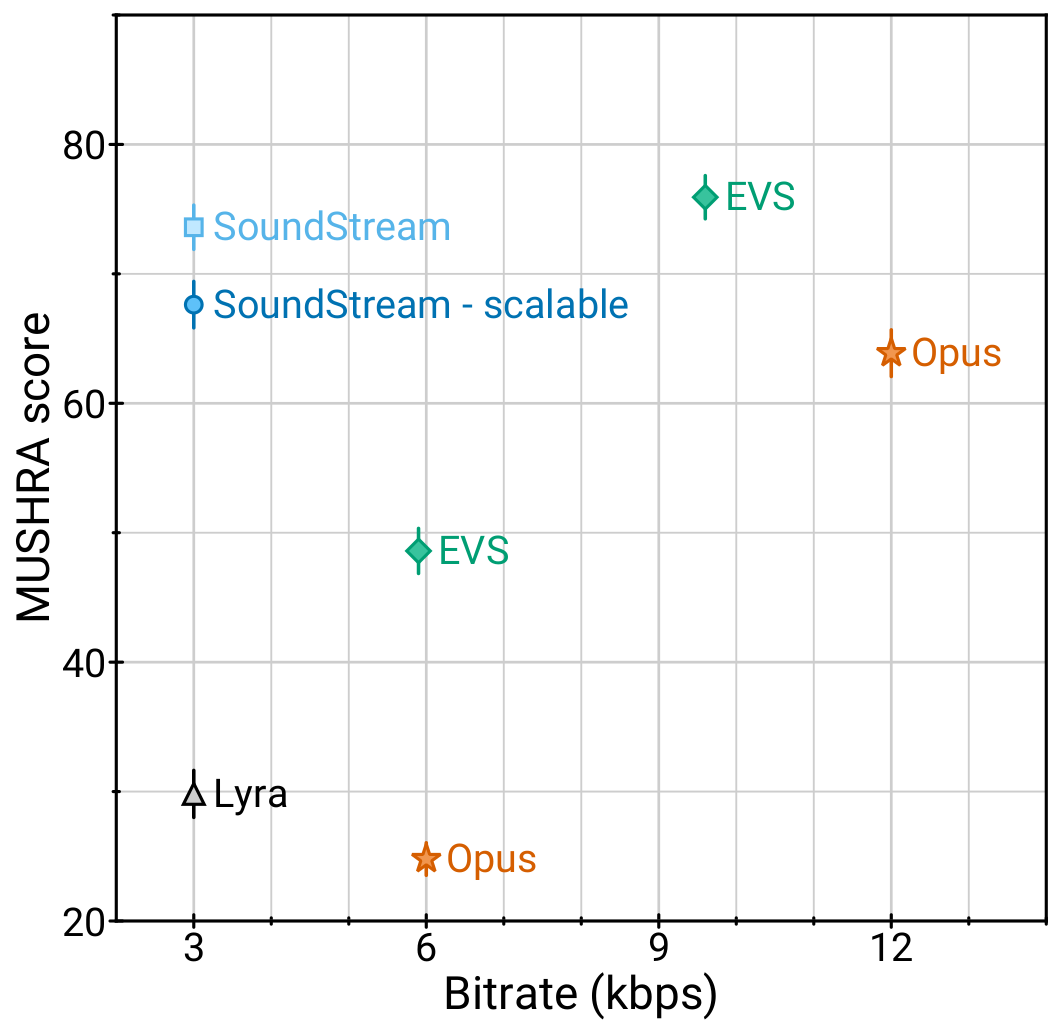 |
| SoundStream at 3kbps vs. state-of-the-art codecs. MUSHRA score is an indication of subjective quality (the higher the better). |
The demonstration of SoundStream’s performance compared to Opus, EVS, and the original Lyra codec is presented in these audio examples, a selection of which are provided below.
Speech
| Reference | |
| Lyra (3kbps) | |
| Opus (6kbps) | |
| EVS (5.9kbps) | |
| SoundStream (3kbps) |
Music
| Reference | |
| Lyra (3kbps) | |
| Opus (6kbps) | |
| EVS (5.9kbps) | |
| SoundStream (3kbps) |
Joint Audio Compression and Enhancement
In traditional audio processing pipelines, compression and enhancement (the removal of background noise) are typically performed by different modules. For example, it is possible to apply an audio enhancement algorithm at the transmitter side, before audio is compressed, or at the receiver side, after audio is decoded. In such a setup, each processing step contributes to the end-to-end latency. Conversely, we design SoundStream in such a way that compression and enhancement can be carried out jointly by the same model, without increasing the overall latency. In the following examples, we show that it is possible to combine compression with background noise suppression, by activating and deactivating denoising dynamically (no denoising for 5 seconds, denoising for 5 seconds, no denoising for 5 seconds, etc.).
| Original noisy audio | |
| Denoised output* |
| * Demonstrated by turning denoising on and off every 5 seconds. |
Conclusion
Efficient compression is necessary whenever one needs to transmit audio, whether when streaming a video, or during a conference call. SoundStream is an important step towards improving machine learning-driven audio codecs. It outperforms state-of-the-art codecs, such as Opus and EVS, can enhance audio on demand, and requires deployment of only a single scalable model, rather than many.
SoundStream will be released as a part of the next, improved version of Lyra. By integrating SoundStream with Lyra, developers can leverage the existing Lyra APIs and tools for their work, providing both flexibility and better sound quality. We will also release it as a separate TensorFlow model for experimentation.
AcknowledgmentsThe work described here was authored by Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund and Marco Tagliasacchi. We are grateful for all discussions and feedback on this work that we received from our colleagues at Google.
