
Posted by Minko Gechev, David Zats, Na Li, Ping Yu, Anusha Ramesh, and Sandeep Gupta
Page load time is one of the most important determinants of user experience on a web site. Research shows that faster page load time directly leads to increased page views, conversion, and customer satisfaction. Retail superstore Newegg has seen a 50% increase in conversions after implementing web-page prefetching to optimize page load experience.
Using TensorFlow tooling, it is now possible to use machine learning to implement a powerful solution for your website to improve page load times. In this blog post, we show an end-to-end workflow for using your site’s navigation data from Google Analytics and training a custom machine learning model that can predict the user’s next actions. You can use these predictions in an Angular app to pre-fetch candidate pages and dramatically improve user experience on your web site. Fig. 1 illustrates this side-by-side with default page load experience with no optimization compared to the greatly improved page load times with machine learning based predictive prefetching implemented on the right. Both examples are running on an emulated slow 3G network.
 |
| Fig: Comparison of un-optimized and machine learning based page loading time in a sample web application |
A high-level schematic of our solution is as follows:
 |
| Fig: Solution overview |
We use Google Cloud services (BigQuery and Dataflow) to store and preprocess the site’s Google Analytics data, then train a custom model using TensorFlow Extended (TFX) to run our model training pipeline, produce a site-specific model, and then convert it into a web-deployable TensorFlow.js format. This client-side model will be loaded in a sample Angular web app for an e-store to demonstrate how to deploy the model in a web application. Let’s take a look at these components in more detail.
Data Preparation & Ingestion
Google Analytics stores each page visit as an event, providing key aspects such as the page name, visit time, and load time. This data contains everything we need to train our model. We need to:
- Convert this data to training examples containing features and labels
- Make it available to TFX for training.
We accomplish the first by leveraging existing support for exporting the Google Analytics data to a large-scale cloud data store called BigQuery. We accomplish the latter by creating an Apache Beam pipeline that:
- Reads the data from BigQuery
- Sorts and filters the events in a session
- Walks through each session, creating examples that take properties of the current event as features and the page visit in the next event as the label
- Stores these generated examples in Google Cloud Storage so that they can be used by TFX for training.
We run our Beam pipeline in Dataflow.
In the following table, each row represents a training example:
|
cur_page |
session_index |
label |
|
page2 |
0 |
page3 |
|
page3 |
8 |
page1 |
While our training example only contains two training features (cur_page and session_index), additional features from Google Analytics can be easily added to create a richer dataset and used for training to create a more powerful model. To do so, extend the following code:
def ga_session_to_tensorflow_examples(session):
examples = []
for i in range(len(session)-1):
features = {‘cur_page’: [session[i][‘page’][‘pagePath’]],
‘label’: [session[i+1][‘page’][‘pagePath’]],
‘session_index’: [i],
# Add additional features here.
…
}
examples.append(create_tensorflow_example(features))
return examples
Model Training
Tensorflow Extended (TFX) is an end to end production scale ML platform and is used to automate the process of data validation, training at scale (using accelerators), evaluation & validation of the generated model.
To create a model within TFX, you must provide the preprocessing function and the run function. The preprocessing function defines the operations that should be performed on the data before it is passed to the main model. These include operations that involve a full pass over the data, such as vocab creation. The run function defines the main model and how it is to be trained.
Our example shows how to implement the preprocessing_fn and the run_fn to define and train a model for predicting the next page. And the TFX example pipelines demonstrate how to implement these functions for many other key use cases.
Creating a Web Deployable Model
After training our custom model, we want to deploy this model in our web application so it can be used to make live predictions when users visit our website. For this, we use TensorFlow.js, which is TensorFlow’s framework for running machine learning models directly in the browser client-side. By running this code in the browser client-side, we can reduce latency associated with server-side roundtrip traffic, reduce server-side costs, and also keep user’s data private by not having to send any session data to the server.
TFX employs the Model Rewriting Library to automate conversion between trained TensorFlow models and the TensorFlow.js format. As part of this library, we have implemented a TensorFlow.js rewriter. We simply invoke this rewriter within the run_fn to perform the desired conversion. Please see the example for more details.
Angular Application
Once we have the model we can use it within an Angular application. On each navigation, we will query the model and prefetch the resources associated with the pages that are likely to be visited in the future.
An alternative solution would be to prefetch the resources associated with all the possible future navigation paths, but this would have much higher bandwidth consumption. Using machine learning, we can predict only the pages, which are likely to be used next and reduce the number of false positives.
Depending on the specifics of the application we may want to prefetch different types of assets, for example: JavaScript, images, or data. For the purposes of this demonstration we’ll be prefetching images of products.
A challenge is how to implement the mechanism in a performant way without impacting the application load time or runtime performance. Techniques to mitigate the risks of performance regressions we can use are:
- Load the model and TensorFlow.js lazily without blocking the initial page load time
- Query the model off the main thread so we don’t drop frames in the main thread and achieve 60fps rendering experience
A web platform API that satisfies both of these constraints is the service worker. A service worker is a script that your browser runs in the background in a new thread, separate from a web page. It also allows you to plug into a request cycle and provides you with cache control.
When the user navigates across the application, we’ll post messages to the service worker with the pages they have visited. Based on the navigation history, the service worker will make predictions for future navigation and prefetch relevant product assets.
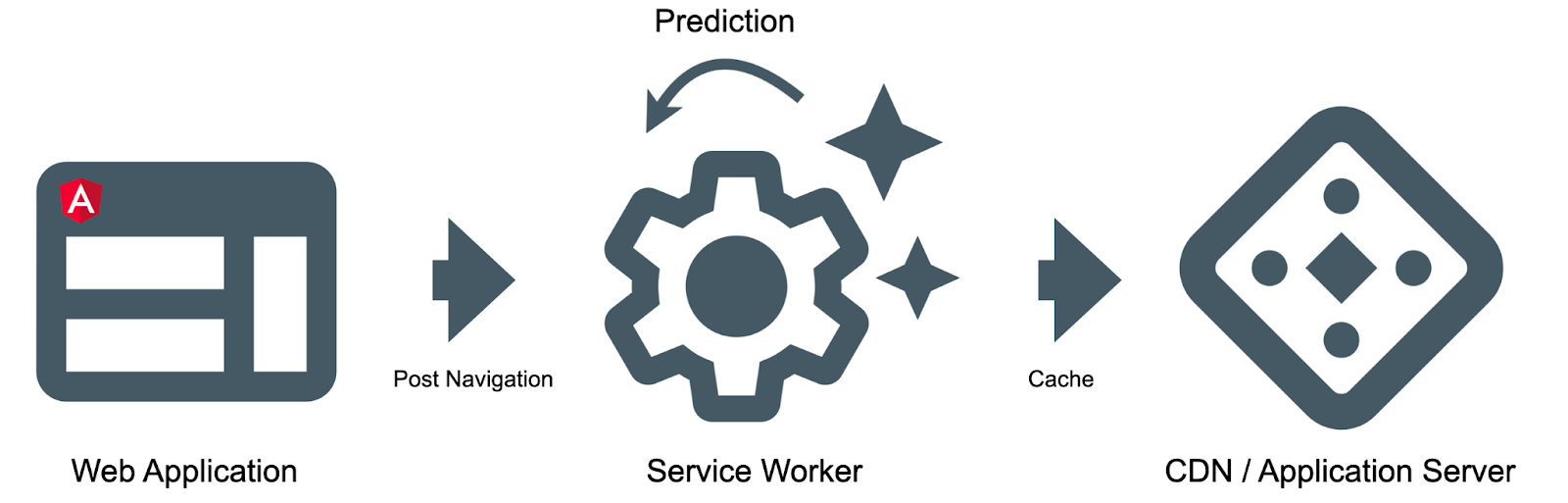
Let us look at a high-level overview of the individual moving parts.
From within the main file of our Angular application, we can load the service worker:
// main.ts
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/prefetch.worker.js', { scope: '/' });
}This snippet will download the prefetch.worker.js script and run it in the background. As the next step, we want to forward navigation events to it:
// app.component.ts
this.route.params.subscribe((routeParams) => {
if (this._serviceWorker) {
this._serviceWorker.postMessage({ page: routeParams.category });
}
});In the snippet above, we watch for changes of the parameters of the URL. On change, we forward the category of the page to the service worker.
In the implementation of the service worker we need to handle messages from the main thread, make predictions based on them, and prefetch the relevant information. On a high-level this looks as follows:
// prefetch.worker.js
addEventListener('message', ({ data }) => prefetch(data.page));
const prefetch = async (path) => {
const predictions = await predict(path);
const cache = await caches.open(ImageCache);
predictions.forEach(async ([probability, category]) => {
const products = (await getProductList(category)).map(getUrl);
[...new Set(products)].forEach(url => {
const request = new Request(url, {
mode: 'no-cors',
});
fetch(request).then(response => cache.put(request, response));
});
});
};Within the service worker we listen for messages from the main thread. When we receive a message we trigger the logic responsible for making predictions and prefetching data.
In the prefetch function we first predict, which are the pages the user could visit next. After that, we iterate over all the predictions and fetch the corresponding resources to improve the user experience in subsequent navigation.
For details you can follow the sample app in the TensorFlow.js examples repository.
Try it yourself
Check out the model training code sample which shows the TFX pipeline for training a page prefetching model as well as an Apache Beam pipeline that converts Google Analytics data to training examples, and the deployment sample showing how to deploy the TensorFlow.js model in a sample Angular app for client-side predictions.
Acknowledgements
This project wouldn’t have been possible without the incredible effort and support of Becky Chan, Deepak Aujla, Fei Dong, and Jason Mayes.