Large language models (LLMs), such as GPT-3 and PaLM, have shown impressive progress in recent years, which have been driven by scaling up models and training data sizes. Nonetheless, a long standing debate has been whether LLMs can reason symbolically (i.e., manipulating symbols based on logical rules). For example, LLMs are able to perform simple arithmetic operations when numbers are small, but struggle to perform with large numbers. This suggests that LLMs have not learned the underlying rules needed to perform these arithmetic operations.
While neural networks have powerful pattern matching capabilities, they are prone to overfitting to spurious statistical patterns in the data. This does not hinder good performance when the training data is large and diverse and the evaluation is in-distribution. However, for tasks that require rule-based reasoning (such as addition), LLMs struggle with out-of-distribution generalization as spurious correlations in the training data are often much easier to exploit than the true rule-based solution. As a result, despite significant progress in a variety of natural language processing tasks, performance on simple arithmetic tasks like addition has remained a challenge. Even with modest improvement of GPT-4 on the MATH dataset, errors are still largely due to arithmetic and calculation mistakes. Thus, an important question is whether LLMs are capable of algorithmic reasoning, which involves solving a task by applying a set of abstract rules that define the algorithm.
In “Teaching Algorithmic Reasoning via In-Context Learning”, we describe an approach that leverages in-context learning to enable algorithmic reasoning capabilities in LLMs. In-context learning refers to a model’s ability to perform a task after seeing a few examples of it within the context of the model. The task is specified to the model using a prompt, without the need for weight updates. We also present a novel algorithmic prompting technique that enables general purpose language models to achieve strong generalization on arithmetic problems that are more difficult than those seen in the prompt. Finally, we demonstrate that a model can reliably execute algorithms on out-of-distribution examples with an appropriate choice of prompting strategy.
 |
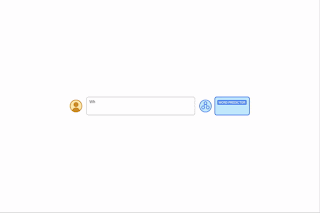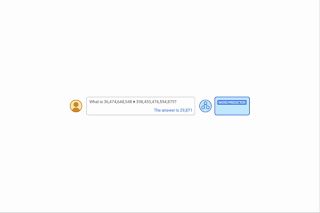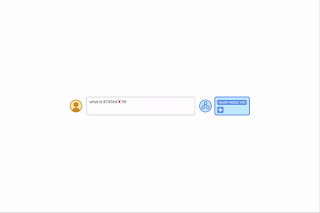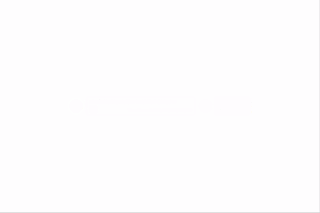
| By providing algorithmic prompts, we can teach a model the rules of arithmetic via in-context learning. In this example, the LLM (word predictor) outputs the correct answer when prompted with an easy addition question (e.g., 267+197), but fails when asked a similar addition question with longer digits. However, when the more difficult question is appended with an algorithmic prompt for addition (blue box with white + shown below the word predictor), the model is able to answer correctly. Moreover, the model is capable of simulating the multiplication algorithm (X) by composing a series of addition calculations. |
Teaching an algorithm as a skill
In order to teach a model an algorithm as a skill, we develop algorithmic prompting, which builds upon other rationale-augmented approaches (e.g., scratchpad and chain-of-thought). Algorithmic prompting extracts algorithmic reasoning abilities from LLMs, and has two notable distinctions compared to other prompting approaches: (1) it solves tasks by outputting the steps needed for an algorithmic solution, and (2) it explains each algorithmic step with sufficient detail so there is no room for misinterpretation by the LLM.
To gain intuition for algorithmic prompting, let’s consider the task of two-number addition. In a scratchpad-style prompt, we process each digit from right to left and keep track of the carry value (i.e., we add a 1 to the next digit if the current digit is greater than 9) at each step. However, the rule of carry is ambiguous after seeing only a few examples of carry values. We find that including explicit equations to describe the rule of carry helps the model focus on the relevant details and interpret the prompt more accurately. We use this insight to develop an algorithmic prompt for two-number addition, where we provide explicit equations for each step of computation and describe various indexing operations in non-ambiguous formats.
 |
| Illustration of various prompt strategies for addition. |
Using only three prompt examples of addition with answer length up to five digits, we evaluate performance on additions of up to 19 digits. Accuracy is measured over 2,000 total examples sampled uniformly over the length of the answer. As shown below, the use of algorithmic prompts maintains high accuracy for questions significantly longer than what’s seen in the prompt, which demonstrates that the model is indeed solving the task by executing an input-agnostic algorithm.
 |
| Test accuracy on addition questions of increasing length for different prompting methods. |
Leveraging algorithmic skills as tool use
To evaluate if the model can leverage algorithmic reasoning in a broader reasoning process, we evaluate performance using grade school math word problems (GSM8k). We specifically attempt to replace addition calculations from GSM8k with an algorithmic solution.
Motivated by context length limitations and possible interference between different algorithms, we explore a strategy where differently-prompted models interact with one another to solve complex tasks. In the context of GSM8k, we have one model that specializes in informal mathematical reasoning using chain-of-thought prompting, and a second model that specializes in addition using algorithmic prompting. The informal mathematical reasoning model is prompted to output specialized tokens in order to call on the addition-prompted model to perform the arithmetic steps. We extract the queries between tokens, send them to the addition-model and return the answer to the first model, after which the first model continues its output. We evaluate our approach using a difficult problem from the GSM8k (GSM8k-Hard), where we randomly select 50 addition-only questions and increase the numerical values in the questions.
 |
| An example from the GSM8k-Hard dataset. The chain-of-thought prompt is augmented with brackets to indicate when an algorithmic call should be performed. |
We find that using separate contexts and models with specialized prompts is an effective way to tackle GSM8k-Hard. Below, we observe that the performance of the model with algorithmic call for addition is 2.3x the chain-of-thought baseline. Finally, this strategy presents an example of solving complex tasks by facilitating interactions between LLMs specialized to different skills via in-context learning.
 |
| Chain-of-thought (CoT) performance on GSM8k-Hard with or without algorithmic call. |
Conclusion
We present an approach that leverages in-context learning and a novel algorithmic prompting technique to unlock algorithmic reasoning abilities in LLMs. Our results suggest that it may be possible to transform longer context into better reasoning performance by providing more detailed explanations. Thus, these findings point to the ability of using or otherwise simulating long contexts and generating more informative rationales as promising research directions.
Acknowledgements
We thank our co-authors Behnam Neyshabur, Azade Nova, Hugo Larochelle and Aaron Courville for their valuable contributions to the paper and great feedback on the blog. We thank Tom Small for creating the animations in this post. This work was done during Hattie Zhou’s internship at Google Research.